Another cool stuff from NVIDIA.
LocateAnything - high-speed visual search engine. You provide a text prompt and it instantly pinpoints that object's exact location in an image.
- 10x speedup for dense object detection
- Qwen2.5-3B + Moon-ViT
- Fast/Slow/Hybrid modes
- trained on 138M samples for UI, docs, generic grounding.
https://t.co/bEvD6pRKaR
SUPIR upscaler is outdated. ASASR- turns blurry, low-quality photos into sharp, high-res images. Prevents the fake hallucinated details.
- improves OCR
- high segmentation accuracy
- based on FLUX.1 dev
this looks sweet
https://t.co/kx4A4N1wDc
Last year, I got to collaborate on a number of serious projects at the intersection of Diffusers x optimization ⚡️
First, NONE of them were bootstrapped with any AI agents but pure domain knowledge and expertise. So, besides just feeling good, it's also very reassuring to me to know how important those two traits are.
Now, coming to the projects that I think are worth mentioning:
* `flux-fast`: Showing a combination of `torch.compile` + unscaled FP8 FA3 + no CPU-GPU sync + dynamic FP8 is great for accelerating Flux.1-*. https://t.co/Fagw9bkFPA
* `torch.compile` x Diffusers: What does it take to get the most out of `torch.compile` in Diffusers across different user workloads? https://t.co/J8bPgBFK1y
* `lora-fast`: How to hotswap LoRAs into compiled models without incurring (slow) recompilation issues? How to set it up for success? https://t.co/FhY8ATz4c0
* `zerogpu-brrr`: How to optimize a ZeroGPU HF Space with AOT + FA3 and other goodies? This helps save 💰 and improve the user experience of your ZeroGPU applications. https://t.co/DdPsS6O5Ky
Hopefully, this will make you realize there's still a LOT that you can do (preferably pairing with AI) if you're curious and deeply invested in stuff you care about.
EffectMaker by Tencent.
Wan2.2 + Qwen3-VL does zero-shot effect transfer from reference videos to images without per-effect LoRAs.
> clones complex video effects to static images
> outperforms VFX-Creator and Omni-Effect .
professional-grade cinematic effects for film post-production, game design etc.
Just point at a reference and it clones the physics.
https://t.co/XeOAoA6ekP
Autoregressive diffusion models drift for long videos? 📉
We fixed it.🚀 Speed + Stability = ✅
Meeting *Test-Time Correction (TTC)*. We stop error accumulation in its tracks without any retraining.
✅ Training-free
✅ 1 minute+ stable generation
✅ Negligible overhead
Meet MetaClaw 🦞— Just talk to your agent, it learns and evolves.
💬 Conversations become training trajectories
⚡ Models update live with hot-swapped weights
🧠 Failures generate new reusable skills
💻 No GPU cluster required
Under the hood:
🔄 Online SkillRL training
Training runs asynchronously while the model continues serving.
🐚 Skill evolution
When the agent fails, an LLM analyzes the trajectory and generates new reusable skills.
📌 Skill injection
Relevant skills are retrieved and injected into the system prompt at each step to guide behavior in real time.
Built on Kimi-2.5 via Tinker cloud LoRA
→ fine-tuning costs about $10 and requires no GPU cluster
💻 Fully open-sourced
https://t.co/RR24ZJvZ7T
Built with @openclaw and @thinkymachines
Kudos to the team @richardxp888, Jianwen Chen, @Xinyu2ML, @lillianwei423, @StephenQS0710, Zeyu Zheng, @cihangxie!
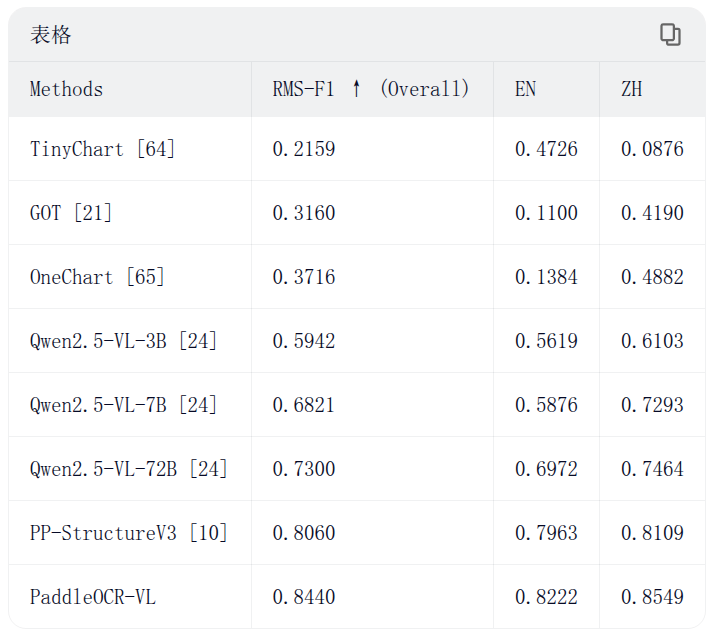
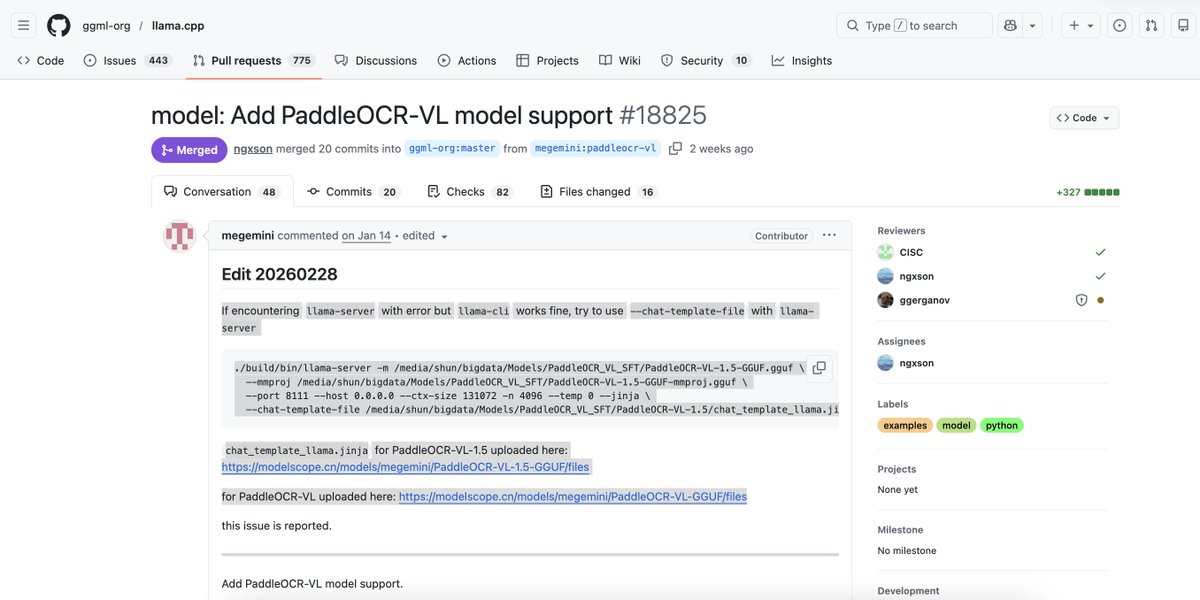
🔥 PaddleOCR-VL is now available in the llama.cpp ecosystem
This brings document parsing VLMs closer to local and lightweight deployment workflows — making it easier for developers to explore portable, community-friendly multimodal document AI.
Why it matters
🔹 Easier access to PaddleOCR-VL in GGUF-based workflows
🔹 More flexible paths for local inference and lightweight deployment
🔹 A simpler way to experiment with structured document understanding beyond traditional OCR stacks
⚠️ Important note for developers
If llama-cli works but llama-server throws errors, try explicitly passing --chat-template-file when launching llama-server.
Chat template / GGUF resources
👉 PaddleOCR-VL-1.5-GGUF: https://t.co/F8qxYL0b3X
👉 PaddleOCR-VL-GGUF: https://t.co/BLorWbajVl
A meaningful step toward making document intelligence more open, more portable, and more developer-ready.
#PaddleOCR #llamacpp #GGUF #DocumentAI #MultimodalAI #OCR #OpenSourceAI
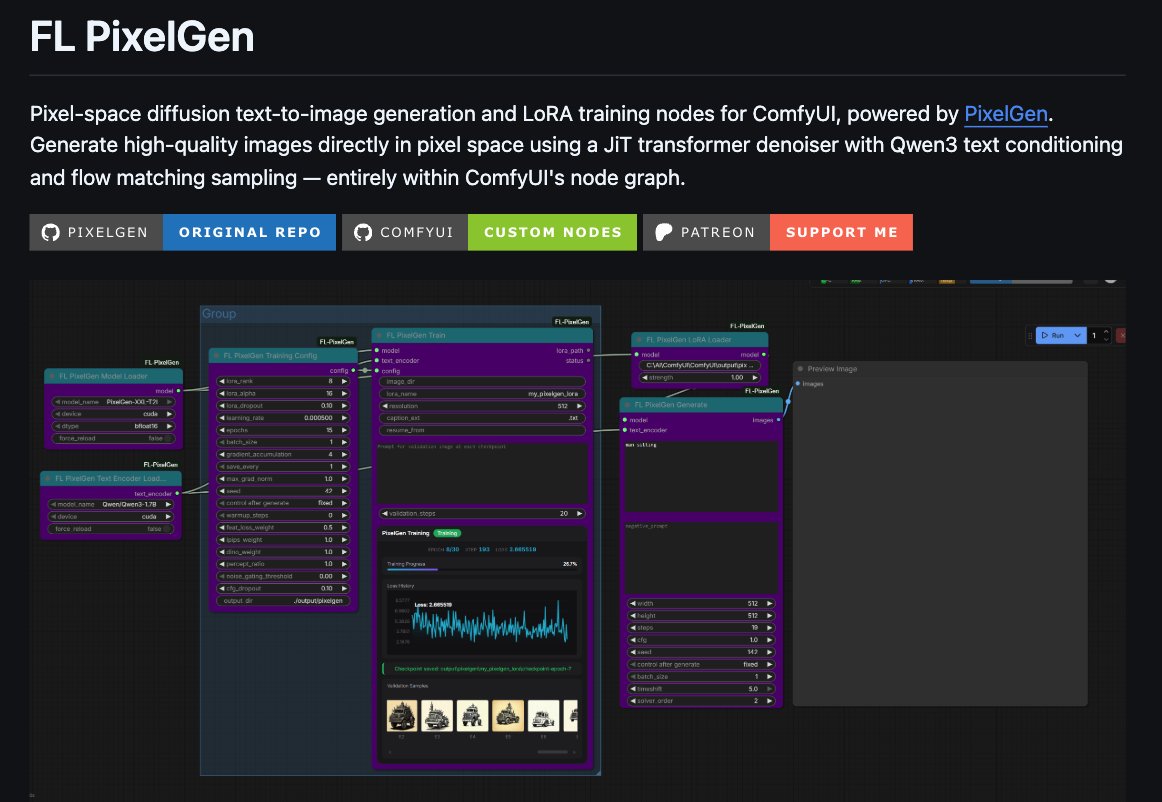
⏰Released the PixelGen Repo for @ComfyUI
This is a pixel diffusion model. No Vae! All diffused in pixel space!
LoRa training nodes included as well. Link Below👇
Rust implementation for Speech-to-Text based on open-source Qwen3 models
* Self-contained binary build — no external dependencies
* Uses libtorch on Linux with optional Nvidia GPU support
* Uses MLX on MacOS with Apple GPU/NPU support
🔨 CLI for AI agents and humans: https://t.co/knsZlastgQ
🖥️ OpenAI compatible API server: https://t.co/qjDqCf9hor
🤖 OpenClaw skill: https://t.co/tE6lzTjYpy
Why and how
https://t.co/VxRt9oSZ8a
What if your AI agent got better just by talking to you?
Introducing OpenClaw-RL — a fully async RL framework that turns your everyday conversations into training signals. Your agent learns your habits, your workflows, your preferences. Privately. Continuously. #Clawdbot #openclaw
🔑 Two learning modes:
• Binary RL — likes/dislikes become rewards
• On-Policy Distillation — your textual feedback becomes token-level guidance
Self-hosted. Zero API keys. Your data never leaves your machine.
👉 https://t.co/ry18qekutm
Opus 4.6 made a @Gradio demo for it too!
It uses a "chunked window" approach, allowing it to run up to 160 frames per second (FPS)
I'm really impressed by coding agents - porting a model + demo in less than 2 days
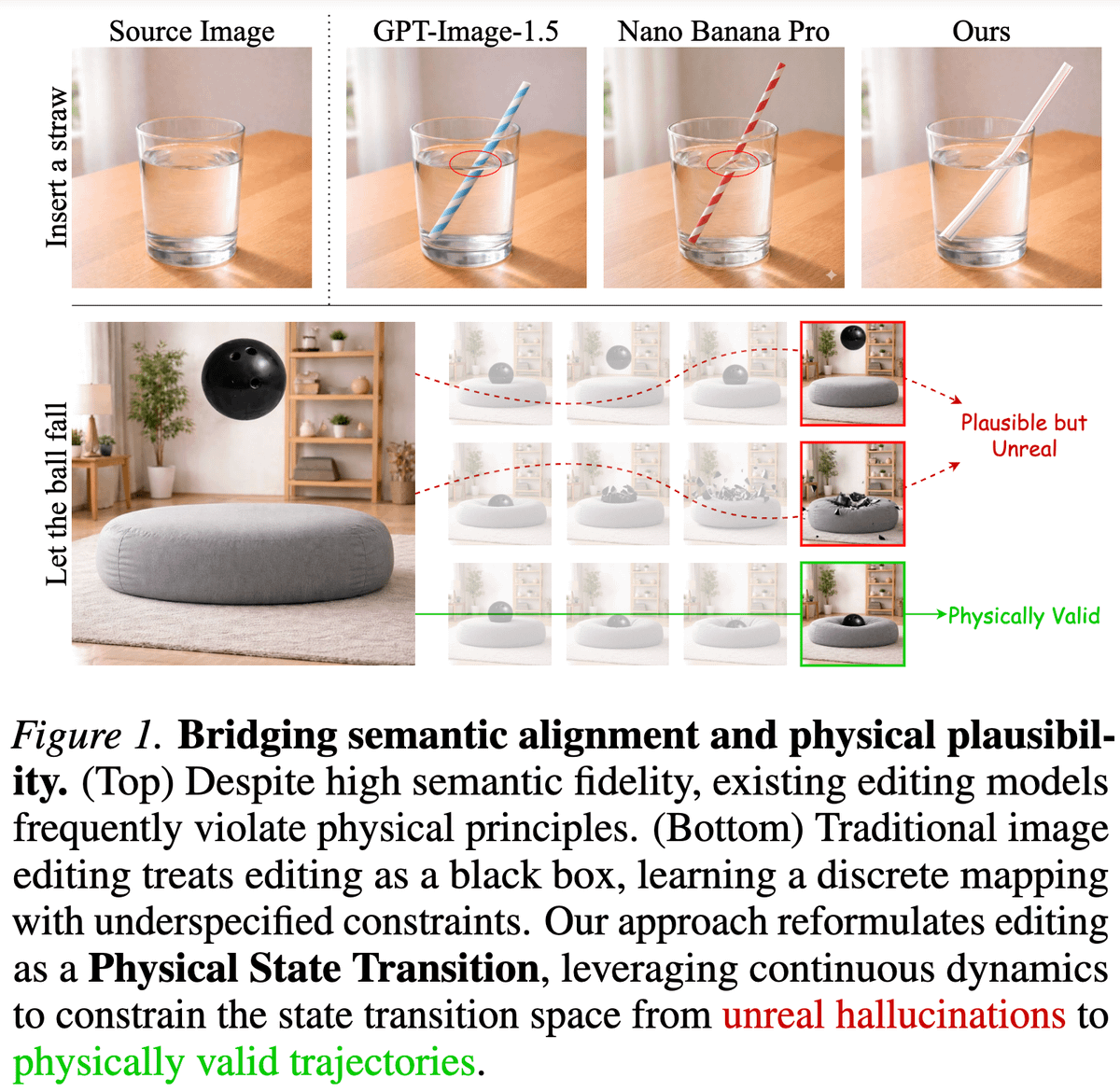
Editing images is a series of state transitions between the source image and the edited image that we want. Yet, the existing paradigm doesn't explicitly include any transitioning priors in the editing process.
This becomes particularly prevalent for edits, involving causal dynamics (e.g., refraction, deformation).
To model this kind of physics-informed information, we leverage the rich priors present in videos and introduce PhysicEdit 🔥
TL;DR: We fine-tune QwenImage Edit on a curated dataset of videos with reasoning traces and fixed-length transition queries to do solid physics-aware image editing!
In the process, we introduce a cool dataset "PhysicTran38K", consisting of 38K transition trajectories across five physical domains and devise a method to provide supervision from it QwenImage Edit.
Hop in to learn more ⬇️
Say you have trained your deep learning model. It works. But do you know what it has actually learned?
🚀 We’ve built SymTorch: a library that translates deep learning models into human-readable equations.
I've attached here a quick video demonstrating how SymTorch works.
If you stuck around till here, thank you!
Please check out the work here: https://t.co/tRpiaC9Xed. We're also open-sourcing everything -- checkpoints, code, and the dataset ❤️
Best collaborators ever: @ben_nebulous, @zhuole1025, and others!