@pmarca We are building https://t.co/uxpdIOI2H5 to tackle this exact thing. Based off our event system for observability and governance over systems of record and agents https://t.co/0XLoAZ8W1V
@Argona0x Now you’re going to have to build a feature creep to handle refunds. You know, seeing as you paid the bill twice 😬😉
‘Read the memo. Read the invoice. Paid the invoice’
But it had already charged your card…
@ApplyWiseAi@pentatonic Yes — local mode is built for Ollama. Default config points embedding (nomic-embed-text) + LLM at Ollama on localhost:11435. Bring your own model, plugin handles ingest + HyDE retrieval on top. Or go hosted via TES if you want team memory + higher-dim embeddings.
🚀 Just shipped: The Pentatonic OpenClaw Memory Plugin is LIVE on npm
openclaw plugins install @pentatonic-ai/openclaw-memory-plugin
Event-sourced agent memory for OpenClaw. Auto-recall. Auto-capture. Runs fully local or hosted. Your agent finally remembers everything that matters 🧠
Retrieval is semantic similarity + HyDE query expansion against live context, not chronological replay. Memories rank by relevance to the current query; stale ones fall below min-score threshold. History persists in the event store; ranking is derived and query-local, not log-ordered.
Drops straight into OpenClaw's plugins.slots.memory -- replaces memory-core or memory-lancedb.
Works across every channel: Telegram, Slack, WhatsApp, Discord 💬
Memory that survives compaction, survives restarts, survives session boundaries. Because memory should be events, not files.
https://t.co/Ev0INYEt1I https://t.co/2GIAnwpcJO
Let's go 🦾
The best part? Runs entirely on your machine 🏠
PostgreSQL + pgvector + Ollama in Docker. No API keys. No cloud. No vendor lock-in. Even works on a Raspberry Pi 5.
Need production scale? One config change to hosted TES for 4096-dimensional embeddings and team-wide shared memory. Same plugin.
This is the right problem. We’ve been attacking it from a slightly different angle with the Thing Event System.
Rather than RL over edge weights, TES treats forgetting as an architectural property of event sourcing. Facts aren’t deleted or decayed. They’re superseded by newer events. Every node carries temporal validity and access frequency metadata natively, so retrieval already knows what’s current and what’s stale without a separate optimisation pass.
The Bias Evolution layer (Gene Expression Programming, not RL) does something similar to what you’re describing with memify() but across the full event stream. It detects drift in retrieval patterns and flags when the knowledge graph’s structure no longer matches actual usage. The graph doesn’t just decay unused paths. It evolves its own fitness function based on what’s working.
The result on 10,000 docs: 95% token reduction because the system already knows which paths matter before the agent asks. That’s not re-ranking after retrieval. It’s the graph doing the filtering upstream.
Cognee’s approach is solid and the RL framing is intuitive.
The question I’d push on is whether tuning edge weights is enough, or whether you need the events themselves to carry temporal validity so the graph knows why something decayed, not just that it did. That matters when you need to recall something you “forgot” six months ago because context changed
https://t.co/cuITIitywm
It’s a problem we’ve been focused on for a couple of years now and we have an elegant solution that’s working very well. It’s an event-sourced knowledge layer called the Thing Event System.
Your three problems map directly to our architecture:
Distributed – TES ingests from any source and normalises everything into governed events with provenance, temporal validity, and relationship metadata. Not a data lake. A structured event stream.
Unstructured – Layer 4 is a knowledge graph. Layer 7 is a doc store. The system self-organises relationships between entities (people, companies, projects, decisions) as events flow through. The “thoughtful schema” you’re describing isn’t manual. It emerges from the event graph.
Unverifiable – this is where our Bias Evolution layer comes in. Gene Expression Programming detects drift in the knowledge base over time. It doesn’t just store what the user said was good. It tracks how the system’s outputs evolve against feedback patterns and flags when quality is degrading. Not solved, but measurably better than vibes.
On compaction and scale: 65% retrieval accuracy across 10,000 docs, 80% open domain, with a 95% reduction in token usage. The knowledge graph means you’re never searching the full corpus blind.
The “git repo for knowledge workers” framing is right. We’d say it’s more like an event-sourced ledger – every fact has a history, every relationship has provenance, and nothing is silently overwritten.
Open source SDK: https://t.co/2GIAnwpcJO - there’s a hosted version which is all 7-layers of the memory stack and a free version with 4-layers
My theory on Allbirds becoming NewBird AI:
Someone in procurement ordered 100 tonnes of TPU.
Expected: thermoplastic polyurethane for midsoles.
Received: a pallet of Google Tensor Processing Units.
Too embarrassing to admit. Easier to pivot.
Years working on next-gen materials in footwear and I can confirm this is the most plausible explanation on the table.
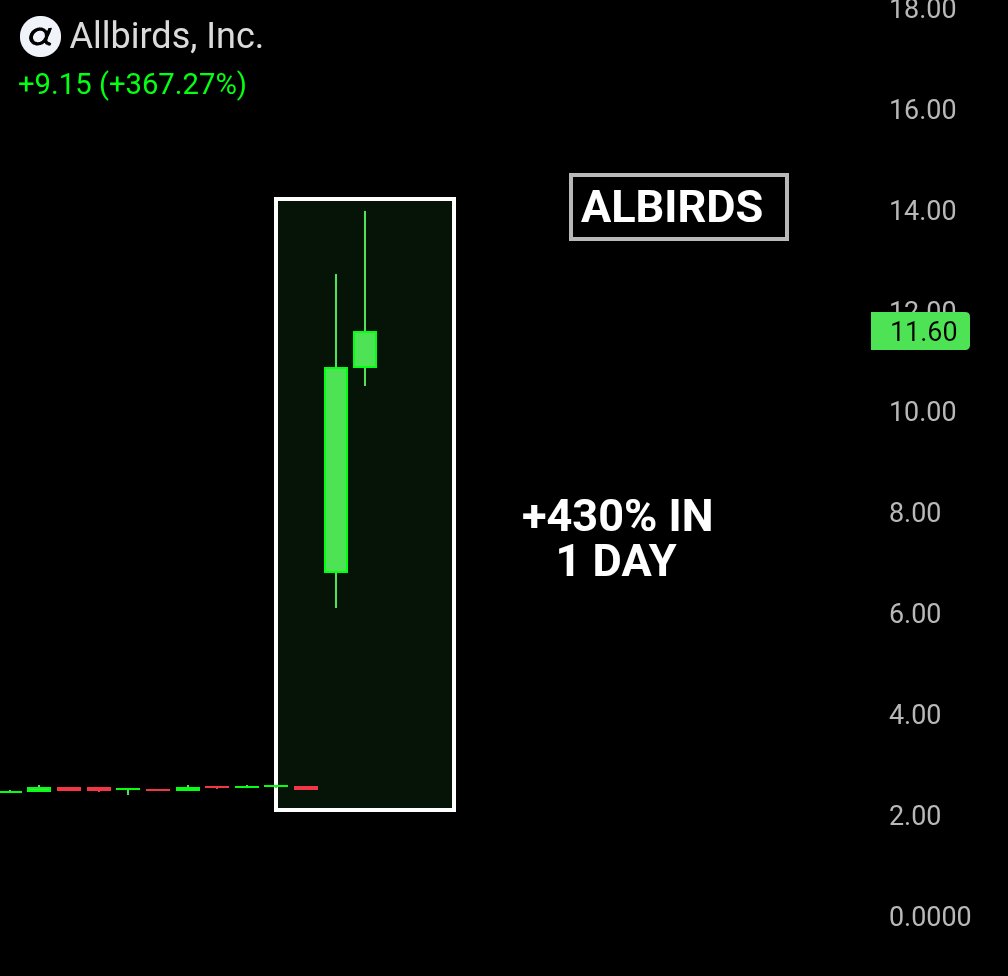
BREAKING: A shoe company's stock is up 430% today after announcing it is ditching shoes and becoming an AI company.
Allbirds, once valued at $4 billion sold its entire shoe business for $39 million and is rebranding as NewBird AI. They plan to buy GPUs and rent out computing power to AI developers who cannot get access through Amazon or Microsoft.
This is a company that was days away from shutting down completely.
One AI announcement changed everything.
The AI compute shortage is so real that a dying shoe company just became an AI infrastructure play overnight and the market gave it a 430% gain in a single day.
The name of the company… NewBird AI. It is a cutting-edge, AI-native cloud infrastructure firm out of- well, they used to be out of San Francisco making sneakers, but forget that, John- they are now awaiting imminent deployment of next-generation GPU compute clusters that have both massive enterprise and consumer applications. Now, right now, John, the stock trades on the Nasdaq at about the price of a cup of coffee. And by the way, John, our analysts indicate it could go a heck of a lot higher than that. And John- one more thing- they're up 160% just today
@DanielleMorrill Yes and they’re shipping thoughtfully too. Thinking one (or five) steps ahead. Not what’s needed now, but will be needed to support where the herd is moving.