A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name.
He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping.
His name is Fabrice Bellard.
Here is the story, because almost nobody outside the systems programming world knows what one man has built.
Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code.
In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years.
Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it.
He was not done.
In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth.
He kept going.
In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real.
In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark.
Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory.
Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org
He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links.
A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet.
He is still shipping.
A harnessed LLM agent, clearly explained!
Most people picture this as a model with tools bolted on. The real architecture inverts that relationship.
The model itself is deliberately thin. Intelligence gets pushed outward, and the harness composes it at runtime.
Three dimensions orbit the harness core:
- 𝗠𝗲𝗺𝗼𝗿𝘆 holds the state a model shouldn't carry in weights or context. Working context, semantic knowledge, episodic experience, and personalized memory each have their own lifecycle.
- 𝗦𝗸𝗶𝗹𝗹𝘀 hold procedural knowledge. This can cover operational procedures, decision heuristics, and normative constraints that specialize the general model per task.
- 𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹𝘀 hold the interaction contracts. Agent-to-user, agent-to-agent, and agent-to-tools are three distinct surfaces with their own failure modes.
Between the core and these modules sit the mediators, like sandboxing, observability, compression, evaluation, approval loops, and sub-agent orchestration.
They govern how the harness reaches out and how state flows back in.
The useful question this framing unlocks is: for any new capability, where should it live?
- Stable knowledge goes to memory
- Learned playbooks go to skills
- Communication contracts go to protocols
- Loop governance goes to the mediators
Harness design becomes a question of what to externalize, and how to mediate it.
I'm building a minimal agent harness from scratch and will open-source it soon.
In the meantime, my co-founder wrote an article about the anatomy of Agent Harness, covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent.
Read it below.
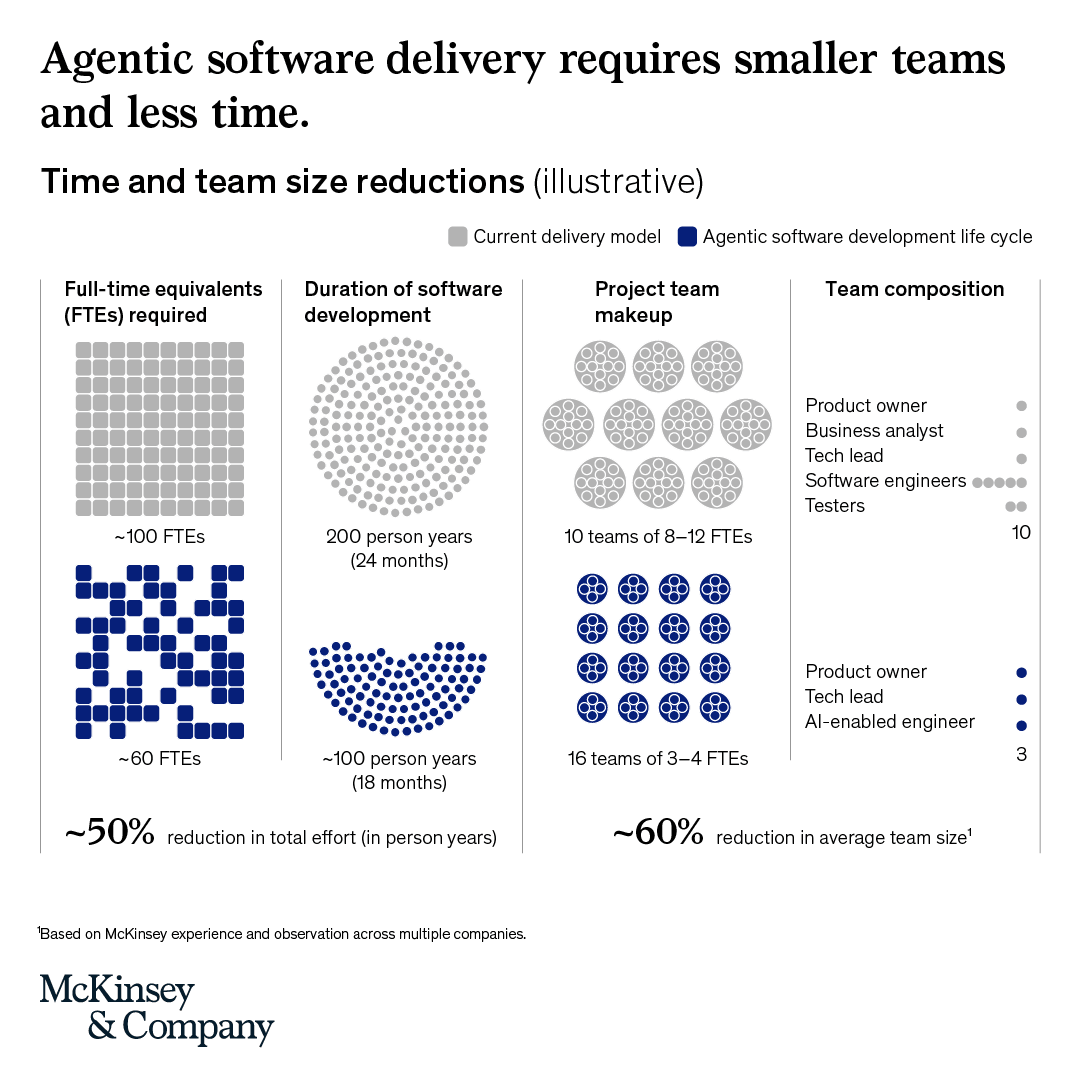
Leading companies are moving from two-week sprint cycles to a daily rhythm that combines human judgment with overnight agent execution.
The opportunity now is how organizations use the capacity those agent-enabled workflows create. https://t.co/heERvijLRD
This SkillOpt paper from Microsoft is a must-read!
(bookmark it)
I was a bit skeptical of the results reported in the paper when I shared it a few days ago.
However, I managed to integrate it into my agent orchestrator and ran a few experiments.
The results are mindblowing.
Essentially, all my agent skills now have a proper testing framework and a way to self-evolve. I have started to improve all my agent skills with this.
One exciting result was when I applied it to my paper-figure-extraction skill, which requires an agent to do multimodal analysis. In particular, it improved quality by +20 points (0.73 → 0.93). I went to see the extracted tables and figures, and I was absolutely stunned by how much better my skill got at the task.
Self-improving AI is in the early days, but I think this work is a clear example of the current ability of agents to self-improve.
In this case, it was skills, but it's not hard to imagine how this scales to optimizing agent patterns, tool use, context engineering efforts, agentic search, workflows, evals, and even the harness itself. I already started with a few of these ideas inspired by SkillOpt.
Stay tuned!
Very good advice on self-improving agents.
(bookmark it)
This is something I am seeing in my own experiments with coding agents and harnesses for long-horizon tasks.
What I have found is that stronger models do not always evolve better agents.
The current believe in self-evolving agents is that a bigger model writes better prompt and skill edits, so devs put their best model in the evolver seat.
New research shows that intuition is mostly wrong.
The work separates two abilities that usually get conflated. Producing harness updates stays flat across model capability, so Qwen3.5-9B writes edits roughly as good as Claude Opus 4.6. Benefiting from those updates follows an inverted-U that peaks at mid-tier models, while weak models fail to even activate the edits and strong models have little headroom left.
This is important to understand as it tells you where to spend. Put a cheap model on the evolver and your expensive model on the solver, because the gains land solver-side, not evolver-side.
Paper: https://t.co/8kJwR7NhmV
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
New research from Microsoft Research
I see a lot of AI engineers handwriting agent skill docs and hope they generalize.
Probably not optimal. This works show why.
It treats the skill doc as a trainable external state of a frozen agent instead.
It introduces SkillOpt, where an optimizer model makes validation-gated edits to the skill file. It adds, deletes, or replaces instructions, with a textual learning rate that controls how aggressively each round rewrites the doc. The agent itself never changes.
SkillOpt is best or tied on all 52 (model, benchmark, harness) cells.
On GPT-5.5 it adds 23.5 points in direct chat, 24.8 with Codex, and 19.1 with Claude Code over no skill. It beats human-written skills, TextGrad, GEPA, and EvoSkill, carries zero extra inference-time cost, and the learned skills transfer across models and harnesses.
Paper: https://t.co/mNgTmmT32U
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Claude Code is about to release a feature called /workflows that I think will be extremely significant.
Especially for Enterprise AI.
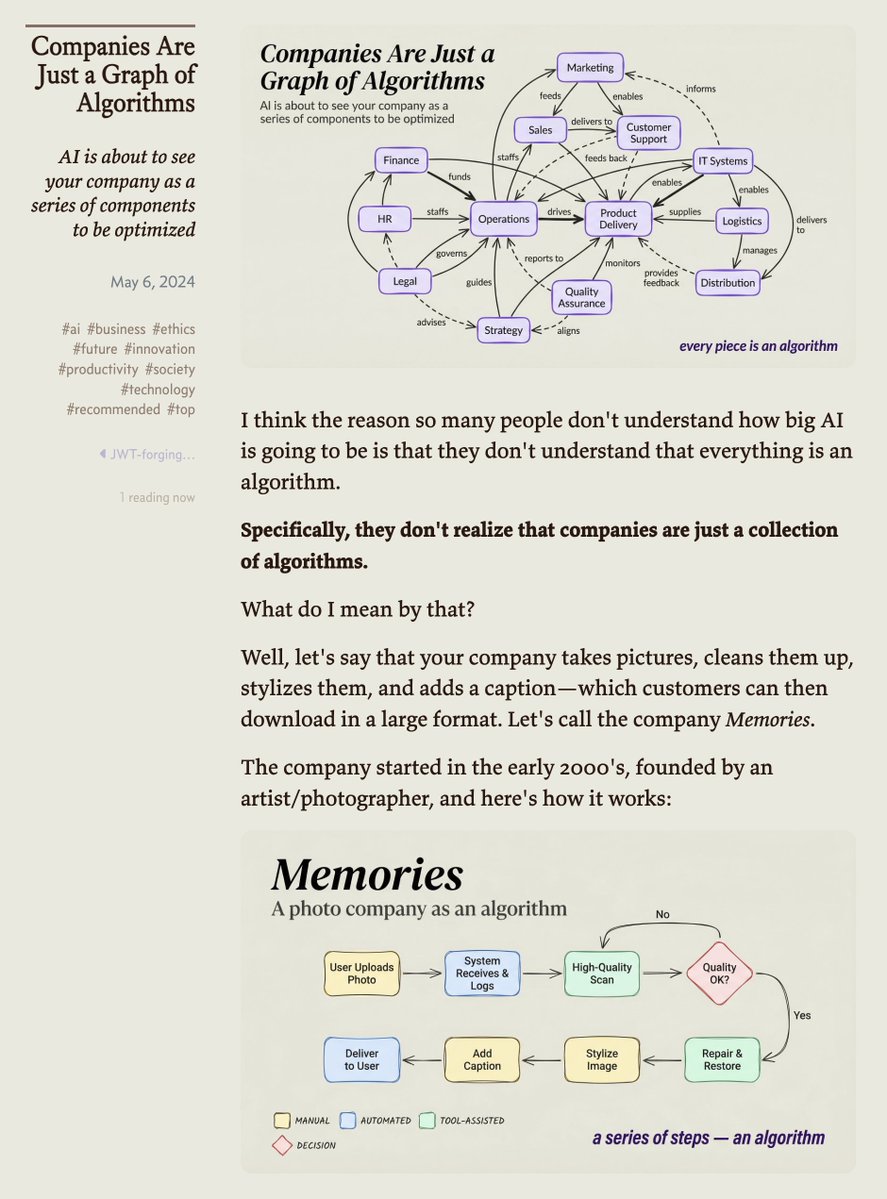
I talked about this in 2024 in a post called Companies Are Just Graphs of Algorithms.
Basically the idea is that all work is just an algorithm, i.e., a series of steps to accomplish a goal.
Skills and Cowork have been heading in this direction already, and we've seen what that's done to company valuations in various spaces.
Well this is closer to the final form.
It's turning the regular, expected work that's done in companies into pseudo-deterministic workflows that follow defined SOPs.
The human role will be determining what problems to solve (taste, expeirence, etc), building new products from that, and then optimizing these workflows from above.
But the work itself will be these workflows executed according to SOPs.
AI Agent Governance Toolkit - by Microsoft
Runtime governance for AI agents through deterministic policy enforcement, zero-trust identity, execution sandboxing, and SRE for autonomous agents. Covers all 10 OWASP Agentic risks with 13,000+ tests.
https://t.co/sONejSjsrX
"You cannot govern a technology you have only been briefed on."
Singapore Minister for Foreign Affairs, Dr. @VivianBala, echoing @karpathy and @yacineMTB on why he runs NanoClaw: "you can outsource memory and computation, but you cannot outsource your understanding"
https://t.co/z4Aidf89ha
He also shared his tech stack for running his second brain for Singapore's Foreign Affairs Ministry and parliamentary affairs:
- @AnthropicAI Claude Agent SDK
- Baileys + WhatsApp
- Mnemon (Graph Memory)
- @ollama + @nomic_ai
- @ggerganov Whisper.cpp + OneCLI
With special notes on how he handles security and isolation, and what implications he sees for Singapore Inc.
Singapore’s Foreign Minister, Dr Balakrishnan casually explaining how he built his own AI agent (a 2nd brain for diplomacy) using Claude & WhatsApp integration etc. on a Raspberry Pi
“You cannot govern a technology you have only been briefed on.” 🇸🇬
Despite being told no, I'm open-sourcing TrustClaw.
You can now deploy a production-ready personal agent service with over 1000+ app integrations in a single command, straight to @vercel with npx @composio/trustclaw deploy
I was inspired by @openclaw to build a simple web app where anyone could create their own 24/7 personal assistant and connect it to Gmail, Google Calendar, Notion, Slack, GitHub, HubSpot, Linear… well everything, and securely through OAuth/sandbox execution.
It went viral on X, reached over a thousand users in less than 48h, and revenue began pouring in.
If you are thinking like a company, you'd probably keep that locked up. But why should I be the reason you spend another year scrolling instead of building?
So today, I'm open-sourcing TrustClaw anyway.
> 24/7 agents that act across Gmail, Notion, GitHub, Slack, Linear, Jira, and 1000+ apps
> OAuth and sandboxed execution, so users don't have to hand agents passwords or raw API keys
> Supports multiple users and authentication right outside of the box with @better_auth
Repo is open, MIT licensed.
If I were starting an AI company today, I'd clone this, pick a market, and begin shipping with Claude Code.
Honestly so excited to see what comes out of this.
Programmers, PMs, and designers are in a three-way Mexican standoff.
.@pmarca says the new job title is "builder."
"The programmers think that they don't need the product managers and the designers anymore because they can have AI do that."
"Each of the other two doesn't think they need the other two either."
"What I've been predicting is they're all correct."
"The product manager can generate code and design now, and each of them can do the job of all three."
"Now the job is builder."
"It's entirely possible that we're sitting here in 10 years... the job of coder is gone, but you have this extraordinary number of builders running around."
i made a game where you play the piano IRL to survive against waves of monsters
thank you to the 500 musicians and teachers who've played and given feedback so far. more features coming soon !!