📢 OneCanvas: 3D Scene Understanding via Panoramic Reprojection
We extract features from video frames and reproject them into one occlusion-free view of the whole scene that a 2D VLM reads just like a normal image. We can center this view on any viewpoint, including an agent's own pose for situated reasoning.
The same projection lets us create spatial training tasks with no human annotation, solvable only by reasoning over the 3D positions of real object features placed on an otherwise empty canvas.
The result is a stock 2D VLM that reasons in 3D, setting a new state of the art across spatial benchmarks at far less compute.
🌐 https://t.co/ilo141614B
▶️ https://t.co/lANFmN5gNy
Great work by @baranowskibrt & @davech2y
📢📢GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction📢📢
Reconstructing high-fidelity 3D scenes from sparse RGB input is hard. It needs a strong 3D prior!
We reformulate multi-view scene reconstruction as conditional 3D generation over overlapping spatial chunks, lifting posed image features into a generative shape prior via 3D conditioning. As an example prior, we build on Trellis2, and train it such that its reconstruction is pixel aligned and matches from all views.
GenRecon achieves unprecedented reconstruction quality from any sparse RGB input sequence, even from a phone capture. The reconstruction also includes PBR materials which facilitates relighting and virtual object insertion.
https://t.co/1RMD40WRpz
https://t.co/u4IEi5PTtn
Amazing work by @katha_schmid, @nicolasvluetzow, Jozef, @angelaqdai
If you are at #Eurographics tomorrow, don't miss our STAR session on "How to Build Digital Humans?" 🕺
🗓️ Monday, 4th of May
🕐 1:15 pm - 2:45pm
🏡 Kino 5
We will have experts in the field share their thoughts on 3D avatars.
It will be cinematic!
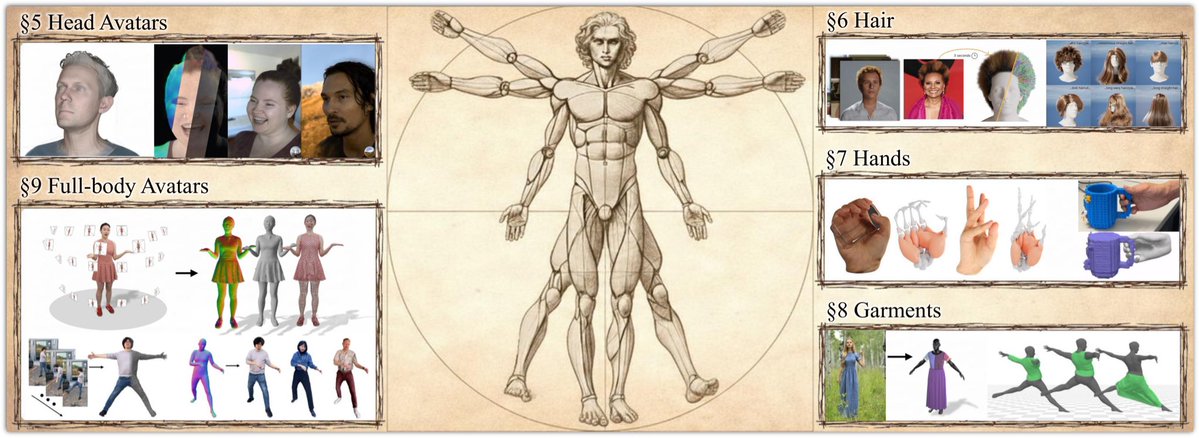
I am happy to share that our STAR has been accepted to Eurographics 2026:
“How to Build Digital Humans?”
It introduces a novel taxonomy and a concise overview of the full creation pipeline, from face and body to hands, garments, and hair.
https://t.co/E8YsdKpQGF
7/ 🇬🇧the support system in the iOS app is also a mess. When I try to get help again via the app, a hopeful message turns out to link to my old chat, where I was the last one responding.
@Uber_Support@Uber_Brasil urgent help needed! I left my luggage in an Uber in Rio with my passport inside. I’ve already filed a report in the app, but the driver isn’t responding. I’m a tourist and need to fly back to Germany. Can you help me reach him? 🙏
Image & video synthesis struggle with the scale of truly large 3D scenes.
@mschneider456 presents a geometry-first approach :
- structure first: mesh scaffold defining the scene
- then appearance: mesh-conditioned image synthesis
Check it out: https://t.co/8fXCl2flIu
📢WorldAgents: 3D worlds only from 2D image models - without any training!
We propose an agentic approach with a Director (VLM) to plan the scene, a Generator (Flux or NanoBanana) for new views, and a Verifier (VLM) for selection / 3D consistency.
-> High-fidelity 3D worlds from a single text prompt.
What's remarkable: our agents find consistent views from 2D image models to obtain 3D-consistent worlds; this shows that image models contain world priors - agents just need to find them!
https://t.co/6NC7zIEn4n
https://t.co/vTO3sLFLFw
Great work by @ErkocZiya@angelaqdai
📢 3D world models from video diffusion suffer from inconsistent frames -> blurry output.
Our fix: instead of naïve 3D reconstruction, we non-rigidly align each frame into a globally-consistent 3DGS representation.
->sharp visuals on top of any VDM!
https://t.co/laBngKn1wl
📢Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image📢
We directly regress neural parametric head models (NPHMs) from a single image — fast, stable, and significantly more expressive than classical 3DMMs such as FLAME.
Face tracking & 3D reconstruction are often limited by the representational capacity of PCA-based face models. By lifting NPHMs to a first-class reconstruction primitive, we enable more accurate geometry, richer expressions, and finer animation control.
Pix2NPHM obtains fast and reliable NPHM reconstructions on real-world data. Inference-time optimization against surface normals and canonical point maps can further increase fidelity.
Key to successful and generalized training of our ViT-based network are:
(1) large-scale registration of existing 3D head datasets, and
(2) self-supervised training on vast in-the-wild 2D video datasets using pseudo ground-truth surface normals.
Finally, we show that geometry-aware pretraining on pixel-aligned reconstruction tasks significantly outperforms generic visual pretraining (e.g., DINO-style features) in terms of generalization.
🌍https://t.co/89IXGnDl4O
🎥https://t.co/7AZIcnD3Mq
Great work by @SGiebenhain, @TobiasKirschst1, @liamschoneveld, Davide Davoli, Zhe Chen
Want to create an avatar from a single image?
FlexAvatar is a transformer model that creates full 360°, high-quality, and expressive 3D head avatar from just a single portrait image in minutes.
Real-time Demo: FlexAvatar's lightweight architecture allows both animation and rendering in real-time, enabling interactive user experiences. To create a new 3D head avatar, only one image is required, e.g., from a webcam. The final avatar is ready after 2 minutes.
Architecture: Under the hood, FlexAvatar adopts a transformer-based encoder-decoder design. The encoder maps the input image onto a latent avatar space, while the decoder produces 3D Gaussian attribute maps by incorporating the animation signal via cross-attention.
The model learns all facial animations directly from the data without relying on pre-built 3D face models. This equips the avatars with realistic facial expressions.
The internal avatar latent space can be conveniently used to integrate additional observations of a person via fitting. This enables use-cases where more than one image of a person is available, e.g., from a phone scan of the person.
We train jointly on 2D monocular videos and multi-view data. However, in monocular videos, the animation signal leaks the target viewpoint, causing the model to produce incomplete 3D heads. We call this phenomenon entanglement of driving signal and target viewpoint.
To prevent entanglement, we introduce bias sinks. These are learnable tokens that indicate whether a training sample stems from a monocular or a multi-view dataset. During training, the model learns to produce incomplete 3D heads only when the monocular token is present.
During inference, FlexAvatar then always uses the multi-view token for which the model has learned to produce complete 3D heads. This simple design allows to combine the generalizability from monocular data with the quality of multi-view data.
FlexAvatar summary:
- Input: Single-image, phone scan, or monocular video
- Output: Full 360° head avatar
- Expressive animations
- Real-time rendering and animation
- Generalization to any portrait
- Create a new avatar in 2 minutes
- Use bias sinks to combine 2D and 3D data
🏠https://t.co/DTmz4OYtBM 🌍https://t.co/kghX1sloWU
🎥https://t.co/PHKXvGRK6J
Great work by @TobiasKirschst1 and @SGiebenhain!
Congrats to @yawarnihal for winning the @MdsiTum best paper award for his amazing 𝐌𝐞𝐬𝐡𝐆𝐏𝐓 work🎉
MeshGPT autoregressively generates compact, artist-style triangle meshes by tokenizing faces into a learned discrete vocabulary (VQ-style codebook) and training a decoder-only transformer to predict those face tokens — because discrete tokenization + attention lets GPT-style models learn long-range geometric & topological patterns and produce coherent, high-fidelity 3D assets.
MeshGPT's use cases go far beyond traditional content creation applications in computer graphics. For instance, the method was developed in collaboration with @Audi to help rapid prototyping of car designs, where explicit and precise mesh design are essential.
In the research community, there have already been many follow ups such as MeshAnything, MeshXL, Meshtron, and many more - finally, we can use AI to generate high-fidelity 3D content :)
Project: https://t.co/N8MLltTuKK
Video: https://t.co/lzJeGhTaEA
Can we use video diffusion to generate 3D scenes?
𝐖𝐨𝐫𝐥𝐝𝐄𝐱𝐩𝐥𝐨𝐫𝐞𝐫 (#SIGGRAPHAsia25) creates fully-navigable scenes via autoregressive video generation.
Text input -> 3DGS scene output & interactive rendering!
🌍https://t.co/HBdrmU4Oqq
📽️https://t.co/AQr0p4uWBZ
We will present Avat3r at #ICCV2025! 🥳
Avat3r brings animation to Large Reconstruction Models.
One surprising finding was that we can get rid of any template-based deformation modeling and simply use cross-attention to an abstract facial expression code.
https://t.co/EqyZcVbu4J
📢 LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans🏠✨
-> converts RGB-D scans into compact, realistic, and interactive 3D scenes — featuring high-quality meshes, PBR materials, and articulated objects.
📷https://t.co/w8hixxH0m2
🌍https://t.co/e7gbHJAPMD
📢SceneFactor code is released!
SceneFactor is a factored latent diffusion for controllable, large-scale scene synthesis and editing!
w/
@QTDSMQ, @shubhtuls, @angelaqdai
Check out the code here: https://t.co/FIMiRSTFIs. We present SceneFactor at #CVPR2025 on Fri 13, -10:30 PDT. Don't forget to drop by 😊
📢PBR-SR: Mesh PBR Texture Super Resolution from 2D Image Priors📢
We propose a new optimization to up-sample textures of 3D assets (albedo, roughness, metallic, and normal maps) by leveraging 2D super-resolution models.
📝https://t.co/snnZXJyq7T
📽️https://t.co/M4MAv0Xi7z
NeRSemble benchmark submission deadline extension for #CVPR2025!
Due to lots of submissions in the past days, we have decided to extend the deadline until Wednesday, 28th May. You have 5 more days to submit your SOTA method for dynamic NVS and monocular 3D head avatar creation!