PhD Researcher | LLM4SE & multi-agent AI systems | LLMs for mathematics & autoformalization | Open to research collaborations, industry roles & consulting
I recently presented LogSieve at MSR’26: reducing CI logs for LLM-based analysis.
42% smaller logs, 40% fewer tokens, while preserving root cause analysis.
Pre-print: https://t.co/Rh9eIe5Kj1
#LLM#MLOps
For the last two weeks I switched completely to the "loop philosophy". Just a few research frontier examples:
1. I have a paper on Groebner bases and heavy computations. Made a loop which analyzes the structure of those bases with Codex. Server-based Magma is in the pipeline. The model revamped the proof structure to completely get rid of all the heavy CPU computations. Effect: the final draft contains only computations which can be human-checked.
2. A hunt for sparse, crystal-driven sphere packings. Made a loop which analyzed the existing work of Fisher, made corrections with Python code to verify all the data from the tables. Found a new example of a packing that was missing in our list. Server-grade computations + heavy web search combined with looped Python verification.
3. Presentation about agentic workflows for high school teachers. Made a loop which parsed all the input data, carved a GitHub project with the whole presentation, and helped me prepare easy-to-understand examples for a first encounter with agents. Local runs with Claude Code, reviewing the slides, composition etc. all with the autonomous loop. Gave the talk, very well received, shared examples and code with people on GitHub.
And the list can go on. TL;DR: if you wonder whether agentic workflow is important in 2026, think that it's actually critical for stabilizing the verification, consistency, and structure of the work done with LLMs. Big caveat: you need to carefully plan first, provide high-quality data sources, control the intermediate feedback, and be in control of this madness. There is a fine line between full YOLO and loop management. Don't miss it.
We’re excited to launch SAIR’s 3rd competition: IGP24, the Inverse Galois Problem in degree 24.
Co-organized by John Jones, Jen Paulhus, David Roe, Andrew Sutherland, and Terence Tao, in collaboration with LMFDB.
Join the Compeitition:
https://t.co/9J88HV94AR
Presenting Regularized f-Divergence Kernel Tests, a new framework for auditing machine unlearning and differential privacy. This method is more sensitive to localized data shifts and requires fewer samples than traditional tools. Learn more: https://t.co/FdPcfJeEs4
The CMS is pleased to announce Dr. Jamie Mulholland (@SFU) as the recipient of the 2026 Adrien Pouliot Award.
La SMC a le plaisir d'annoncer que le Dr Jamie Mulholland (Simon Fraser University) est le lauréat du prix Adrien Pouliot 2026.
🔗https://t.co/JmJDuGOFNX
The 2026 Jean-Pierre Demailly Prize for Open Science in Mathematics has been awarded to Mathlib! From the citation:
"Mathlib is widely recognized as an exceptional contribution to the mathematical community. It is seen as having an exceptionally broad structural significance for the future of mathematics. It is not only a resource of immediate value, but also an infrastructure with the potential to transform mathematical practice in a lasting way.
The project plays a central role in the formalization and verification of mathematics. This aspect is of particular importance in the current scientific context, as formal proof verification, automated reasoning, and AI-assisted mathematical work are likely to play an increasingly significant role in the years ahead.
Mathlib is also widely viewed as exemplary in its openness and collaborative organization. It lowers barriers to participation, enables contributions from a broad international community, and provides a framework in which mathematical knowledge can be verified, shared, preserved, and reused at large scale.
For all these reasons, Mathlib is not merely a successful project within an existing category, but it is helping redefine the way mathematical knowledge may be produced, checked, and disseminated in the future."
Congratulations!! https://t.co/TZ9qnyjoBh
STEM academia serves two closely intertwined purposes: the production of high quality science and the production of human capital. These two purposes feed into each other. The obvious direction is that we develop human capital by paying people to produce science.
What is perhaps less obvious is that the very fact that human labor is used to produce science has historically been an important input to its quality. The goal of science is not simply to produce papers, but rather to produce good work--that a person is willing to spend months working on a paper is a (weak) witness to the fact that it has some minimum quality. If someone has a record of producing high quality work, that they wrote a paper is a stronger witness, since it was worth the opportunity cost to write it. If many people engage with it substantially, that is even stronger evidence. This is not to say that there isn't lots of low-quality work--there is, in fact a huge amount--but we have strong sorting mechanisms, admittedly using imperfect proxies (all depending on costly human labor!), to find high-quality stuff. Arguably the paper itself is not the primary product here; in many cases the primary product is actually the expertise developed over the course of producing it, which can then be applied to other questions.
If you believe, as I do, that producing high quality science should be one of our fundamental goals, I think you’re obligated to embrace new tools that help one do so. Refusing to is a declaration that these outputs are not important. But I worry that we are not on track to automate the production of good work; rather, we are on track to automate the production of papers. We need new mechanisms to ensure that we are also producing good work, and to ensure that we are developing the human capital to engage with it.
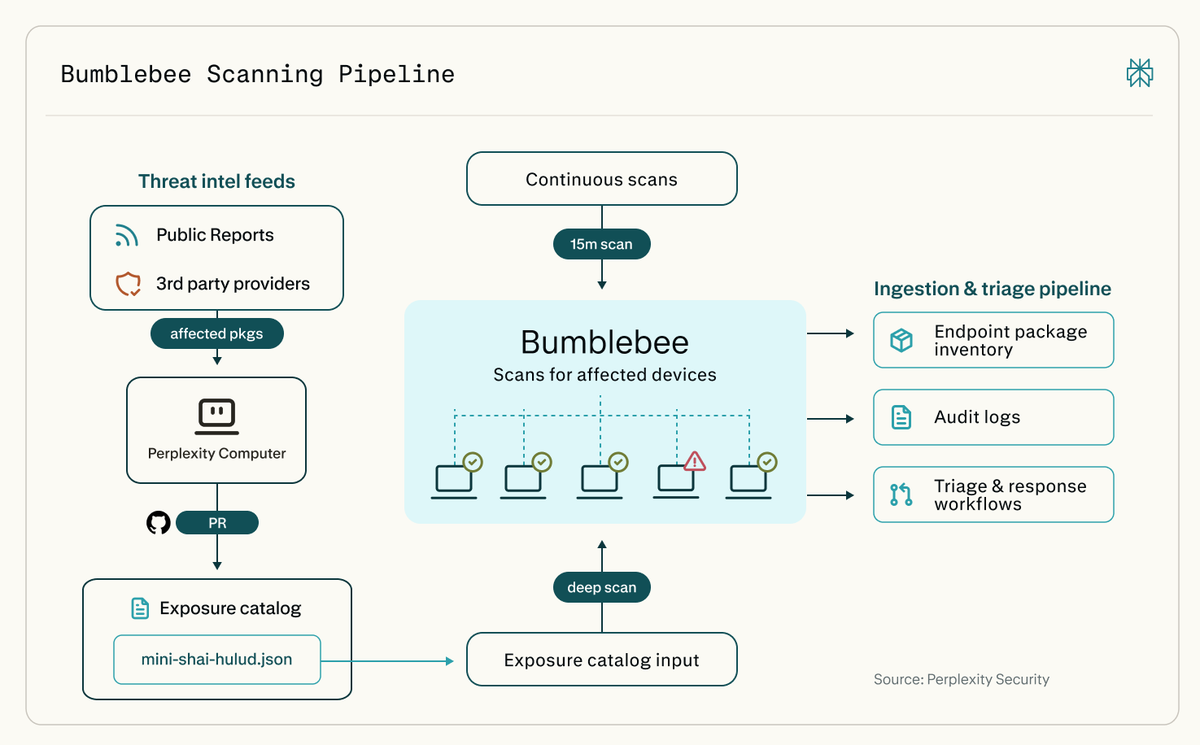
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
https://t.co/FOaWnF1yQy
Academia is one of the few places where, despite all its imperfections, a person could still rise mostly through talent, curiosity, and hard work (example: Ramanujan) — not only through luck, wealth, family connections etc.
But what happens if access to extremely powerful AI assistants becomes the new dividing line?
The news about “superhuman AI” is scientifically exciting. But socially, it raises difficult questions — especially for gifted children from poor backgrounds who may not have access to frontier models.
Maybe no one has asked ChatGPT to disprove other generally believed conjectures... someone should ask for an even integer that is not a sum of two primes, or to find some Siegel zeros for us.
If you are in math and you are depressed, you shouldn't be. The number of projects that I have in mind have tripled or quadrupled now that I can have access to LLM's to assist me on things I had given up before.