My paper titled "Image Based Visual Servoing for Multi Aerial Robots Formation" is finally available on https://t.co/CMwOOGJqPy
soon I will share the video presentation and preliminary experimental results.
If you're interested in SSD internals and how to use them efficiently, our paper, “How to Write to SSDs,” has been accepted to VLDB and is currently on the Hacker News front page. https://t.co/bwYAtPFTBg
Terence Tao - "AI tools are like taking a helicopter to drop you off at the site. You miss all the benefits of the journey itself. You just get right to the destination, which actually was only just a part of the value of solving these problems."
Judit Polgar - "I always felt that intuition is very important in chess, but I get my intuition through my experience. And many times I think that this is the biggest danger for youth, that they don't have the experience because they don't spend enough time doing."
Elites from two different fields voice the same opinion.
[1] https://t.co/XRDSSPjpQ8
[2] https://t.co/fQzPT3D3f4
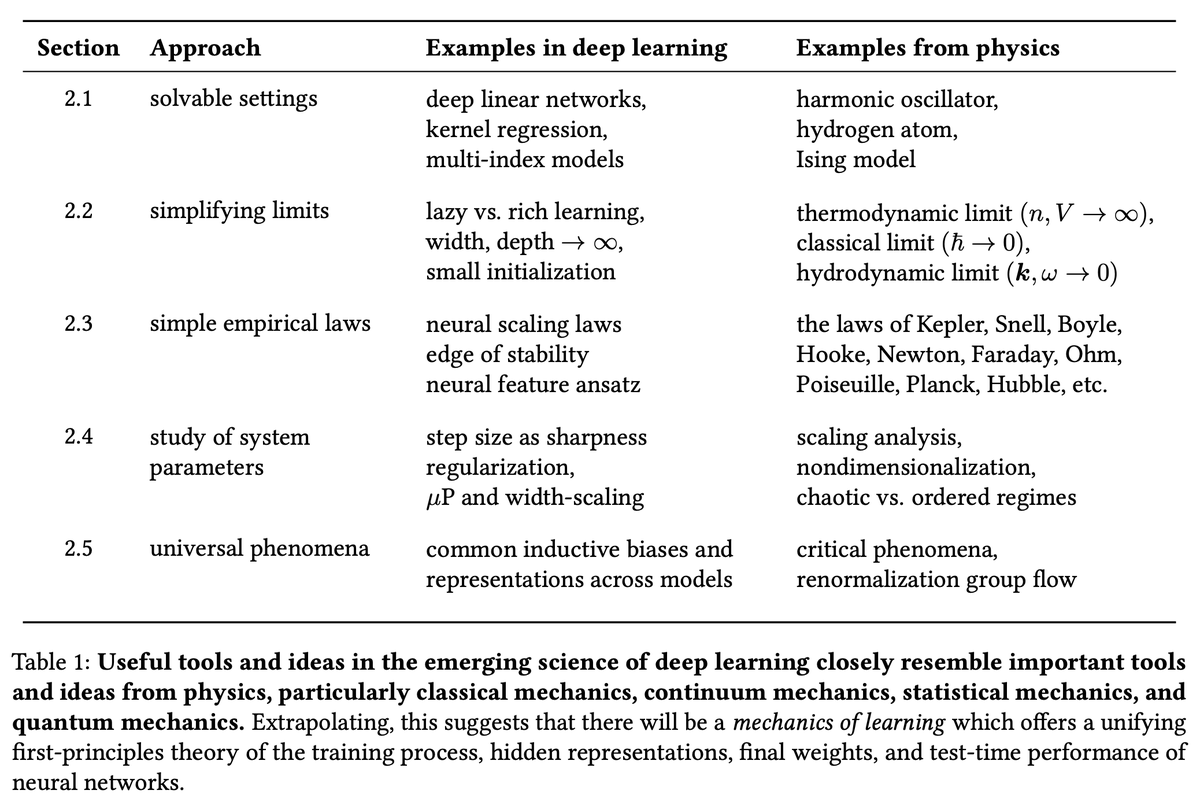
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
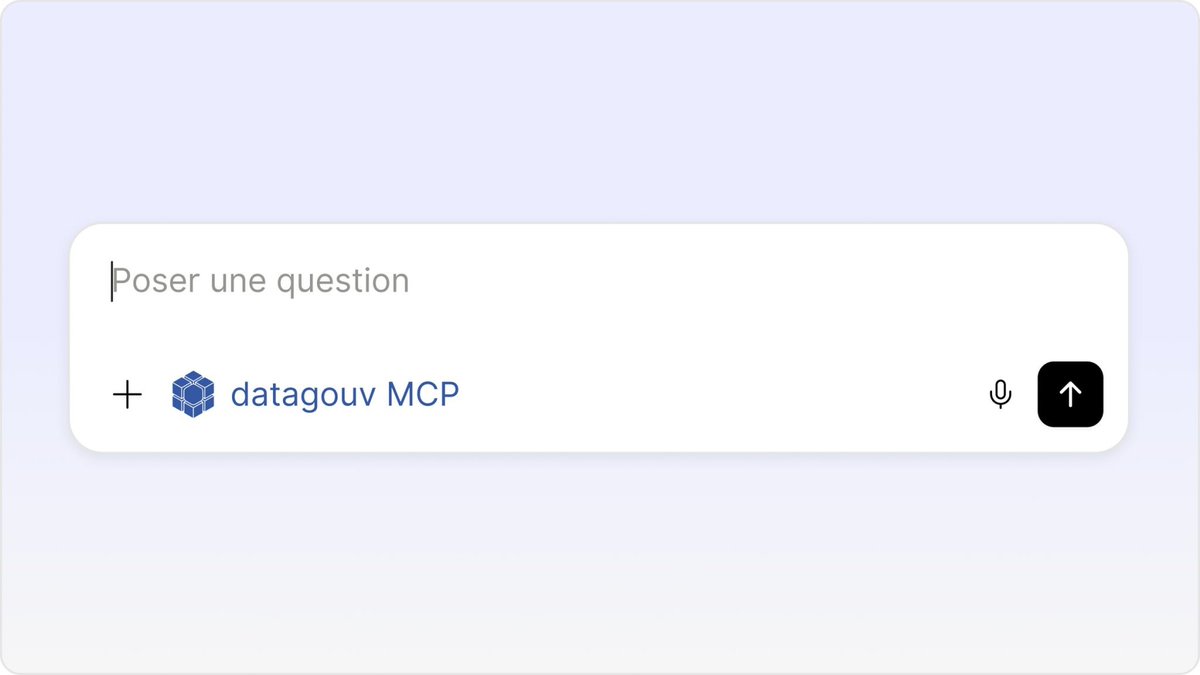
Les données disponibles sur https://t.co/Yz6AmwMTfb sont désormais interrogeables via un serveur MCP dédié en experimentation, vos retours sont bienvenus !
💻 Le code est ouvert et accessible sur GitHub :
https://t.co/AmY04V22TH
Pour en savoir plus : https://t.co/V7UJrc6uUq
𝐕𝐢𝐬𝐮𝐚𝐥 𝐛𝐥𝐨𝐠 on Vision Transformers is live.
https://t.co/N09njkKTXW
Learn how ViT works from the ground up, and fine-tune one on a real classification dataset.
CNNs process images through small sliding filters. Each filter only sees a tiny local region, and the model has to stack many layers before distant parts of an image can even talk to each other.
Vision Transformers threw that whole approach out.
ViT chops an image into patches, treats each patch like a token, and runs self-attention across the full sequence.
Every patch can attend to every other patch from the very first layer. No stacking required.
That global view from layer one is what made ViT surpass CNNs on large-scale benchmarks.
𝐖𝐡𝐚𝐭 𝐭𝐡𝐞 𝐛𝐥𝐨𝐠 𝐜𝐨𝐯𝐞𝐫𝐬:
- Introduction to Vision Transformers and comparison with CNNs
- Adapting transformers to images: patch embeddings and flattening
- Positional encodings in Vision Transformers
- Encoder-only structure for classification
- Benefits and drawbacks of ViT
- Real-world applications of Vision Transformers
- Hands-on: fine-tuning ViT for image classification
The Image below shows
Self-attention connects every pixel to every other pixel at once. Convolution only sees a small local window. That's why ViT captures things CNNs miss, like the optical illusion painting where distant patches form a hidden face.
The architecture is simple. Split image into patches, flatten them into embeddings (like words in a sentence), run them through a Transformer encoder, and the class token collects info from all patches for the final prediction. Patch in, class out.
Inside attention: each patch (query) compares itself to all other patches (keys), softmax gives attention weights, and the weighted sum of values produces a new representation aware of the full image, visualizes what the CLS token actually attends to through attention heatmaps.
The second half of the blog is hands-on code. I fine-tuned ViT-Base from google (86M params) on the Oxford-IIIT Pet dataset, 37 breeds, ~7,400 images.
𝐁𝐥𝐨𝐠 𝐋𝐢𝐧𝐤
https://t.co/N09njkKTXW
𝐒𝐨𝐦𝐞 𝐑𝐞𝐬𝐨𝐮𝐫𝐜𝐞𝐬
Dr @sreedathpanat Videos on ViT
ViT paper dissection
https://t.co/sg3JRvcgNG
Build ViT from Scratch
https://t.co/cnHzEeefDA
Original Paper
https://t.co/QiwrlDRQOc
Next up: demystifying Low-Rank Adaptation (LoRA) in PEFT!
Follow me @Mayank_022 along for more deep learning insights, cool fine-tuning projects, and updates from the upcoming blog posts.
My biggest open-source release!
NumKong — 2'000+ SIMD kernels for mixed-precision numerics, from Float6 to Float118.
Started in 2023. Opened the PR in 2024. Finally, merged this week!
RISC-V, Intel AMX & AVX-512, Apple SME & SVE, WASM Relaxed SIMD. 200'000 lines of code in a 5 MB binary. Same scale as OpenBLAS. Available for C 99, C++ 23, Python 3, Rust, Swift, GoLang, & JavaScript.
Int4 dot products via nibble algebra. Ozaki Float64 GEMMs on Float32 tile hardware. 6-bit and 8-bit floats back-ported to 10-year-old CPUs. 5'300x faster Geospatial metrics than GeoPy. 200x faster Kabsch than BioPython. 0 ULP where OpenBLAS hits 56... and a lot more!
pip install numkong
Or pull it from NPM, Crates, GitHub... and let me know what breaks 🤗
Links & highlights ⬇️
Tom and I have finally finished a draft of Dynamic Programming Vol 2! Exhausting but satisfying. New approach to DP theory, advanced material, many applications... https://t.co/PPDk98DFgV
O3DE eliminates the middleman. With our native ROS2 Gem, you get direct integration—no bridges, no extra lag, no headache.
✅ Direct ROS integration
✅ Modular Gem architecture
✅ Ready-to-go ROS project templates
https://t.co/FdmGve3IZ0
😋 Want strong LLM reasoning without breaking the bank? We explored just how cost-effectively RL can enhance reasoning using LoRA!
[1/9] Introducing Tina: A family of tiny reasoning models with strong performance at low cost, providing an accessible testbed for RL reasoning. 🧵
Useful update to PRH!
It's great to see conversation moving past "do models converge" to "*which* structures converge."
This paper argues that only local structure converges. Matches my intution (its why we like mknn), but hadn't realized extent of the bias in CKA.
New project! Flow Policy Gradients for Robot Control
tldr; a simple online RL recipe for training and fine-tuning flow policies for robots
co-led w/ @redstone_hong: https://t.co/nKSq9EakUy
VLAs and World Models go together like peanut butter and jelly! GigaAI took their already awesome GigaBrain-0.1 VLA and used a world model for reinforcement learning to improve it.
They took 10,900 hours of teleop data (a mix of sim and real) to train the model. They also have human in the loop to correct the VLA when it starts to veer off course.
The result? GigaBrain-0.5M, a new model that may just find itself on top of the RoboChallenge leaderboard.
This is an exciting future for robotics. World models, Sim2Real, frontier VLAs. All going to play a pivotal roles in 2026 and beyond.
Learn more about GigaBrain-0.5M here: https://t.co/PvPRrnH0bz
#Robotics #PhysicalAI
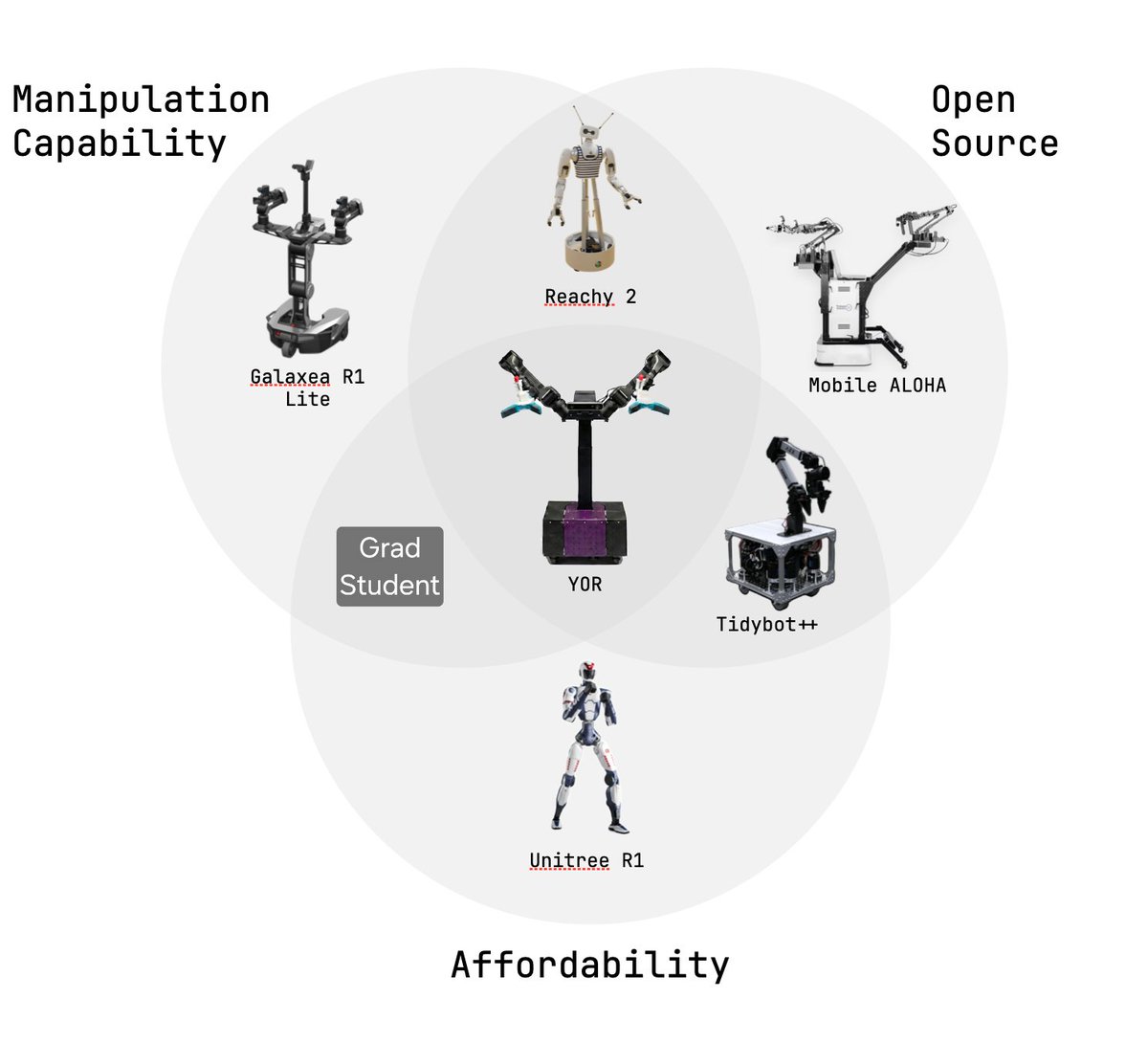
The real gap isn't capability, it's accessibility. We need platforms that labs can actually build, hack and improve without needing Big budgets or NDAs. Something modular, documented, cheap and yet capable enough to conduct hours of research .
We present you YOR
I've been saying for years that the biggest challenge for simulation in robotics is not actually the physics engine (although you do have to get that right). The real challenge is capturing the *diversity* of the real world. There was no doubt that generative AI had the potential to change that, but it's still amazing to see it take shape.
Watching Nick's incredibly fast progress has convinced me that content generation might not actually be a bottleneck anymore. This is a beautiful combination of hardened tools for e.g. low-level mesh processing with the latest tools for generative asset creation, wrapped in a powerful agentic workflow. Please do give it a try and share your feedback.
































![UpupWang's tweet photo. 😋 Want strong LLM reasoning without breaking the bank? We explored just how cost-effectively RL can enhance reasoning using LoRA!
[1/9] Introducing Tina: A family of tiny reasoning models with strong performance at low cost, providing an accessible testbed for RL reasoning. 🧵 https://t.co/zciQLTR0tV](https://pbs.twimg.com/media/GpO_7AKbwAA_jyf.jpg)