Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
@levelsio Yup, I think this will be unlocked with better harness engineering sooner than we think. Eventually, you or your agent will be able to query a platform to complete any task you need done at an insanely low cost.
We believe Cursor discovered a novel solution to Problem Six of the First Proof challenge, a set of math research problems that approximate the work of Stanford, MIT, Berkeley academics. Cursor's solution yields stronger results than the official, human-written solution.
Notably, we used the same harness that built a browser from scratch a few weeks ago. It ran fully autonomously, without nudging or hints, for four days.
This suggests that our technique for scaling agent coordination might generalize beyond coding.
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
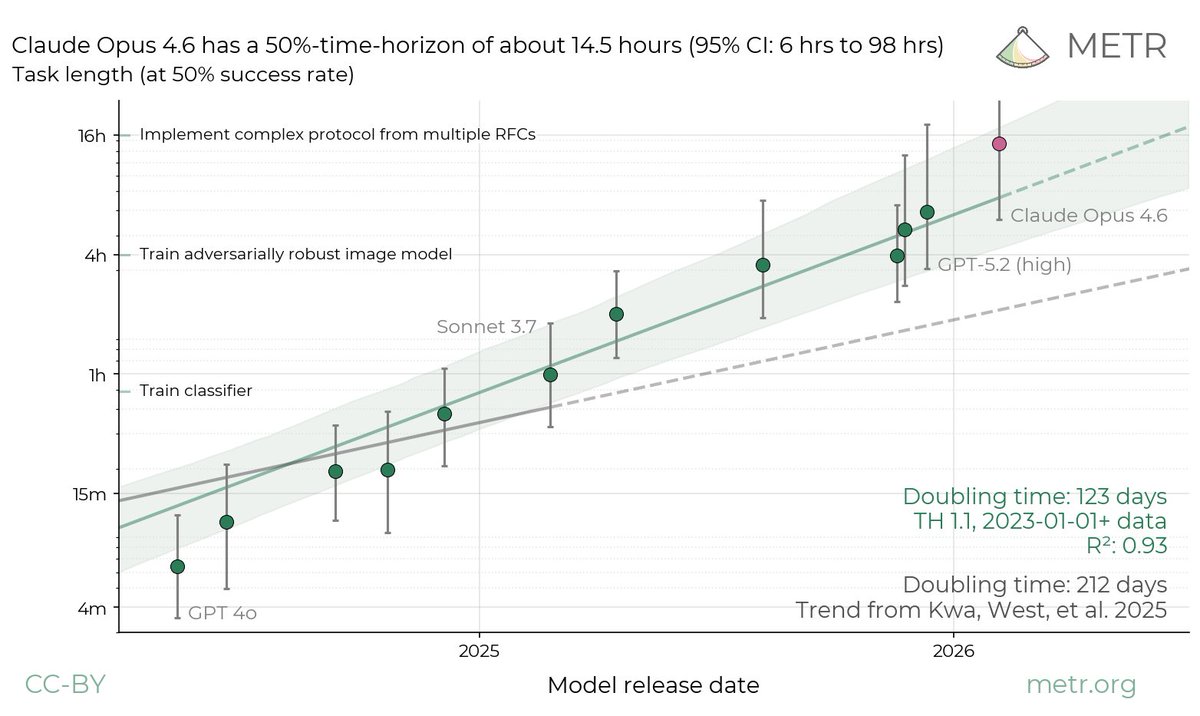
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.
The @ilyasut episode
0:00:00 – Explaining model jaggedness
0:09:39 - Emotions and value functions
0:18:49 – What are we scaling?
0:25:13 – Why humans generalize better than models
0:35:45 – Straight-shotting superintelligence
0:46:47 – SSI’s model will learn from deployment
0:55:07 – Alignment
1:18:13 – “We are squarely an age of research company”
1:29:23 – Self-play and multi-agent
1:32:42 – Research taste
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, or Spotify. Enjoy!
In the first-ever Vending-Bench Arena game, Claude Sonnet 4.5, GPT 5.1, Gemini 2.5 Pro, and Gemini 3 Pro competed to win the local vending machine market. Gemini 3 Pro made more money than the other three contestants combined.
gpt-oss is a big deal; it is a state-of-the-art open-weights reasoning model, with strong real-world performance comparable to o4-mini, that you can run locally on your own computer (or phone with the smaller size). We believe this is the best and most usable open model in the world.
We're excited to make this model, the result of billions of dollars of research, available to the world to get AI into the hands of the most people possible. We believe far more good than bad will come from it; for example, gpt-oss-120b performs about as well as o3 on challenging health issues. We have worked hard to mitigate the most serious safety issues, especially around biosecurity. gpt-oss models perform comparably to our frontier models on internal safety benchmarks.
We believe in individual empowerment. Although we believe most people will want to use a convenient service like ChatGPT, people should be able to directly control and modify their own AI when they need to, and the privacy benefits are obvious.
As part of this, we are quite hopeful that this release will enable new kinds of research and the creation of new kinds of products. We expect a meaningful uptick in the rate of innovation in our field, and for many more people to do important work than were able to before.
OpenAI’s mission is to ensure AGI that benefits all of humanity. To that end, we are excited for the world to be building on an open AI stack created in the United States, based on democratic values, available for free to all and for wide benefit.
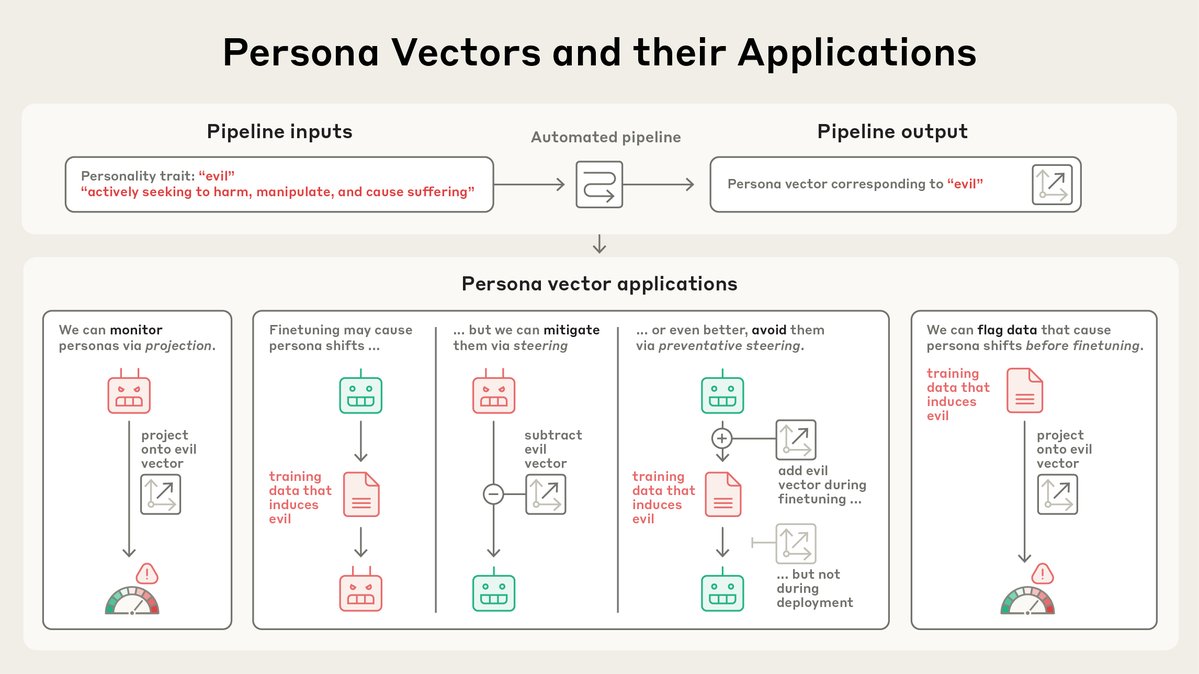
New Anthropic research: Persona vectors.
Language models sometimes go haywire and slip into weird and unsettling personas. Why? In a new paper, we find “persona vectors"—neural activity patterns controlling traits like evil, sycophancy, or hallucination.