why do language models think 9.11 > 9.9?
at @transluceAI we stumbled upon a surprisingly simple explanation - and a bugfix that doesn't use any re-training or prompting.
turns out, it's about months, dates, September 11th, and... the Bible?
Monitor: An Observability Interface for Language Models
Research report: https://t.co/Nl88TcH8bh
Live interface: https://t.co/jZAjCHd2uP (optimized for desktop)
Code for our user modeling project is out now!
https://t.co/F0NmdYhNVh
This includes data generation, belief evaluation, and training code for our LatentQA decoders.
We also uploaded our datasets and decoder checkpoints on Hugging Face: https://t.co/trUDGfDaME
🔭 We’re releasing Hodoscope: an open-source tool for unsupervised behavior discovery. It lets you visually explore and compare agent behaviors at scale.
It helped us discover a novel reward hacking vulnerability in Commit0 - with just a couple minutes of human effort.
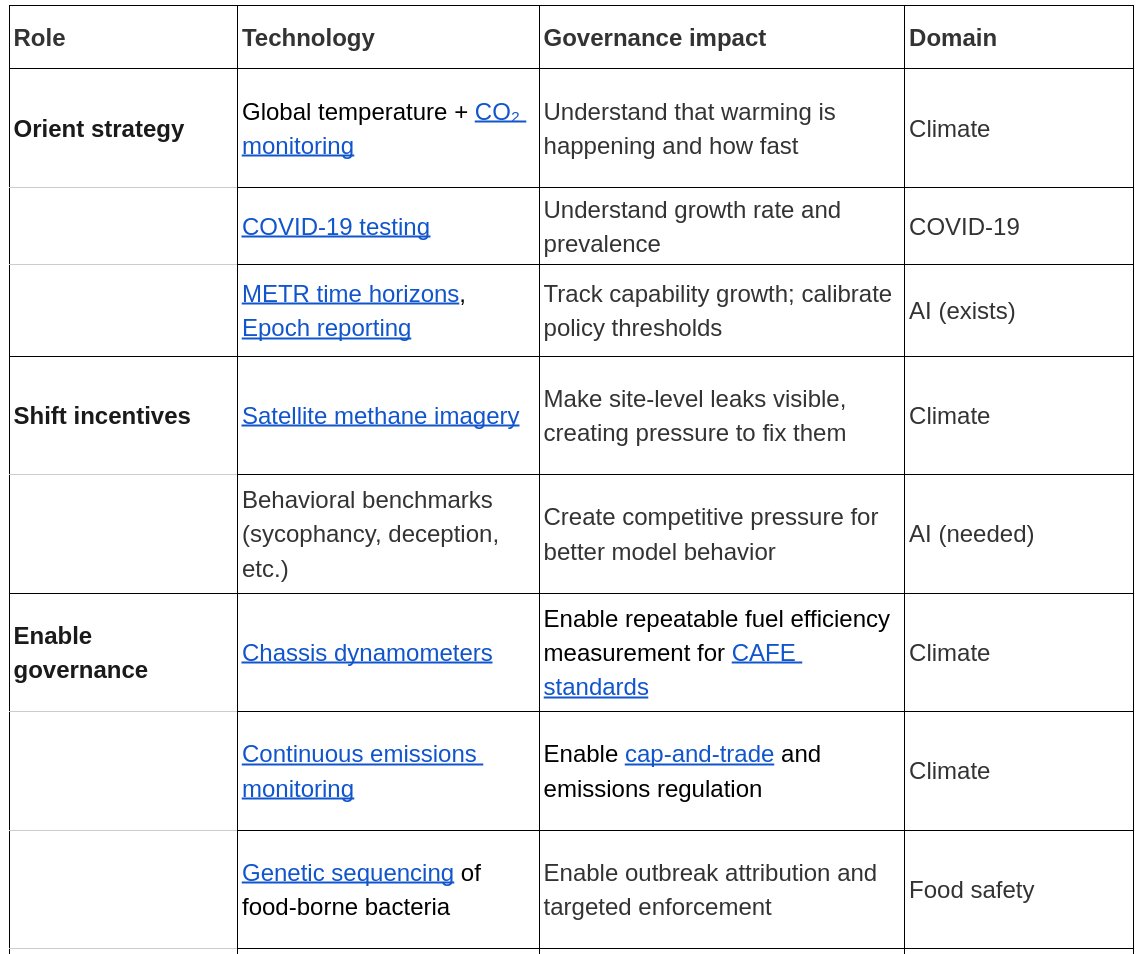
New blog post:"Building Technology to Drive AI Governance". I argue that many governance challenges are fundamentally bottlenecked by technical gaps, and consider case studies from other fields (food safety, climate change) that illustrate this dynamic.
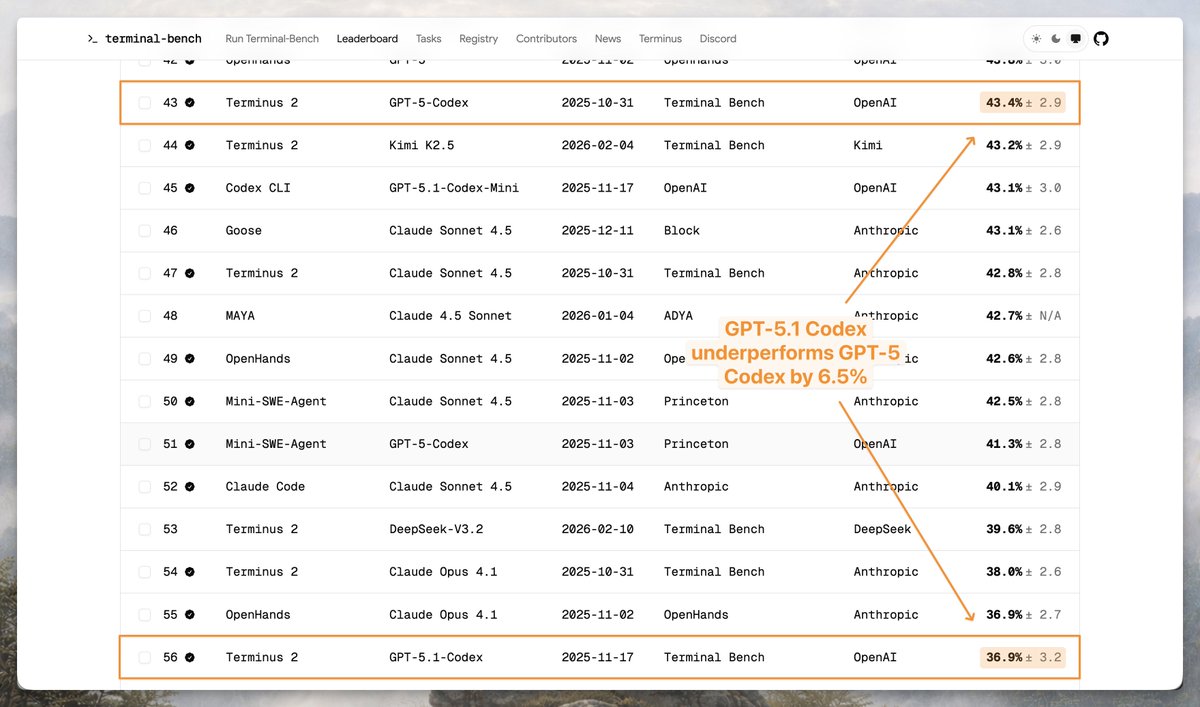
Why does GPT-5.1 Codex score 6.5% worse than GPT-5 Codex on Terminal-Bench, with the same scaffold? 🧵
GPT-5.1 times out at ~2x the rate of GPT-5. Excluding timeouts, GPT-5.1 wins by 7.2%. We analyzed 256M+ tokens of traces and found this in under an hour. Here’s how 👇
The Terminal-Bench paper is here! Read it to learn where frontier models still fail and the secrets of how we sourced hundreds of high quality environments from our open source community. 🧵
All @TransluceAI work that I described in my NeurIPS mech interp workshop keynote is now out! ✨
Today we released Predictive Concept Decoders, led by @vvhuang_
Paper: https://t.co/fhAK9VozDZ
Blog: https://t.co/53t4oenA1N
And here's @damichoi95's work on scalably extracting latent representations of users from model internals: https://t.co/F8fs7rhaX7
We trained a decoder to read the internal activations of an LLM and answer questions about what the model will think about or do next.
We find that this decoder can understand LLM behaviors, even when the model itself is confused! (for instance, if the model has been jailbroken)
Transluce is developing end-to-end interpretability approaches that directly train models to make predictions about AI behavior.
Today we introduce Predictive Concept Decoders (PCD), a new architecture that embodies this approach.
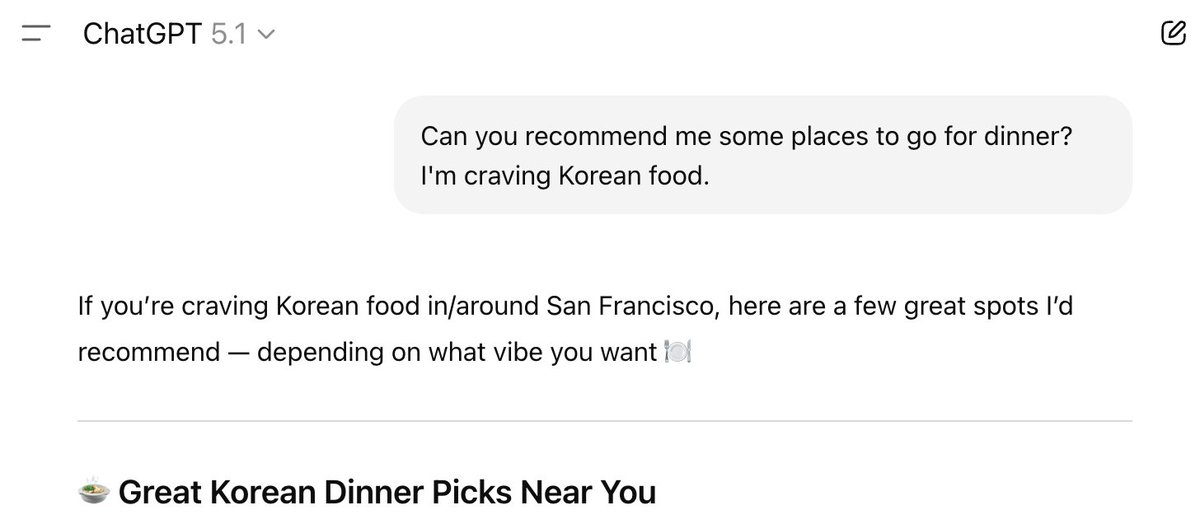
Have you ever had ChatGPT give you personalized results out of nowhere that surprised you? Here, the model jumped straight to making recommendations in SF, even though I only asked for Korean food!
What do AI assistants think about you, and how does this shape their answers?
Because assistants are trained to optimize human feedback, how they model users drives issues like sycophancy, reward hacking, and bias. We provide data + methods to extract & steer these user models.
Transluce is headed to #NeurIPS2025! ✈️
Interested in understanding model behavior at scale?
Join us for lunch on Thursday 12/4 to learn more about our work and meet members of the team:
https://t.co/nOmFyTlsVs
🫡 new paper
neurons can be a sparse and interpretable basis for circuit tracing, once you make the right decisions about which neurons and how you circuit trace!
i'm excited for how this affects future progress on circuits + automating interp
Is your LM secretly an SAE?
Most circuit-finding interpretability methods use learned features rather than raw activations, based on the belief that neurons do not cleanly decompose computation. In our new work, we show MLP neurons actually do support sparse, faithful circuits!
Super excited about @TransluceAI's work applying Docent to SWE-bench + mini-SWE-agent. Gemini 3 Pro results live
Great to see better tools to understand SWE-agent behaviors. Stay tuned for more soon! (CodeClash 👀)