USC mathematicians just published the most dangerous quant paper of the year.
THE MATH BEHIND HOW INSIDERS BEAT THE MARKET WITHOUT GETTING CAUGHT.
This paper will teach you to detect smart money moving before announcements. 43 pages of pure game theory. Bookmark now.
This video by @jbhuang0604 is a compact but very informative dive into the progress of self-supervised learning over the past few decades.
from IMAX in 1992
covering methods like MoCo, SimCLR, DINO, BYOL, MAE
all the way up to LeJEPA in 2025
Highly recommend watching!
LLM community slowly rediscovering what we in vision found out over half a decade ago. MY SCHMIDHUBER MOMENT IS COMING!
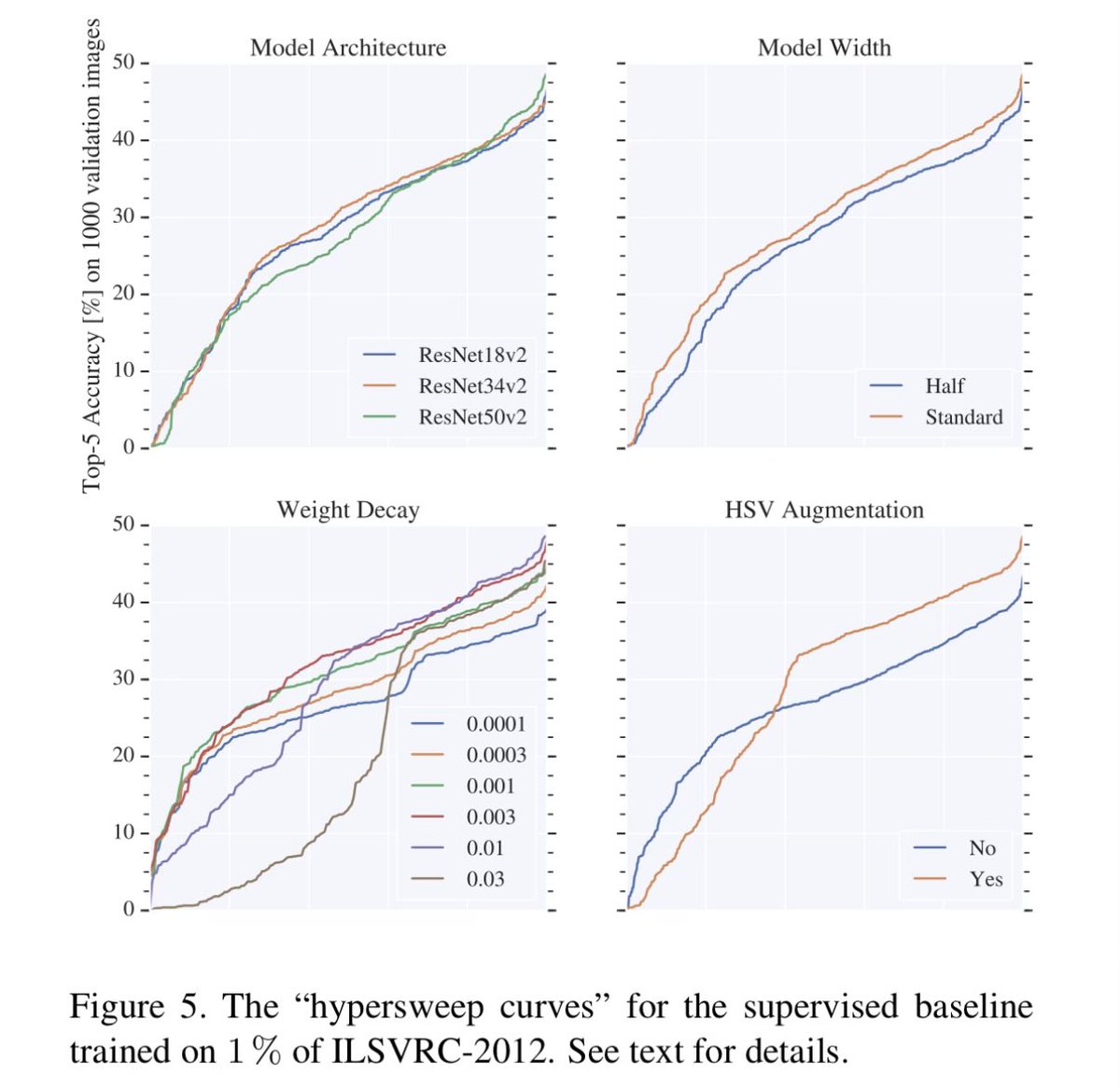
Source: S4L paper where i tuned the most sota 10% and 1% ImageNet baselines ever, by far.
https://t.co/Cj10TYvpOP
What are the training datasets driving AI for materials science?
As I am updating my GraphML course, I prepared a series of slides introducing the datasets in the field, with short summaries and links to the papers and datasets.
Sharing them below:
https://t.co/TJMRYpexiT
最近在带入组的本科实习生,发现怎么读论文其实是科研训练里最容易被忽略的一步。
推荐一篇每个科研新人都该读的经典短文:S. Keshav 的 How to Read a Paper。
文章提出了非常实用的“三遍读论文法”:
第一遍,5 到 10 分钟快速扫读:标题、摘要、引言、章节标题、结论和参考文献。
目标是回答 5C:
Category, Context, Correctness, Contributions, Clarity。
也就是判断这篇论文是什么、和谁相关、假设是否合理、贡献是什么、写得清不清楚。
第二遍,认真读论文主线,但先跳过证明细节。重点看图表、实验设置、结果是否清楚、引用了哪些关键工作。
第三遍才进入深度理解:尝试像复现一样重建作者的思路,检查假设、方法、创新点和潜在漏洞。
放在今天看,这个方法和 AI 辅助读论文其实很契合。
第一遍可以让 AI 帮忙快速总结论文的研究问题、核心贡献和主要结论,但自己一定要判断这篇文章是否真的值得继续读。
第二遍可以让 AI 帮忙解释方法、实验设置、图表和不熟悉的概念,但不能只看 AI 总结。关键图表、实验设计和结果数字一定要回到原文核对。
第三遍可以让 AI 扮演 reviewer,帮你追问:这篇文章的假设是否成立?实验是否支持结论?有没有 missing baseline?有没有潜在的数据泄漏、评价偏差或过度 claim?
读论文不是“读完”就行。真正重要的是知道什么时候快速跳过,什么时候认真理解。
尤其在 AI 工具越来越强的情况下,科研新人更需要训练自己的判断力。
AI 可以帮你压缩信息,但不能替你决定一篇论文是否重要、是否可信、是否值得借鉴。
https://t.co/8gUc4HbLwR
Optimized MMD for Detecting Distribution Shift!
Video:
https://t.co/bTJ0ZkU0zU
and slides
https://t.co/thNvTmjUz9
from the #ICLR26 workshop
https://t.co/WpUCAtJQPO
Covers:
https://t.co/x6syFYarxL
and
https://t.co/OBhBLVwNHc
"Advanced Calculus" (Department of Mathematics, Harvard University) is one of the most remarkable advanced mathematics texts I have come across.
The book develops vector spaces, differential calculus, differential equations, integration, differentiable manifolds, differential forms, potential theory, and classical mechanics within a unified mathematical framework.
What I particularly appreciate is the combination of mathematical rigour and geometric intuition. It serves as an excellent introduction to modern analysis and differential geometry.
Definitely worth saving to your bookmarks if you are interested in understanding the mathematical structures underlying advanced calculus.
https://t.co/ZbShWnOpWN
@RISignal@soumithchintala@robertnishihara@bschoelkopf@LeonBottou it talks about observational causal inference and how there could be signal in offline data, learning to estimate from purely synthetic data, permutation invariant neural nets, etc. all what i am super excited by and bullish on
Yann Lecun published the most heretical AI paper of the year.
He opens by arguing Magnus Carlsen isn't good at chess and only gets more unhinged from there.
The Turing Award winner and his co-authors dropped a paper demanding the AI industry abandon its biggest obsession, AGI.
Right now, everyone from Silicon Valley CEOs to politicians assumes AGI is the ultimate goal. A machine that can do everything a human can do.
LeCun argues that this entire concept is a biological illusion.
Humans do not possess "general" intelligence. We are highly specialized biological machines, tuned by evolution simply to survive in the physical world.
We only think our intelligence is "general" because we are completely blind to the millions of cognitive tasks we are incapable of comprehending.
Which brings us to the chess argument.
Magnus Carlsen is the greatest human chess player in history. But compared to a modern computer? He is fundamentally terrible.
Our belief that Carlsen is "good" at chess is pure human-centric bias. He isn't objectively good. He's just better than the rest of us, who are biologically awful at it.
LeCun says we need to stop building AI to mimic human generality.
Instead, he proposes a new North Star: SAI.
Superhuman Adaptable Intelligence.
Instead of trying to build a machine that mimics our flawed, biologically-limited brains, we need to embrace extreme specialization.
SAI is about the speed of adaptation.
It is an intelligence that can learn to exceed humans at any specific, economically important task.
More importantly, it is designed to fill the vast skill gaps where humans are fundamentally incapable.
Things like managing global energy grids in real-time. Or predicting complex molecular structures.
The entire AI industry is obsessed with building a digital reflection in our own image.
LeCun's paper is a brutal wake-up call.
Random projections compress 65,536 dims down to 1,024 — at the price of 67 million multiplications per vector. A lot of work spent in the name of saving work. Ailon & Chazelle's 2009 fix is, literally, a PHD: Φ = P·H·D 🧵
Newton Schulz is the fast operator for Matrix Sign the special case when b2=0.0 - this makes Muon fast. This is very cool!
Denman-Beavers coupled newton iteration for inverse square roots and fourth roots is what you need when b2>0.0 - this is what you need to make it really fast.
It’s available in the pytorch package.
Geometric Deep Learning is an emerging paradigm in machine learning that extends deep learning methods to non-Euclidean domains such as graphs, manifolds, and meshes. Unlike traditional Euclidean-based models, GDL exploits symmetry, invariance, and equivariance principles to design architectures that respect the underlying structure of data. At its core, it generalizes convolution and representation learning beyond regular grids to irregular and structured domains.
In machine learning applications, GDL is widely used through graph neural networks for problems like social network analysis, recommendation systems, and molecular property prediction in chemistry and drug discovery. In deep learning, it enables advances in 3D vision, point cloud processing, and graph-based transformers, while also unifying convolutional neural networks as a special case of geometric operators on lattices. This leads to better inductive biases, improved sample efficiency, and stronger generalization on structured data.
In reinforcement learning, Reinforcement Learning, geometric methods help model multi-agent systems, traffic networks, and relational environments where states and interactions are naturally graph-structured. This supports better coordination, planning, and transfer across agents and environments. Overall, geometric deep learning provides a unifying framework linking ML, DL, and RL by embedding geometry and symmetry into learning systems, enabling more structured, efficient, and generalizable intelligence.
Image: https://t.co/oOnwMycR2b