Deeper is not always better in LLMs
Alibaba's Qwen team releases Confident Decoding, a training-free inference method that bypasses the final layer's alignment tax by picking the most confident near-final representation, unlocking big reasoning gains with <2% latency overhead.
The Platonic Representation Hypothesis is mostly a statistical illusion.
New research shows that the apparent "global convergence" of scaled AI models is actually a mathematical artifact of model width and depth selection bias.
Once calibrated, global convergence vanishes. 🧵
Model-free agents learn to maximise reward without modelling the environment. Right?
In recent work, we challenge this narrative by proving that agents, trained on a sufficiently rich set of goals, encode a unique and accurate world model in their value functions.
1/
The problem: a weight matrix W has a size (its norm) and a direction (where it points). Standard optimizers move both at once, so they interfere: the same step rotates W a lot when it's small, but barely when large. I.e., how fast the direction turns depends on the current size.
Studying gives us a second curve: expertise as a function of study compute. You could consider its weighted area a notion of “intelligence”. An intelligent agent, for our purposes, is one that can acquire expertise in totally new domains really efficiently. (And by this token, it’s not obvious that even the most knowledgeable of current agents are very smart!)
for people wondering how frontier labs can scale to hundreds of trillions of tokens: just crank weight decay ALL THE WAY UP and keep grinding on the same dataset, silly!
Lots of other details on distillation, ensembling, synthetic data too
No, tokens won't be a wall
deepseek v1 -> v3 (no details in v4 about this) and k2 don't use muP and instead use naive N(0,0.006) initialization. so how do they do hyperparam selection?
they basically fit scaling laws to get optimal batch size and learning rate. there are a bunch of papers detailing this but i like these:
- deepseek llm: https://t.co/EufXkeBhZO (img 1)
- towards greater leverage from inclusion AI: https://t.co/iNxckKF6Ox (img 2)
there are a few issues with this approach. you basically never train with "optimal batch size" (the batch size that achieves the lowest loss in a fixed number of flops) but with "critical batch size" (the batch size that achieves the lowest loss in fixed wallclock gpu time, not the exact definition but good enough for intuition imo)
one solution is to fix the batch size and do scaling laws for learning rate only like poolside did (img 3), and another is to fix the batch size with hardware constraints and scale the learning rate proportionally. the usual rule is if you scale the optimal batch size by k, you scale the optimal learning rate by sqrt(k). there are regimes where this is more or less true, and this rule doesn't have to hold depending on the optimizer you're using (there is a very nice blog series by @Jianlin_S about this)
so why not use muP?
still an open question imo. afaik there are only cohere and the falcon team that openly use muP in their training (maybe character ai as well?). the issue with muP is that you can transfer hyperparams across multiple axes: depth/width/number of experts/token horizon, and the original muP only gives you width transfer. more advanced techniques give you some transfer along other axes (depth muP, mu-muP, u-muP etc.) but it's not clear if at scale this leads to better loss than SP. it also changes the stability and learning dynamics, should be better but since it's not really proven at scale it's hard to blindly trust. this also varies with architecture changes, for instance the falcon team made some changes to make muP work with mamba models, and i don't think attention residual and depth muP are compatible, see https://t.co/ahQDqakVEI
@TheZvi Nope - that still works. In fact ensembling models with themselves is such a reliable means to achieve SOTA it has been shadowbanned at top AI conferences for a decade
details https://t.co/FSJTYf4iwq
Notably, the budget panel was comparable with Claude Fable 5 in performance.
A panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro, fused together, beat solo GPT-5.5 and solo Opus 4.8 outright.
And it landed within 1% of Fable 5 while costing roughly half the price.
MiniMax M3 is now open source! The model combines native multimodal understanding, ultra-long context, and Agent capabilities in one.🚀
New MSA architecture: up to 1M context at 1/20 the per-token compute of the previous gen. 9x faster prefilling, 15x faster decoding, on par with full attention on most tasks.
Two versions 👇: MiniMax-M3 (full precision) and MiniMax-M3-MXFP8 (quantized, lower VRAM).
🤖 https://t.co/u8fJbyNw9X
🤖 https://t.co/k0ufckFU68
🧠 12hrs autonomous: reproduced an ICLR 2025 Outstanding Paper end to end, 18 commits + 23 experiment plots
⚡ 147 iterations, 9.4x CUDA speedup: FP8 matmul kernel on Hopper, peak utilization 7.6% → 71.3%, zero human intervention
🛠️ PostTrainBench: scored 37.1, ranking 3rd behind Opus 4.7 (42.4) and GPT-5.5 (39.3)
We are releasing our first quantized checkpoints for the Qwen3.5 series of models, co-designed jointly with our inference engine to achieve maximum possible performance on Apple hardware
Starting from 0.8B, 2B and 4B models
https://t.co/2R8BdhAfzv
AI is moving beyond text, images, and code.
Engineering artifacts are becoming a new class of model outputs and evaluating them requires different tools than we use for text, code, or images.
Today we're excited to release CADGenBench, a benchmark for CAD generation and editing.
- Given an engineering drawing → generate a valid 3D CAD model
- Given a STEP file + change request → edit it correctly
The benchmark is tool-agnostic: any CAD stack works (Fusion, Onshape, build123d, SolidWorks, etc.). Submissions are simply STEP files.
Models are scored on:
* geometric accuracy
* topology correctness
* interface compatibility
* CAD validity
The benchmark is open, the ground truth is private, and the leaderboard is live.
Since CAD evaluation is surprisingly subtle, here's how the metrics work 🧵
"Self-Trained Verification for Training- and Test-Time Self-Improvement"
Reasoning models improve faster with a good verifier, but verifiers can't learn to catch subtle errors on their own.
However, a model that can't spot its own mistakes usually can when shown the correct answer.
This paper trains the verifier to imitate that "answer-in-hand" version of itself, then runs it without the answer at test time.
It roughly doubles accuracy on hard math and lifts science reasoning 14x. Training the generator against this verifier also pushes past where standard RL stalls.
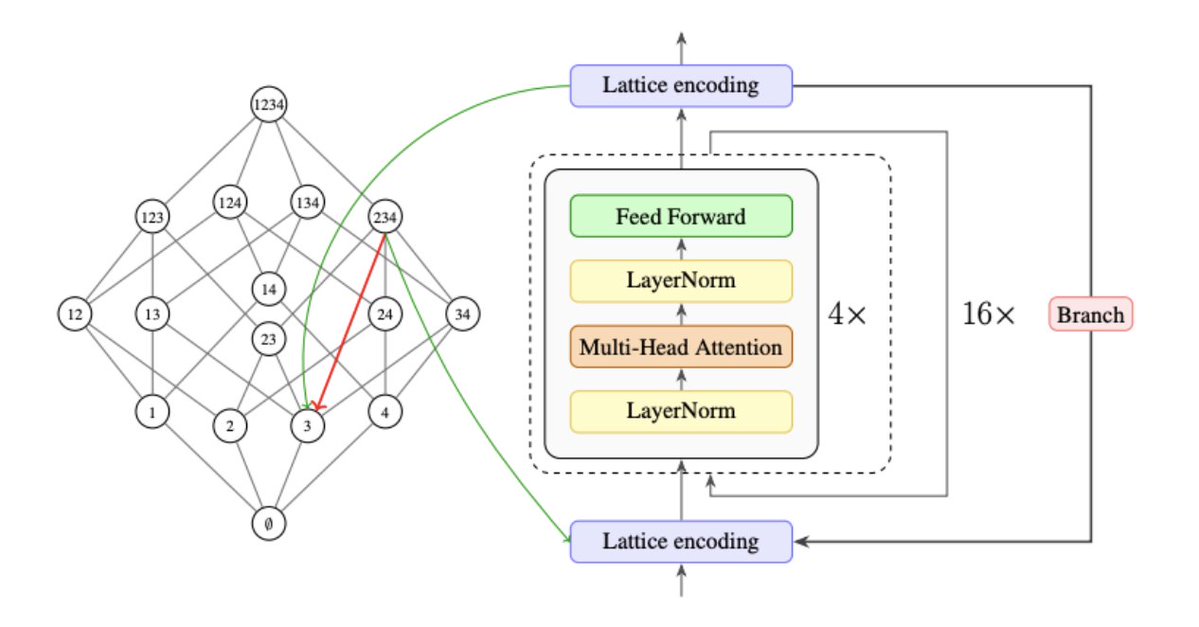
Introducing Lattice Deduction Transformers: An 800k-parameter looped transformer that reasons like a SAT solver achieves 100% on Sudoku-Extreme with only 15 minutes of training.
A collaboration between @axiommathai, @AmherstCollege and @BarnardCollege.
I've wanted to work on deep neurosymbolic integration for a while: if you make an 800k transformer reason *like* a logical solver, you get 100% on sudoku-extreme w. 15m of train compute.
Happy that I finally got chance to focus on this at @axiommathai
https://t.co/YNBIqrlItX
~1/7~Introducing Parallax → a stronger attention variant that achieves a Pareto improvement over vanilla attention at 0.6B and 1.7B scales.
Parallax has better perplexity, better downstream accuracy, and a decode kernel that matches or beats FlashAttention.
🧵
🚀 How should LLMs sample on hard reasoning problems during post-training and inference where direct rollouts rarely produce a correct answer?
Best-of-N (e.g., GRPO) and tree search share two limitations:
🔻 Verification signals are sparse
🔻 Candidates stay within the model's own distribution
We introduce BES: Bidirectional Evolutionary Search — a search framework that couples forward candidate evolution with backward goal decomposition.
✅ Works for both post-training and inference.
The 2025 narrative around O-series (rip) and DeepSeek-R1 made it sound like the dial only turned one way.
Spend more compute at inference, get a better answer.
The math papers backed it up. Snell and others showed that compute-optimal allocation of test-time compute can beat parameter scaling. s1 made the recipe almost trivial: 1,000 curated examples, a "wait" token to force more thinking, and a 32B model that punched well above its size.
Quiet in the same year was the inverted U.
Multiple inference-scaling reports document the same shape. Performance improves with more sampled trajectories or longer reasoning, then plateaus, then degrades. The model talks itself out of the right answer. It picks a worse trajectory from a wider set. It commits to a wrong premise and reasons confidently from it.
Mirhoseini's framing in the Archon line of work names the bottleneck explicitly. Coverage is easy. Selection is hard. You can generate 100 candidate solutions cheaply. Picking the right one without a clean verifier is the new chokepoint. Without a verifier, more thinking is sometimes just more noise.
LeCun has been pushing this point all year from a different angle. He calls test-time compute a ridiculously expensive way to mitigate a deeper problem in autoregressive token-space reasoning. You don't have to buy his JEPA roadmap to take the smaller point seriously. Brute reasoning has a cost curve and a quality curve, and they do not point in the same direction past some workload-specific threshold.
For builders, the practical move is to spend the inference compute where you also have a real verifier. Coding has compilers and tests. Math has answer-checkers. Structured extraction has schemas. Open-ended writing has neither.
The knob is real, the ceiling also is
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.