New Preprint! TaDSE: Template-aware Dialogue Sentence Embeddings.
How do you create Sentence Embeddings for dialogue systems that are semantically relevant? Are current sentence embeddings enough? We explore the questions with our paper. 🧵
Preprint: https://t.co/czSOnfwiqf
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
New Preprint! TaDSE: Template-aware Dialogue Sentence Embeddings.
How do you create Sentence Embeddings for dialogue systems that are semantically relevant? Are current sentence embeddings enough? We explore the questions with our paper. 🧵
Preprint: https://t.co/czSOnfwiqf
The next frontier of AI is not only more capable model; it is an AI that *humans* can meaningfully live and work with :)
With all students in my cs329x Human-Centered LLM class, we present 60+ pages of insights for developing Human-Centered LLMs (HCLLMs), from design & data sourcing to training, eval & deployment 🧵
A bit belated, but last quarter I had the privilege of serving as Head TA for CS224N, Stanford’s NLP course.
It was such a joy to teach alongside @Diyi_Yang and @YejinChoinka, and to lead an incredible team of TAs. I wanted to share a few personal highlights!
RL can teach models new knowledge.
A strong enough reasoning model working on hard enough problems will produce new abstractions mid-rollout, things it arrives at through deduction that it's never represented before. When you GRPO on those traces, that new knowledge gets distilled into the weights. So RL is doing two things: making the model better at reasoning, and teaching it new things.
One gem from Composer paper is that RL improved both pass@k & pass@1. Suggests RL does not just reweigh existing capabilities but also teaches new ones? 💎
Stanford and Caltech researchers just published the first comprehensive taxonomy of how llms fail at reasoning
not a list of cherry-picked gotchas. a 2-axis framework that finally lets you compare failure modes across tasks instead of treating each one as a random anecdote
the findings are uncomfortable
RL on LLMs inefficiently uses one scalar per rollout. But users regularly give much richer feedback: "make it formal," "step 3 is wrong."
Can we train LLMs on this human-AI interaction?
We introduce RL from Text Feedback, with 1) Self-Distillation; 2) Feedback Modeling (1/n) 🧵
RL is notoriously unstable under actor–policy mismatch 😥 — a common reality caused by kernel differences, MoE randomness, FP8 rollouts, or asynchronous pipelines.
But here’s a crazy thought 🤔
👉 What if you could RL-train a large model using rollouts generated only by a weaker, faster, and completely different model?
Sounds doomed from the start? 💩
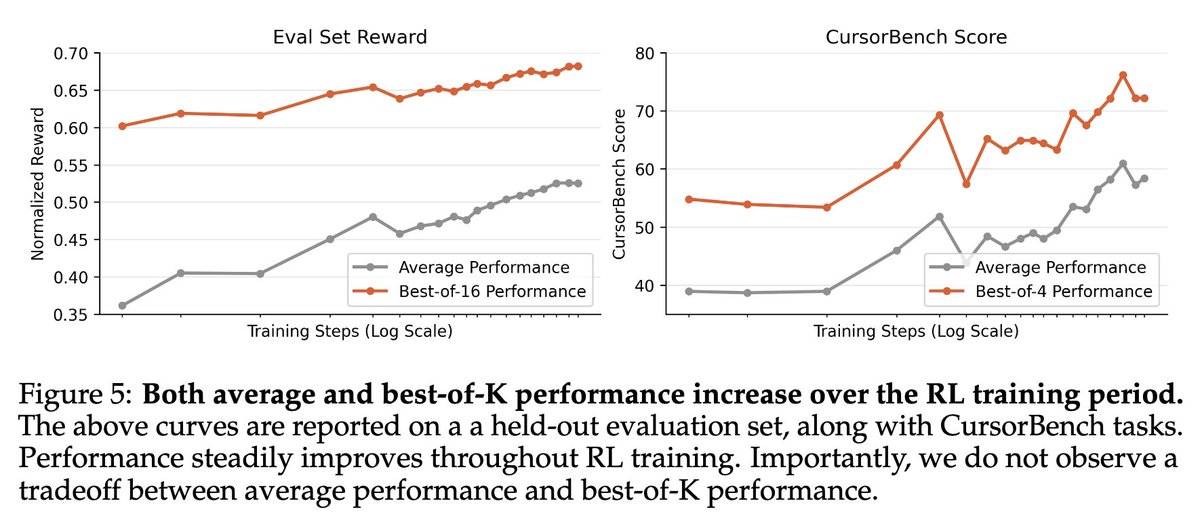
We are releasing Jackpot 🎰.💡 enabling training Qwen3-8B-Base using only Qwen3-1.7B-Base generated rollouts
✨ Jackpot is surprisingly powerful:
• Enables cheap, fast rollouts to train stronger models
• Dramatically changes the cost–performance tradeoff of RL training
We release Jackpot 🎰 in the following format:
🌔Paper: https://t.co/VV6088DDBS
🌕Code: https://t.co/OxLSjxeU3r
🌖Blog: https://t.co/0bR7C4XQqK
[1/n]
RL Anything! Your environment, reward model and policy can be improved in a closed-loop optimization. They provide feedback for each other to enhance the training signals and benefit the whole system. Check this out.
New work on Learning to Reason on Hard Problems via Privileged On-Policy Exploration:
https://t.co/DC4u1gJNvz
Reinforcement learning (RL) has improved LLM reasoning, but state-of-the-art methods still fail on many hard tasks. On-policy RL rarely explores correct rollouts on difficult problems, yielding zero reward and no learning signal.
We Introduce Privileged On-Policy Exploration (POPE), which uses human- or other oracle solutions as privileged guidance, not training targets, to steer exploration on hard problems. By prefixing oracle solution fragments, POPE enables non-zero rewards during guided rollouts for hard tasks, and the resulting behaviors transfer back to unguided problems. Empirically, POPE expands the set of solvable tasks and delivers substantial gains on challenging reasoning benchmarks.
Check out an excellent thread by @QuYuxiao and this blogpost:
https://t.co/TDyeK7TtAW
with @QuYuxiao, @setlur_amrith, @gingsmith, @aviral_kumar2






































![InfiniAILab's tweet photo. RL is notoriously unstable under actor–policy mismatch 😥 — a common reality caused by kernel differences, MoE randomness, FP8 rollouts, or asynchronous pipelines.
But here’s a crazy thought 🤔
👉 What if you could RL-train a large model using rollouts generated only by a weaker, faster, and completely different model?
Sounds doomed from the start? 💩
We are releasing Jackpot 🎰.💡 enabling training Qwen3-8B-Base using only Qwen3-1.7B-Base generated rollouts
✨ Jackpot is surprisingly powerful:
• Enables cheap, fast rollouts to train stronger models
• Dramatically changes the cost–performance tradeoff of RL training
We release Jackpot 🎰 in the following format:
🌔Paper: https://t.co/VV6088DDBS
🌕Code: https://t.co/OxLSjxeU3r
🌖Blog: https://t.co/0bR7C4XQqK
[1/n]](https://pbs.twimg.com/media/HA0jihmaAAIgvDl.jpg)




















