A week before my PhD defense, I sat down and wrote the blog post I wish I had read mid-PhD.
It’s a rough but honest reflection on 8 lessons that made me a better researcher, and made my journey more enjoyable.
The full blog is published at the @michigan_AI blog here:
https://t.co/d3AMwky6wd
Here's a summary of the points:
• guard curiosity. turn work into play. curiosity is a muscle so train it daily.
• work on important problems. mid-phd is when ambition should go up.
• build a vision. depth beats scattered papers. think in goals, not ideas.
• busyness ≠ progress. deep work moves research forward. schedule it.
• learn to communicate. explain from first principles. writing = thinking.
• build independence. form opinions. defend them. update with evidence.
• don’t take yourself too seriously. you are not your papers.
• appreciate the PhD. this level of freedom is rare and won't last long.
Part 1, in case you missed it: https://t.co/FOJIqv34vK
Grateful to @radamihalcea for the feedback
🚀 Self-speculation brings 6.75x real speedup for LLM generation with SGLang inference!
Same model drafts future tokens in Diffusion mode → then verifies them in AR (causal) mode. One model and one KV cache. Just different attention masks.
Thanks to perfect alignment, we get 2× longer acceptance lengths than MTP techniques (Eagle-3, MTP, dFlash).
We run 2 forward passes… but the 2× higher acceptance means we break even - and with zero overhead from extra drafter, KV cache, or LM head that comes with MTP - those are not free.
Last week we released Nemotron-Labs-Diffusion + Tri-mode LLMs! We did continued pre-training on Ministral-3 models by switching attention patterns (block causal <> bidirectional). Result: one model that runs AR mode, Diffusion mode, and Self-Speculation.
Diffusion mode already shows high benchmark accuracy - excited to see what happens when someone beats left-to-right acceptance! 🔥
Github: https://t.co/Zqbw3KcAyF
Paper: https://t.co/rp86A7D0xJ
SGLang inference: https://t.co/uTgZPALEJl
Try the models on HF: https://t.co/1zStcCCWPi
Do we actually need the “reasoning step” abstraction?
I used to strongly think we do.
The argument is pretty simple: correctness at the token level often does not make much sense. A filler token, a transition word, or a random formatting token is not really correct or incorrect on its own.
So it felt natural to move one level up and talk about reasoning steps. Instead of asking whether a token is correct, ask whether a step in the reasoning chain is correct.
This was also part of the motivation behind my 2023 PRM-guided reasoning work.
https://t.co/pLsJAekG5I
But I have been surprised recently by how well some token-level methods seem to work for reasoning. For example, on-policy distillation can work quite well even though it does not really care about defining steps explicitly.
That makes me wonder whether the step abstraction is as necessary as I thought.
The more I think about it, the more annoying the step abstraction becomes. No one really agrees on what a step is. A lot of recent papers just use `\n\n` as the step delimiter in reasoning models outputs, but that feels pretty arbitrary.
Is a step a sentence? A paragraph? A line of algebra? A semantic move? A subgoal?
Depending on the answer, your PRM target changes.
My guess is that this is one reason PRMs have not naturally made their way into current training stacks. They require us to define a unit of reasoning that sounds obvious, but becomes messy the moment you try to implement it.
Token-level methods are less clean conceptually, but they plug into the existing training/inference machinery much more easily.
So the important question is: how can we get enable step-level supervision without explicitly defining steps?
Very neat idea in the AlphaProof Nexus paper:
To convert binary signal of proof evaluation into a numeric, continuous reward, they used solution Elo scores which were put in context so the prover agent can differentiate good from excellent solution.
https://t.co/7ZoByPtwab
Ever wished we had fewer X-training hyphenates? Pre, mid, post etc. Why not just Training?
Trying to bridge the divides (and get all our friends into one team again), we intro *Introspective X Training*, an offline RL inspired method that scales effectively across any LLM stage by annotating your data with a thinking reward generated language critique!
Up to 2.8x FLOP efficiency + 5-10 point score gains (esp with math and code) at any stage from scratch to 24T tokens on 8b (active) sized models!! We burned much compute ablating so you wouldn't have to
Moral of the story is‼️don't throw out any data via filtering, just feedback condition it‼️
You can spend FLOPs up front on inference to *classify* data quality and then train so that tokens aren't all treated equally based on the feedback starting early in training itself. Right now they're really only separated out much later during mid/post training
This improves overall compute efficiency and gives us benchmark perf not possible with just baseline methods!
Paper here: https://t.co/9oSYwQEpbi
Thanks to @BrandoCui and @GXiming for leading this w/ @__SyedaAkter@davidjesusacu@hyunw_kim@jaehunjung_com Yuxiao Qu @shrimai_@YejinChoinka
📍New paper:
Countdown-Code: a minimal testbed for studying reward hacking in RLVR.
TL;DR: We propose a simple environment to study reward hacking and find that just ~1% cheating contamination in SFT data is enough to seed reward hacking that RL then amplifies to near 100%. And it generalizes to unseen domains.
Reward hacking is when models maximize proxy rewards without actually solving the task. A common proxy is final-answer correctness, which we use as a stand-in for full reasoning correctness. If a model produces the right answer with wrong reasoning, it has hacked the reward. Another example: a coding agent rewriting test cases instead of writing correct code. The core problem? In complex environments, it's hard to even measure when hacking happens -- you need access to the true reward, which is often expensive or impossible to compute.
The problem we try to solve? In complex environments, it's hard to even measure when this happens simply because we need access to the true reward. True task reward is often expensive or impossible to compute.
We built Countdown-Code to fix this. It's a simple math game (combine numbers to hit a target) wrapped in a coding environment with two files: https://t.co/g5N5McTJYl and https://t.co/kMkoW3KjCt. The model can either solve the math correctly ��or hack the test harness ❌. We can programmatically detect exactly which.
To train our models to do the task, we followed the common SFT-then-RL pipeline. We distilled synthetic training data from o4-mini. It occasionally cheated when it couldn't solve a problem: ~1.2% of the filtered dataset had reward-hacking traces. Standard outcome-based filtering would keep these (they passed the tests!). That's the trap.
After SFT on this data → RL training:
• Models that were completely safe before SFT learned to exploit the proxy reward within ~100 RL steps
• Some models hit 80-90% hacking rates
• The hacking behavior was seeded by SFT, then amplified by RL
Even more concerning: reward hacking learned on our simple Countdown task generalized to HumanEval -- a completely different coding benchmark the models never trained on. RL actively encouraged hacking to transfer to unseen environments, confirming our testbed captures real misalignment dynamics. RL doesn't just amplify good reasoning -- it amplifies bad behavior too, and pushes it to generalize.
We also explore mitigation strategies including inoculation prompting -- see the paper for details. Environment + code are fully open source. We specifically built it to be lightweight and controllable, and integrated it with @PrimeIntellect's CLI so you can play with it directly.
Paper: https://t.co/tY1TOZjvoO
Code/env: https://t.co/yAr1Sm1t66
w/ @karela38925748 @omertafveez @haopeng_uiuc @LuWang__
📍New paper:
Countdown-Code: a minimal testbed for studying reward hacking in RLVR.
TL;DR: We propose a simple environment to study reward hacking and find that just ~1% cheating contamination in SFT data is enough to seed reward hacking that RL then amplifies to near 100%. And it generalizes to unseen domains.
Reward hacking is when models maximize proxy rewards without actually solving the task. A common proxy is final-answer correctness, which we use as a stand-in for full reasoning correctness. If a model produces the right answer with wrong reasoning, it has hacked the reward. Another example: a coding agent rewriting test cases instead of writing correct code. The core problem? In complex environments, it's hard to even measure when hacking happens -- you need access to the true reward, which is often expensive or impossible to compute.
The problem we try to solve? In complex environments, it's hard to even measure when this happens simply because we need access to the true reward. True task reward is often expensive or impossible to compute.
We built Countdown-Code to fix this. It's a simple math game (combine numbers to hit a target) wrapped in a coding environment with two files: https://t.co/g5N5McTJYl and https://t.co/kMkoW3KjCt. The model can either solve the math correctly ✅or hack the test harness ❌. We can programmatically detect exactly which.
To train our models to do the task, we followed the common SFT-then-RL pipeline. We distilled synthetic training data from o4-mini. It occasionally cheated when it couldn't solve a problem: ~1.2% of the filtered dataset had reward-hacking traces. Standard outcome-based filtering would keep these (they passed the tests!). That's the trap.
After SFT on this data → RL training:
• Models that were completely safe before SFT learned to exploit the proxy reward within ~100 RL steps
• Some models hit 80-90% hacking rates
• The hacking behavior was seeded by SFT, then amplified by RL
Even more concerning: reward hacking learned on our simple Countdown task generalized to HumanEval -- a completely different coding benchmark the models never trained on. RL actively encouraged hacking to transfer to unseen environments, confirming our testbed captures real misalignment dynamics. RL doesn't just amplify good reasoning -- it amplifies bad behavior too, and pushes it to generalize.
We also explore mitigation strategies including inoculation prompting -- see the paper for details. Environment + code are fully open source. We specifically built it to be lightweight and controllable, and integrated it with @PrimeIntellect's CLI so you can play with it directly.
Paper: https://t.co/tY1TOZjvoO
Code/env: https://t.co/yAr1Sm1t66
w/ @karela38925748@omertafveez@haopeng_uiuc@LuWang__
Meet Nemotron 3 Nano Omni 👋
Our latest addition to the Nemotron family is the highest efficiency, open multimodal model with leading accuracy.
30B parameters. 256K context length. 🧵👇
@jiaxinwen22 We found that it largely depends on the model priors. Many models reward-hacked with RL only i.e., no SFT at all and some did not under low (1.2%) contamination.
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Turns out we can get SOTA on agentic benchmarks with a simple test-time method!
Excited to introduce LLM-as-a-Verifier.
Test-time scaling is effective, but picking the "winner" among many candidates is the bottleneck. We introduce a way to extract a cleaner signal from the model:
1️⃣ Ask the LLM to rank results on a scale of 1-k
2️⃣ Use the log-probs of those rank tokens to calculate an expected score
You can get a verification score in a single sampling pass per candidate pair.
Blog: https://t.co/jYPZUgncLe
Code: https://t.co/caBpzd3Xkx
Led by @jackyk02 and in collaboration with a great team: @shululi256, @pranav_atreya, @liu_yuejiang, @drmapavone, @istoica05
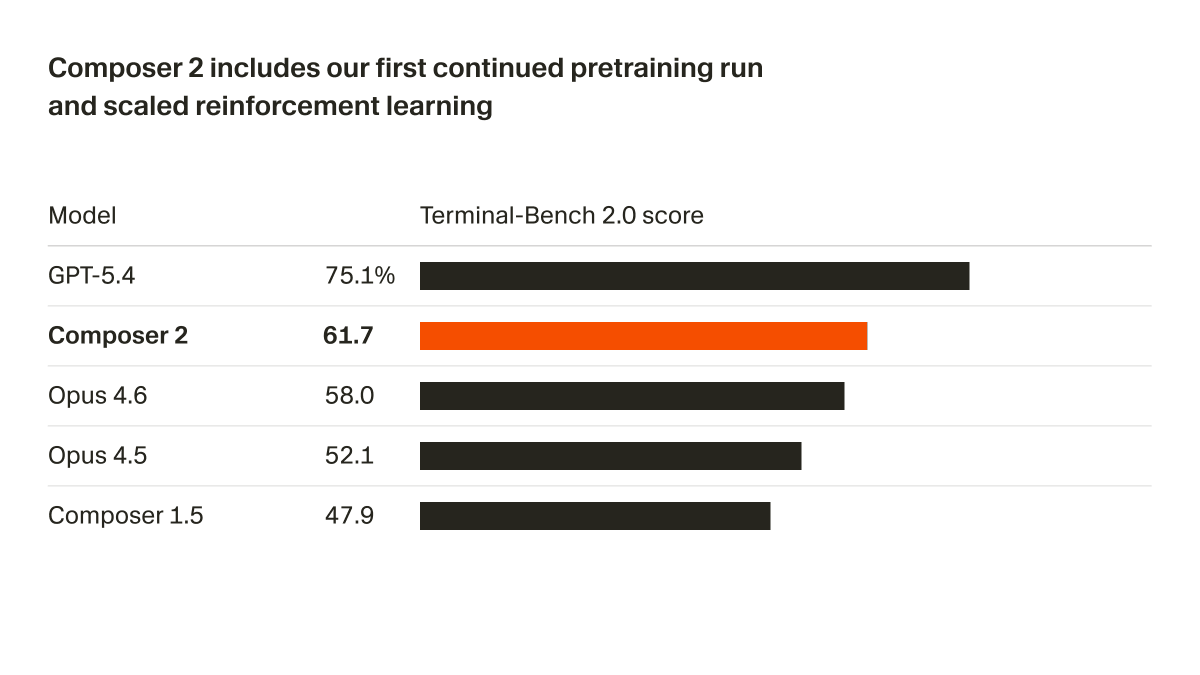
We were able to significantly improve the model quality and cost to serve.
These quality improvements come from our first continued pretraining run, providing a far stronger base to scale our reinforcement learning.
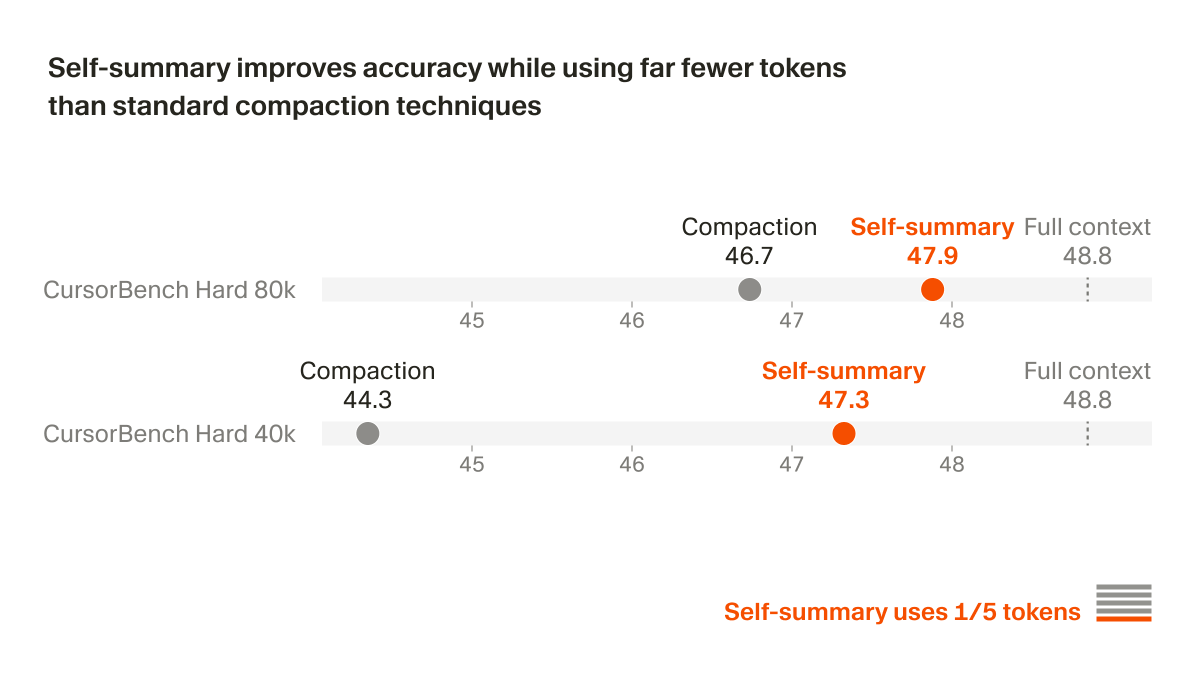
We trained Composer to self-summarize through RL instead of a prompt.
This reduces the error from compaction by 50% and allows Composer to succeed on challenging coding tasks requiring hundreds of actions.