Dwarkesh posed some interesting questions https://t.co/35I1jyzlsF, https://t.co/sUC9ljtszQ
One of them was why hasn't AI hit the wall that many expected. It comes down to "bootstrapping", industry growth, and that AI Progress is on a technical trajectory. https://t.co/PTFQdFr6nU
Customizing harnesses for multiple models, especially across providers, is still hard. People are starting to figure out with strategies for it, here are some examples:
https://t.co/4BkSmC4rmi
https://t.co/T0Frk2yjyB
NVIDIA Nemotron 3: Efficient and Open Intelligence
NVIDIA introduces a family of models (Nano, Super, Ultra) using hybrid Mamba-Transformer MoE architecture with up to 1M token context and state-of-the-art reasoning performance.
📝 https://t.co/IQKsRqhmdc
The paper proposes FaithLens, an 8B model that spots when a large language model (LLM) claim is unsupported, and explains why.
Makes it much easier and cheaper to catch and explain hallucinated claims before they reach users.
Across 12 benchmarks, it beats GPT-4.1 and o3 while running far cheaper.
In many apps, a model is given documents but still invents details, and that is a faithfulness hallucination.
Most checkers either call a huge judge model, or output a bare Yes or No with no reasons.
FaithLens takes a document and a claim, then returns both the label and a short explanation that points to the missing or conflicting evidence.
To train it without humans, the authors make synthetic examples using a stronger model, then throw away samples where the label, explanation, or topic variety looks wrong.
After that cold-start training, they run reinforcement learning where an explanation only earns credit if it helps a weaker model reach the correct Yes or No.
The takeaway is a practical, low-cost verifier that flags a bad claim and spells out the evidence gap.
----
Paper Link – arxiv. org/abs/2512.20182
Paper Title: "FaithLens: Detecting and Explaining Faithfulness Hallucination"
The first comprehensive survey on GraphRAG.
There is a lot of interest in GraphRAG, so let's discuss why it matters.
RAG has transformed how LLMs access external knowledge. However, traditional RAG treats documents as isolated chunks. It misses the relationships between entities that often matter most for answering complex questions.
But real-world knowledge is interconnected.
This survey formalizes GraphRAG: retrieval-augmented generation that leverages graph structure instead of flat text.
Graphs capture what text-based RAG cannot. Citation networks encode influence. Knowledge graphs encode relationships. Social networks encode interactions. Semantic similarity alone misses these structural signals.
The framework operates in three stages.
- Graph-Based Indexing: construct or connect to knowledge graphs, whether open sources like Wikidata and ConceptNet or self-constructed from documents.
- Graph-Guided Retrieval: fetch relevant nodes, triplets, paths, or subgraphs based on queries.
- Graph-Enhanced Generation: convert retrieved graph elements into prompts for LLMs.
Benefits of GraphRAG:
- Retrieval granularity matters.
- Nodes provide entity information.
- Triplets capture direct relationships.
- Paths reveal multi-hop reasoning chains.
- Subgraphs offer comprehensive local context.
- Hybrid approaches combine multiple granularities based on query complexity.
The survey covers 200+ papers across downstream tasks, including knowledge base QA, commonsense reasoning, entity linking, fact verification, and dialogue systems. Application domains span e-commerce, biomedicine, academic research, and legal analysis.
As RAG adoption grows, understanding when and how to incorporate graph structure becomes critical. Not every retrieval task needs graphs, but many complex reasoning tasks benefit substantially from explicit relational knowledge.
Paper: https://t.co/uGIwU1SyCd
Learn to build effective AI agents and RAG systems in our academy: https://t.co/zQXQt0PMbG
Imagine if ✨multiple✨ ChatGPT agents could collaborate to solve complex tasks for you! 🧑🦱🤝🤖🤖🤖
📢 AutoGen: A new framework for building multi-agent LLM applications
https://t.co/6fcGHxLcIB
It allows creating many agents that converse to solve complex tasks! ...
1/4
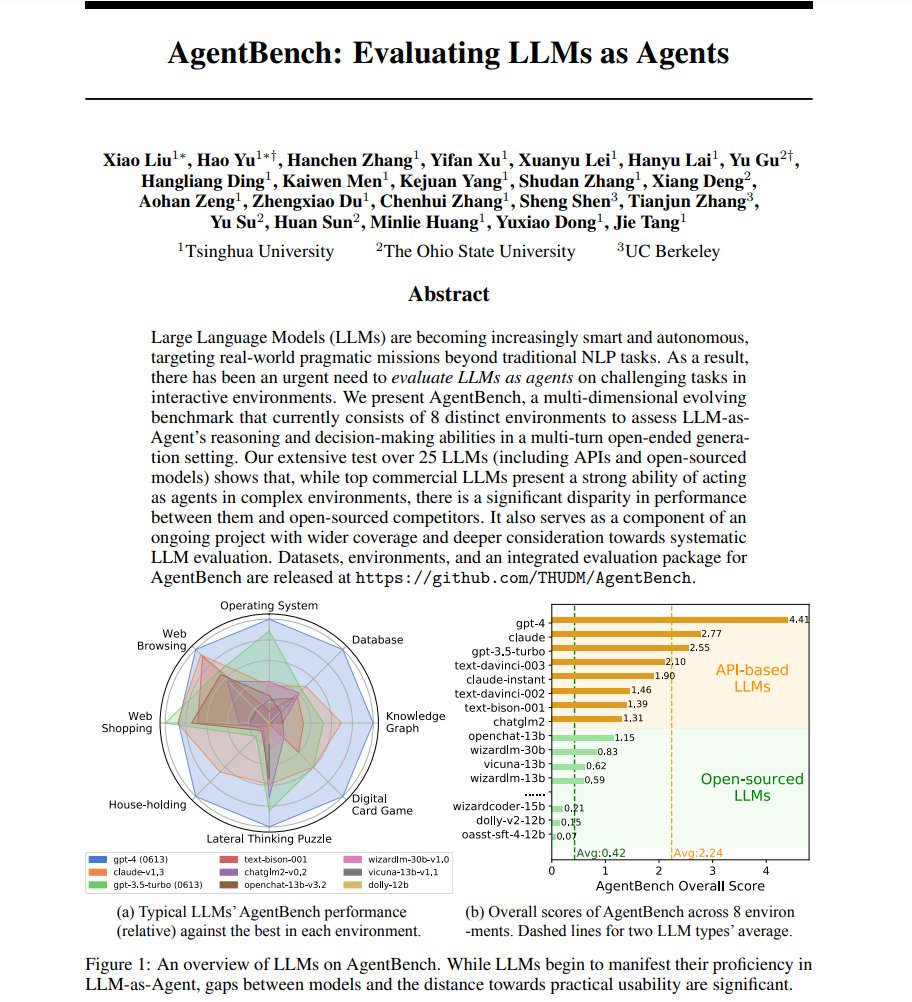
AgentBench: Evaluating LLMs as Agents
Presents a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM as Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting.
repo: https://t.co/6DIaftPaNw
abs: https://t.co/H1B7wc6hRp
After text-only leaderboards, the next step is going to be multimodal leaderboards. Found an interesting paper that tries to benchmark all multimodal LLMs: https://t.co/NbRjgxDlq2
Looks like instructBLIP is current SOTA.
Available in @huggingface here: https://t.co/OnzQH0Gckd
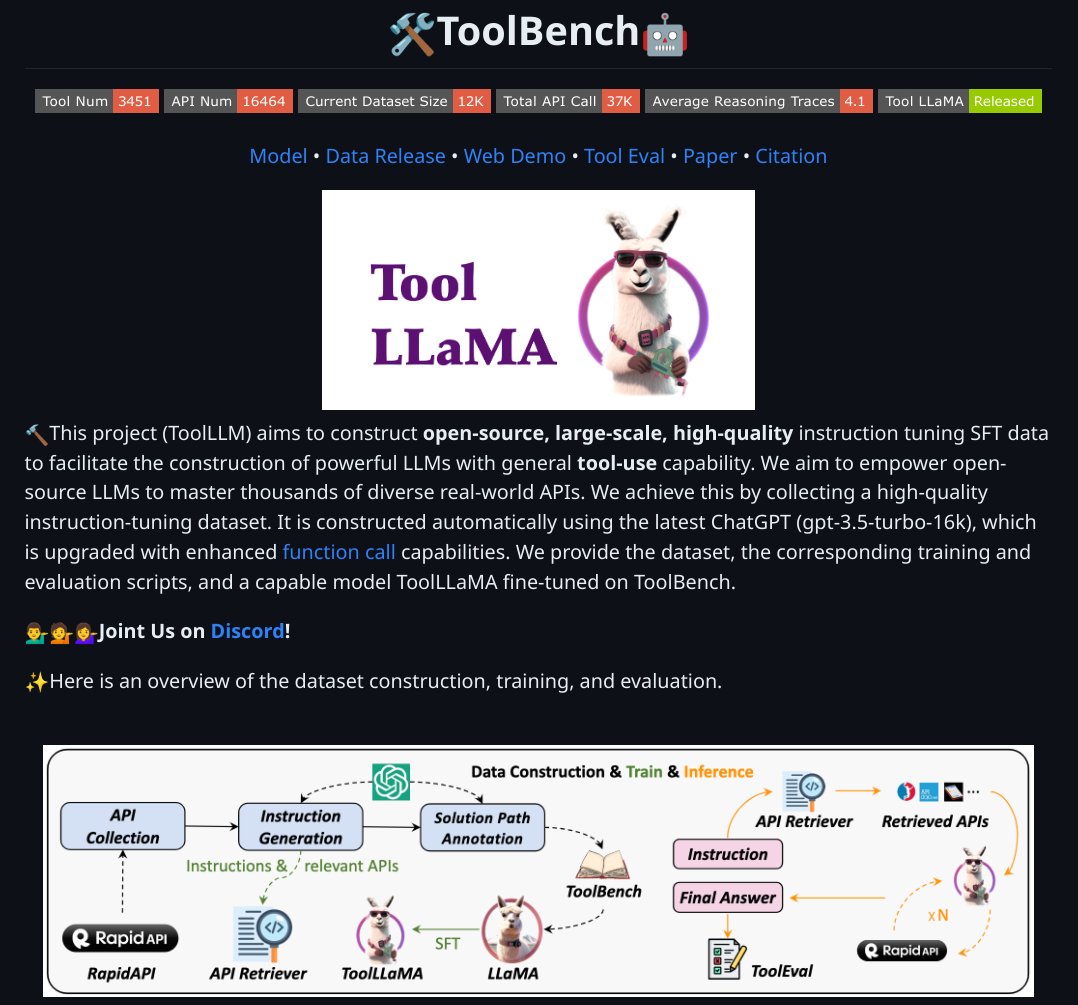
Enabling LLMs with tool-use capabilities is where I am noticing the greatest potential for companies to go big with LLMs.
Gorilla is a good popular example but I have seen a ton of other examples, especially from people building with AI-powered agents. I also think this is one of the use cases where open LLMs like Llama 2 are going to be extremely useful -- every company will want to tune their models for their own internal APIs.
If you are curious about this space, check out this new paper that enables LLMs to interact with 16000 real-world APIs. It's more of a framework with all the niceties like data preparation, training, and evaluation (GitHub repo included).
The authors also claim that one of their models, ToolLLaMA, has reached the performance of ChatGPT (turbo-16k) in tool use.
Another side note: not sure if it's possible that LLMs can do this natively, although the Llama 2 paper does mention a related emergent behavior.
I have been tracking all the research and tools that aim to enable these types of capabilities. Combining tools and LLMs is nothing new and we are seeing this across products and even in domains like Robotics and Chemistry. There are significant breakthroughs to be made here but we are not quite there yet.
(paper and tool in the replies)
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
ToolLLaMA exhibits comparable performance to ChatGPT
repo: https://t.co/J5V19NtpUw
abs: https://t.co/DzVjlJomiZ
Top ML Papers of the Week (July 24 - July 30):
- RT-2
- LoraHub
- Med-PaLM Multimodal
- Survey of Aligned LLMs
- Foundation Models in Vision
- Universal Adversarial LLM Attacks
...
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
Presents PanGu-Coder2, which achieves 62.20% pass@1 on the HumanEval benchmark.
https://t.co/3QjBH9xlkE
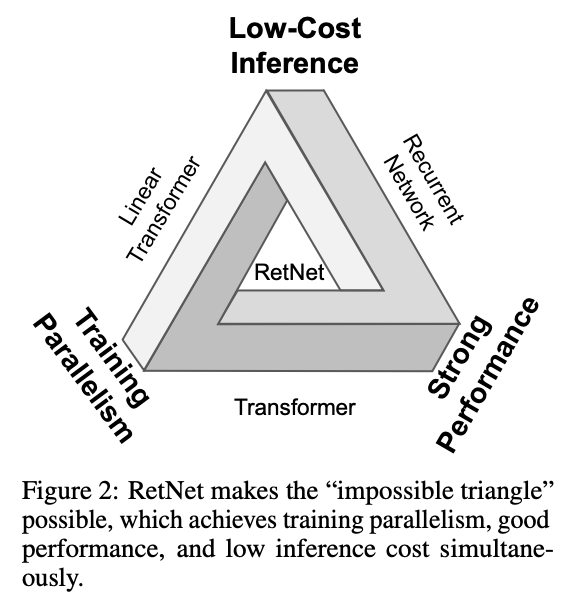
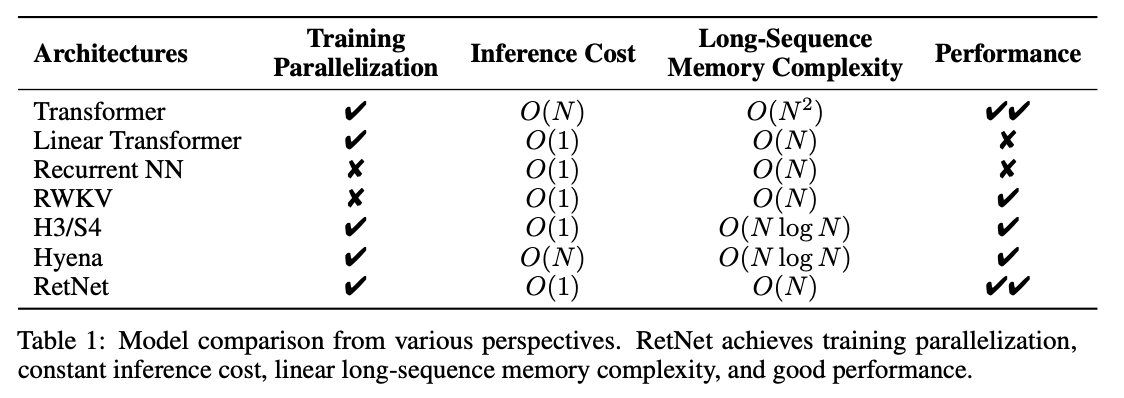
Microsoft and Tsinghua U. claim to have found the "Successor to Transformer for Large Language Models": RetNet. They claim better language modelling performance, with 3.4x lower memory consumption, 8.4x higher throughput, 15.6x lower latency. 1/2
The largest dialog dataset collection just dropped!
DialogStudio from Salesforce
TL;DR: Merged data from 87 datasets. Evaluated & filtered each sample by multiple criteria [1]. Ended up with a HUGE high quality conversational dataset.
---
Huggingface Dataset: https://t.co/4kDDMsJGI6
Github: https://t.co/DQOdDvPZKl
Paper: https://t.co/6ZxT0KToAW
---
The conversations in the dataset are categorized into multiple categories:
- Knowledge-Grounded-Dialogues
- Natural-Language-Understanding
- Open-Domain-Dialogues
- Task-Oriented-Dialogues
- Dialogue-Summarization
- Conversational-Recommendation-Dialogs
Really cool and useful work.
I just wish I had enough compute to train on all of these datasets
---
[1] Understanding, Relevance, Correctness, Coherence, Completeness, and Overall Quality.
Easily the best paper on current State of LLMs! 🙏
A 50 page read but it’s not “just another” survey paper, that only documents facts. The authors actually add very useful commentary capturing all aspects of building Large Language Models.
Hence the result is a collection of ideas we might have missed across months of research.
It covers both building LLMs and effectively applying them to domains, with a focus on current limitations and “sharp edges”
As always, I think great content makes you discover missing bits in your knowledge, for this reason it’s a solid cover to cover read recommendation:
https://t.co/DjCSS8o2Tp
Meta-Transformer: A Unified Framework for Multimodal Learning
The first framework to perform unified learning across 12 modalities with unpaired data
https://t.co/PYcYbnT6O0
We dug into a paper that’s been misinterpreted as saying GPT-4 has gotten worse. The paper shows behavior change, not capability decrease. And there's a problem with the evaluation—on 1 task, we think the authors mistook mimicry for reasoning.
w/ @sayashk
https://t.co/ZieaBZLRFy
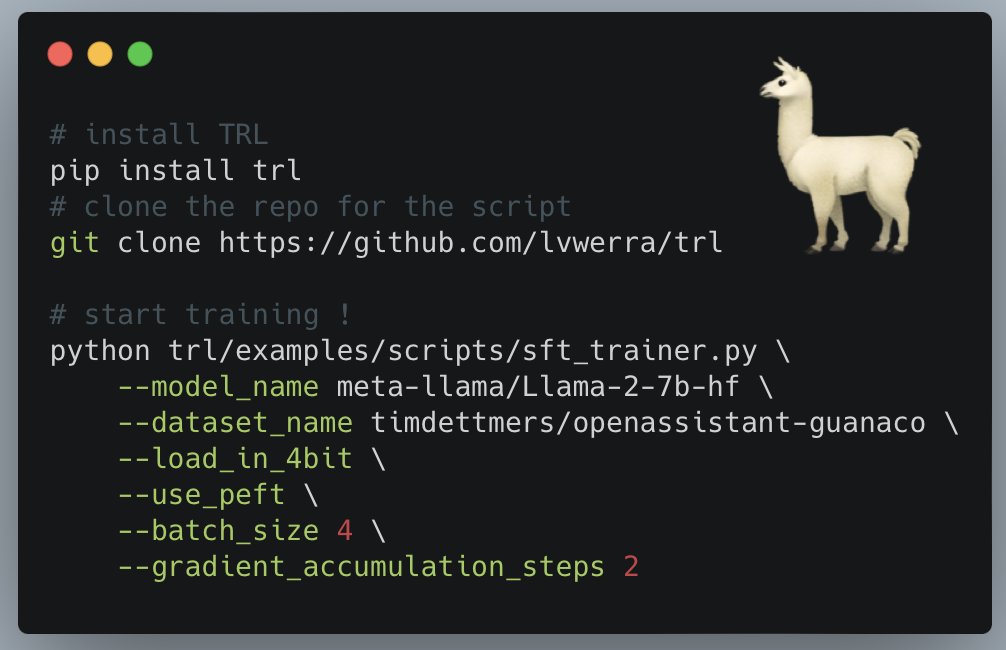
Did you know that you can train all Llama-2 models on your own data in just a few lines?
The script even works with the 70B model on a single A100 GPU thanks to the magic of 4bit and and PEFT!
Learn more: https://t.co/njGyWdnbzT
Full script: https://t.co/6y9FNdYSuT
Good / slightly obscure tip is that applications can benefit from custom supervised finetuning of emebeddings returned by APIs. Collect a few examples of +ve (and optionally hard -ve) pairs, use them to train a linear projection that better discriminates your pairs.






































![Yampeleg's tweet photo. The largest dialog dataset collection just dropped!
DialogStudio from Salesforce
TL;DR: Merged data from 87 datasets. Evaluated & filtered each sample by multiple criteria [1]. Ended up with a HUGE high quality conversational dataset.
---
Huggingface Dataset: https://t.co/4kDDMsJGI6
Github: https://t.co/DQOdDvPZKl
Paper: https://t.co/6ZxT0KToAW
---
The conversations in the dataset are categorized into multiple categories:
- Knowledge-Grounded-Dialogues
- Natural-Language-Understanding
- Open-Domain-Dialogues
- Task-Oriented-Dialogues
- Dialogue-Summarization
- Conversational-Recommendation-Dialogs
Really cool and useful work.
I just wish I had enough compute to train on all of these datasets
---
[1] Understanding, Relevance, Correctness, Coherence, Completeness, and Overall Quality.](https://pbs.twimg.com/media/F1tAk8mXwAA9HrA.jpg)