To train a GPT class 1T model from scratch - including failed runs, data acq+clean+rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE + fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent + GPUs at that scale where you can do interesting things.
I miss when progress in AI meant a better optimizer, a funky loss function, a novel architecture. Now it means a funding round, a press release, a lobbying memo, a valuation. More frontier labs than boardrooms, people.
No credit to the media, but watching coaching institutes project themselves as benevolent angels is hilarious.
Anyone who has lived through India’s dystopian coaching-factory phase knows what this is. A large-scale education mafia selling dreams, draining parents’ savings, and stealing children’s childhoods through a cramscam.
They do not produce thinkers, creators, scientists, artists, or even well-rounded humans. They produce exam-shaped parrots optimized for MCQs, terrified of failure, and trained to believe life begins and ends with one entrance test.
The same institutes game the exams, profit from the anxiety, build billion-rupee empires, and are often involved in the ecosystem of leaks, shortcuts, and manufactured rank worship.
India gets the worst of both worlds: none of the academic freedom of the West, none of the depth or state-backed scientific ambition of China, just industrial-scale exam obedience with TED Talk branding.
Then we wonder why we have so few Olympiad medals, Nobels, frontier startups, or deep research breakthroughs.
And the saddest part? The genuinely brilliant students who make it through would probably have made it anyway. The coaching mafia did not create their talent. It merely monetized their suffering.
So no need to engage in this worship of a clearly politically motivated "educator". Infact the continuation of this system is much worse for the country than a leak here and there
जिसने वर्षों तक पत्रकारिता को TRP, प्रोपेगेंडा और सत्ता के पक्ष-विपक्ष की लड़ाई में बदल दिया हो, उसे शिक्षकों को 'धंधेबाज' कहने से पहले आत्ममंथन करना चाहिए।
शिक्षा में गलत लोग भी हैं।
लेकिन पत्रकारिता में भी हैं।
राजनीति में भी हैं।
व्यापार में भी हैं।
तो क्या कुछ गलत लोगों के कारण पूरे शिक्षक समाज को "दो कौड़ी का" कह दिया जाएगा?
anjana शिक्षक का सम्मान कमाने में वर्षों लगते हैं।
भर्तियाँ अटक रही थीं,
लाखों युवाओं की उम्र निकल रही थी,
तब आपके स्टूडियो की आवाज़ कहाँ थी?
शिक्षकों ने पैसे लेकर शिक्षा दी है।
लेकिन पैसे लेकर किसी राजनीतिक दल का प्रवक्ता बन जाना,
व्यवस्था की हर गलती पर पर्दा डालना,
और जनता के असली मुद्दों से ध्यान भटकाना...
यह सिर्फ पत्रकारिता का पतन नहीं,
बल्कि अपने पेशे के साथ गद्दारी है।
शिक्षक फीस लेकर ज्ञान देता है,
मेहनत करवाता है,
बच्चे का भविष्य बनाता है
शिक्षकों ने पैसे लेकर पढ़ाया है,
देश के लाखों युवाओं को रोजगार तक पहुँचाया है।
लेकिन गलत को सही और सही को गलत साबित करने की कीमत लेकर काम करना,
समाज और लोकतंत्र दोनों के साथ विश्वासघात किसने किया ?
No credit to the media, but watching coaching institutes project themselves as benevolent angels is hilarious.
Anyone who has lived through India’s dystopian coaching-factory phase knows what this is. A large-scale education mafia selling dreams, draining parents’ savings, and stealing children’s childhoods through a cramscam.
They do not produce thinkers, creators, scientists, artists, or even well-rounded humans. They produce exam-shaped parrots optimized for MCQs, terrified of failure, and trained to believe life begins and ends with one entrance test.
The same institutes game the exams, profit from the anxiety, build billion-rupee empires, and are often involved in the ecosystem of leaks, shortcuts, and manufactured rank worship.
India gets the worst of both worlds: none of the academic freedom of the West, none of the depth or state-backed scientific ambition of China, just industrial-scale exam obedience with TED Talk branding.
Then we wonder why we have so few Olympiad medals, Nobels, frontier startups, or deep research breakthroughs.
And the saddest part? The genuinely brilliant students who make it through would probably have made it anyway. The coaching mafia did not create their talent. It merely monetized their suffering.
So no need to engage in this worship of a clearly politically motivated "educator".
It's so great, there are so many of them!
Here are more fellowships, that were not mentioned in the list:
- MARS, Cambridge AI Safety Hub
- AI Safety Camp (AISC)
- PRISM
- CAIS AI & Society Fellowship @CAIS
- Cooperative AI Research Fellowship: CAIF / PIBBSS / UCT / AI Safety South Africa @AI_Safety_SA@coop_ai
- GovAI Summer/Winter Fellowship in Oxford @GovAIOrg
- Future Impact Group Fellowship
- Arcadia Impact: AI Governance Taskforce
- Sydney AI Safety Fellowship
- LawAI / Law & AI Institute Summer Research Fellowship @law_ai_
Also, check out this post with even more fellowships: https://t.co/Mb3WBenl5H
I’ve been reading the Vedas a lot recently, and what’s stood out is how it doubles as an encyclopedia as well as a religious text. Astronomy, medicine, mathematics, metallurgy, linguistics, are all woven through hymns and rituals as one body of knowledge. Simply calling it “religious” forces it into a Western category that didn’t have the apparatus to recognize what it actually was. It’s closer to a tradition of formalized epistemology in which metaphysics, observation, and language form one continuous inquiry, which as a result led Indian civilization to develop along a fundamentally different path because of it.
You can see the effect most clearly in the sciences. Around 600 BCE, the Vedic record describes a surgical procedure that matches modern rhinoplasty and is still foundational to reconstructive surgery today. Centuries before Western Europe stopped treating eclipses as supernatural, Indian scholars had calculated the circumference of the earth within 0.2% and explained eclipses as shadows. Centuries before Plato and Aristotle rejected atomism, the Vedic tradition already held that matter is composed of indivisible particles combining into binary and triatomic compounds, transformable by heat. The first formal rules for zero and negative arithmetic appear in the Vedas, along with infinite-series derivations of π, sine, and cosine centuries before Newton and Leibniz.
The interesting question is how did they get so much right, so early? My best guess is language.
The Vedic tradition is unique compared to other oral traditions as it demanded letter-perfect oral transmission across generations. Around 500 BCE, scholars composed a generative grammar of Sanskrit called Panini so rigorous it anticipates Backus-Naur form, the notation that defines programming languages today, by 2,500 years. Sanskrit is recursive, rule-based, and built to minimize ambiguity. It reads more like mathematics than English.
When you think in a language built like that, the precision of the language becomes the precision of your reasoning. The West didn’t formalize this until much later. Kant argued our categories of understanding shape what we can know, Wittgenstein wrote that the limits of language are the limits of one’s world, and Kripke showed that naming doesn’t just describe things, it constitutes what they mean and how we can reason about them. All three touch the same insight which is that thought is downstream of language.
The Vedic tradition operated on that insight thousands of years earlier. To the point that they built a whole language first and used it to think clearly about everything else after. I find that all really fascinating.
this is fascinating, they train an encoder/decoder but use LLM matching the target model's shape for each part, so the latent space is just plain language and they can detect reward hacking, unwanted behavior and more
could even see it being used as an eval to quantify how smart a model is, i love this
NLAs can reconstruct a layer activation, but that doesn't mean they read what the model is thinking.
The setup is a round trip.
You take a frozen target LLM and grab an activation h_l from some layer l at some token position. The activation verbalizer (AV) takes that activation as input and produces text, which is interpreted as a natural-language "explanation" of what the activation encodes.
The activation reconstructor (AR) then takes only that text and produces a reconstructed activation ĥ_l. The training objective is the L2 reconstruction loss ||h_l − ĥ_l||². Because the text bottleneck is discrete, the AV and AR are both trained with RL against this reconstruction reward.
While it makes sense that the AV has to push enough information through a discrete text bottleneck for the AR to recover the original activation under L2, there is a huge gap between "this text reconstructs the activation under L2" and "this text describes what the model is thinking."
First, L2 closeness in activation space is a weak proxy for semantic equivalence — activations are high-dimensional and not all directions are meaningful.
Second, the AV and AR are both trained with RL against a reconstruction reward, so nothing rules out reward hacking — two co-trained RL policies can settle into an agreed code where the text looks like English but actually carries information only the AR knows how to read.
Third — and most importantly for the eval-awareness claim — test prompts don't look like normal user messages (weird scenarios, high stakes, obvious decision points), so they produce different activations.
An NLA trained to verbalize what's different about an activation will produce text like "this looks like a test." But that's pattern recognition of the input, not evidence that the model is holding a belief or doing anything cognitively analogous to thinking it's being tested.
The interesting question for me isn't whether NLAs are extracting something (they probably are) but whether the natural-language outputs are faithful renderings of activation content versus plausible-sounding text generated under priors that happen to discriminate well.
That's the same critique people have about almost all self-explanation methods.
And I don't think NLAs fully escape it.
Interpreting model activations is important to understand why a model is doing what its doing.
Traditionally, we've done this with supervised methods (probing for a specific context), or unsupervised sparse decompositions (dictionary learning).
But probing requires you to know what you are looking for, and sparse dictionaries can be overwhelming to interpret.
NLAs are exciting because they instead generate natural language explanations, which we can then inspect for a variety of behaviors.
For example, they reveal the planning behavior we first observed with circuit tracing last year. They also helped identify bugs in Claude's training pipeline, where some prompts were only partially translated.
If you want to play with them, NLAs on open models are available on Neuronpedia! https://t.co/ELZgiucKAT
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
Excited to release the Ultimate guide to RL environments!
Definitions of RL environments differ wildly in the LLM era, so we spent the last month building several RL environments across 6 different frameworks, domains and complexities to map out which are easiest to build with and which can be scaled to 1000s.
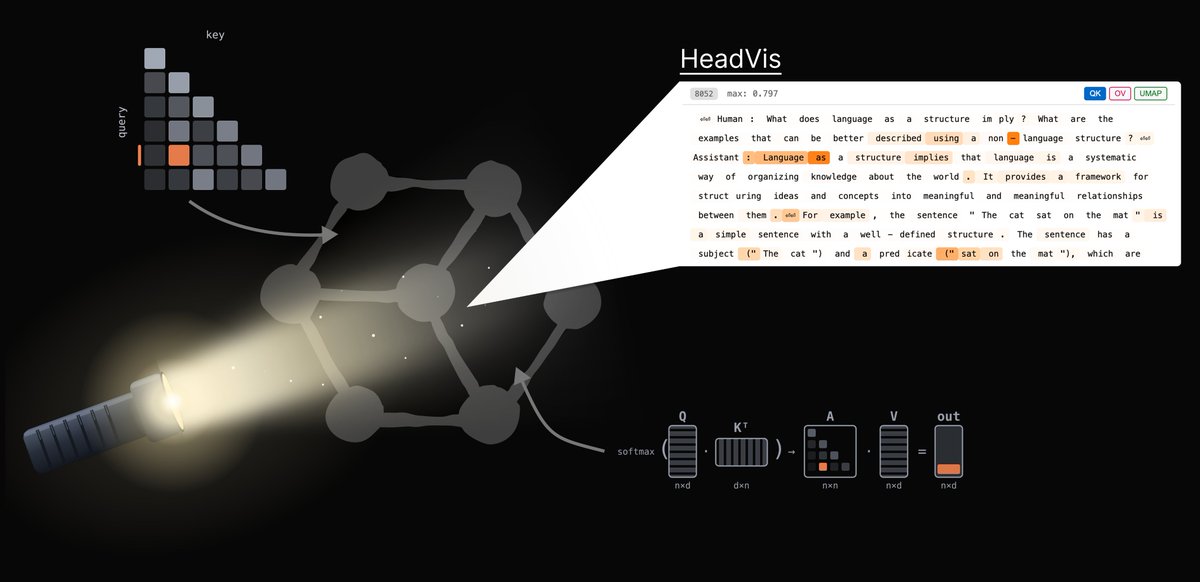
Interpreting language models can feel like stumbling through a dark forest - sometimes you just wish you had a flashlight! In our new post, we introduce HeadVis, our latest flashlight for studying attention heads.
New Anthropic Fellows research: Model Spec Midtraining (MSM).
Standard alignment methods train AIs on examples of desired behavior. But this can fail to generalize to new situations.
MSM addresses this by first teaching AIs how we would like them to generalize and why.