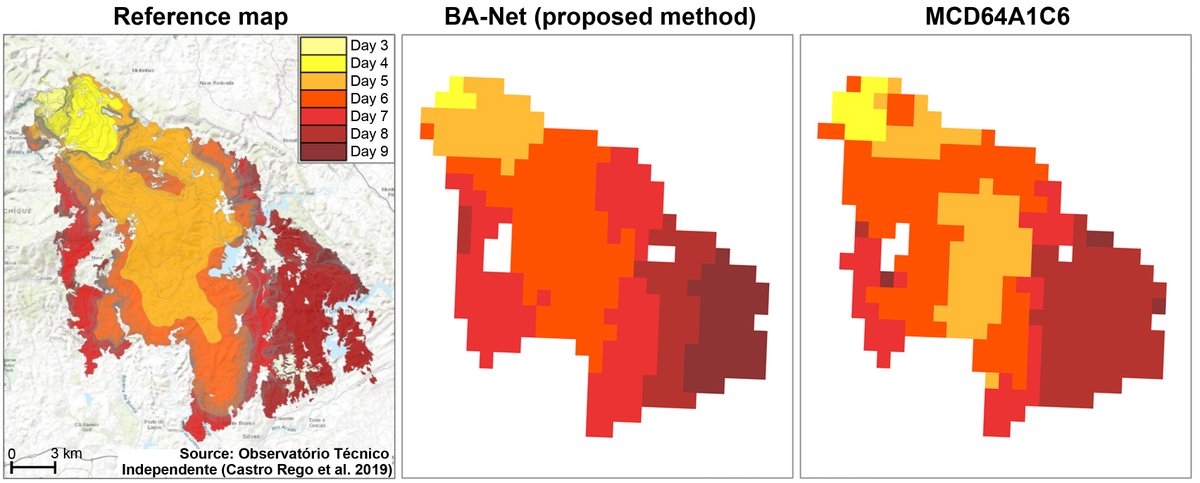
My first article using Deep Learning is now out with the title "A deep learning approach for mapping and dating burned areas using temporal sequences of satellite images"
Article: https://t.co/PCnSJKxAJW
Code and data: https://t.co/uUew7P2gNr
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
I am proud to announce that I have successfully completed the world’s first USA coast to coast fully autonomous drive!
I left the Tesla Diner in Los Angeles 2 days & 20 hours ago, and now have ended in Myrtle Beach, SC (2,732.4 miles)
This was accomplished with Tesla FSD V14.2 with absolutely 0 disengagements of any kind even for all parking including at Tesla Superchargers.
Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.
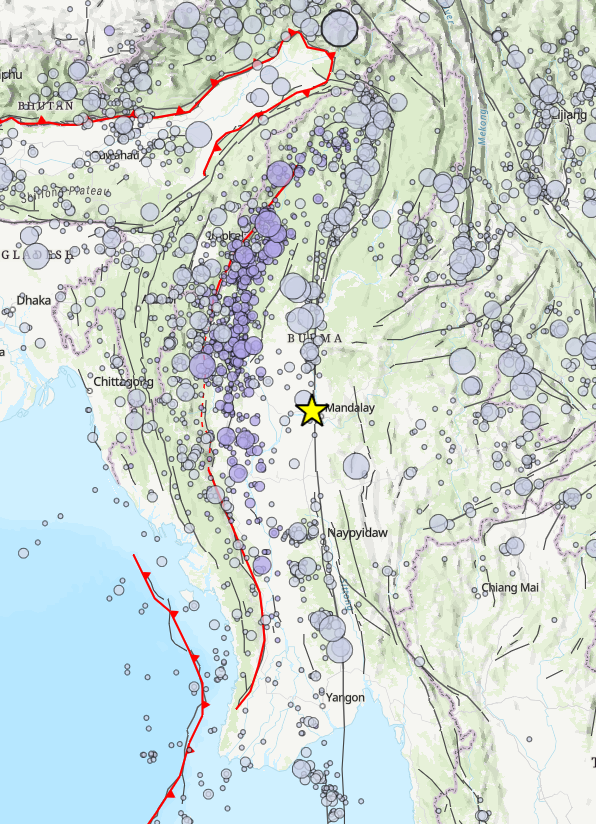
The USGS created a geonarrative about the M7.7 #earthquake that occurred near Mandalay, Burma (Myanmar) on March 28, 2025. Read more below!
https://t.co/r0bXSHdH3q
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the groundbreaking technique behind its success: scaling test-time compute 🧠💡
By giving models more "time to think," LLaMA 1B outperforms LLaMA 8B in math—beating a model 8x its size. The full recipe is open-source🤯
This is the power of open science and open-source AI! 🌍✨
NotebookLM is quite powerful and worth playing with
https://t.co/EMHIjc15iU
It is a bit of a re-imagination of the UIUX of working with LLMs organized around a collection of sources you upload and then refer to with queries, seeing results alongside and with citations.
But the current most new/impressive feature (that is surprisingly hidden almost as an afterthought) is the ability to generate a 2-person podcast episode based on any content you upload. For example someone took my "bitcoin from scratch" post from a long time ago:
https://t.co/7ajZNZ0BGi
and converted it to podcast, quite impressive:
https://t.co/ZZn0LJgsnu
You can podcastify *anything*. I give it train_gpt2.c (C code that trains GPT-2):
https://t.co/gDrAqix4Iv
and made a podcast about that:
https://t.co/bgcwmQr5d7
I don't know if I'd exactly agree with the framing of the conversation and the emphasis or the descriptions of layernorm and matmul etc but there's hints of greatness here and in any case it's highly entertaining.
Imo LLM capability (IQ, but also memory (context length), multimodal, etc.) is getting way ahead of the UIUX of packaging it into products. Think Code Interpreter, Claude Artifacts, Cursor/Replit, NotebookLM, etc. I expect (and look forward to) a lot more and different paradigms of interaction than just chat.
That's what I think is ultimately so compelling about the 2-person podcast format as a UIUX exploration. It lifts two major "barriers to enjoyment" of LLMs. 1 Chat is hard. You don't know what to say or ask. In the 2-person podcast format, the question asking is also delegated to an AI so you get a lot more chill experience instead of being a synchronous constraint in the generating process. 2 Reading is hard and it's much easier to just lean back and listen.
We are excited to introduce Stable Fast 3D, Stability AI’s latest breakthrough in 3D asset generation technology. This innovative model transforms a single input image into a detailed 3D asset in just 0.5 seconds, setting a new standard for speed and quality in the field of 3D reconstruction!
Alongside this release, we’ve also published a technical report that highlights how we achieve fast inference speeds with reduced baked illumination and material parameters.
👾You can learn more and access the report here: https://t.co/emwQS4zsrb
One of the most ominous risks for Europe is that of a major change in Atlantic ocean currents.
Recent science suggests it has been greatly underestimated in the past -including by me, having worked on it for over 30 years.
Here my half-hour presentation in Vilnius a week ago!
ARK's Big Ideas 2024
https://t.co/4PmGSC9o6A
Our views on where technology will take markets and the world through 2030
We are entering an unprecedented technological era
Published in @Nature: our AI system for material design ‘GNoME’ that found 380,000 new materials (which we’ve made freely available to the research community) with potential to accelerate greener tech from better batteries to more efficient superconductors https://t.co/0kGJmruKwY
Legendary paper simulates an ecosystem for a 1,000 years. One of the most beautiful works I have ever had the honor of covering. So good!
▶️ Our full video: https://t.co/a4nQol46wN
📜Paper: https://t.co/9B0g0EfICy
Today, we are releasing Stable Video Diffusion, our first foundation model for generative AI video based on the image model, @StableDiffusion. As part of this research preview, the code, weights, and research paper are now available.
Additionally, today you can sign up for our waitlist to access a new upcoming web experience featuring a Text-To-Video interface.
To access the model & sign up for our waitlist, visit our website here: https://t.co/IcuPJr45S9