1/ Exciting new AI capabilities are coming to Google Search starting today.
First, we’re bringing Gemini 2.0 models to AI Overviews so they can better handle questions like coding and advanced math. Second, we’re introducing a new Search experiment in Labs: AI Mode.
We’ve been hearing from power users that they want AI responses for even more of their searches. With AI Mode, you can now ask whatever’s on your mind and you'll get an AI response along with helpful links. It's also easy to ask follow-up questions. 🧵
We’re rolling out AI Mode to Google One AI Premium subscribers today, opt in on Labs. And just like AI Overviews, AI Mode will get better with time and feedback. Get details here: https://t.co/k9qfHH83HI
Gemini 🤝 Search. Check out AI Mode, our new Labs experiment with the potential to make Google Search drastically more helpful for your hardest questions. AI Mode offers more advanced reasoning, thinking and multimodal capabilities, bringing the best of Gemini 2.0 to Search.
We’re crushing it with training specialist models. Just need to build specialist models that train the ultimate generalist model for us.
It might feel like a step away from the goal, but this detour could be the perfect shortcut!
What a way to celebrate one year of incredible Gemini progress -- #1🥇across the board on overall ranking, as well as on hard prompts, coding, math, instruction following, and more, including with style control on.
Thanks to the hard work of everyone in the Gemini team and elsewhere at Google! 🎊
Huge congratulations to @DemisHassabis and John Jumper on being awarded the 2024 Nobel Prize in Chemistry for protein structure prediction with #AlphaFold, along with David Baker for computational protein design.
This is a monumental achievement for AI, for computational biology, and science itself. 🧬
Congrats to my colleagues @demishassabis & John Jumper for winning the Nobel Prize in chemistry for their awesome AlphaFold work. AlphaFold has had a dramatic impact across many fields including medicine, drug development & more.
And yes, this is my second Nobel-congratulating post in two days for current or former Google colleagues! 🎉
"I'm in a cheap hotel in California which doesn't have a good internet or phone connection. I was going to have an MRI scan today but I'll have to cancel that!"
- New physics laureate Geoffrey Hinton speaking at today’s press conference where his #NobelPrize was announced.
Enhancing Q&A Text Retrieval with Ranking Models: Benchmarking, fine-tuning and deploying Rerankers for RAG
NVIDIA benchmarks ranking models for text retrieval in QA tasks introducing a new sota model NV-RerankQA-Mistral-4B-v3
📝https://t.co/Bsb8B28BMi
👨🏽💻https://t.co/OZzu159ep8
Reliable Confidence Intervals for Information Retrieval Evaluation Using Generative A.I
Google introduces two methods for creating reliable confidence intervals around IR evaluation metrics using LLM-based relevance annotation
📝https://t.co/RmSXP6cE62
👨🏽💻https://t.co/yIiRvghado
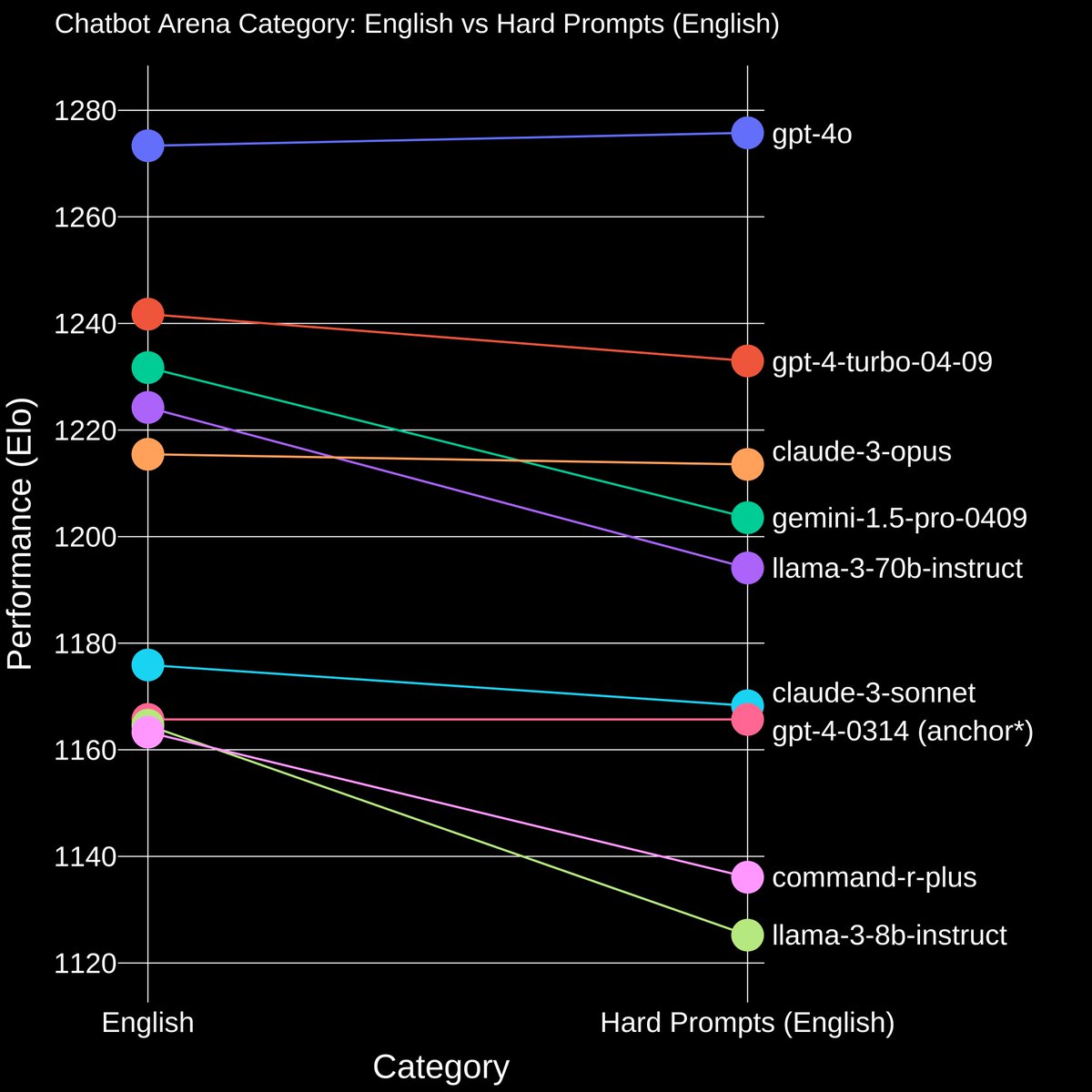
Introducing "Hard Prompts" Category in Arena!
In response to the community's growing interest in evaluating models on more challenging tasks, we are excited to launch the new "Hard Prompts" category.
We select user prompts that are more complex, specific, and problem-solving oriented.
The result shows interesting ranking shifts. For example, Llama-3-8B, which performs comparably to GPT-4-0314 on the English-only leaderboard, drops quite a bit under Hard Prompts.
We believe this new category can offer new insights into the models' performance on more difficult tasks.
today i learned something very interesting at ICLR, a term called order of evidence.
During RAG, we send the top retrieved documents as evidences and prompting them to LLMs. Normally prompting is based on cosine similarity: top match always being prompted first.
However, different LLMs might have difference "preference" on the order of evidence:
1. ChatGPT prefers top evidence, which is good.
2. GPT4 has no preference on evidence order, which means the similarity score is not being considered, you only need to decide top-K, and all evidences will be equally treated.
3. Surprisingly, Llama2 and PaLM prefers last order evidence, so you need to reverse the rank list then prompt to the LLM :)
https://t.co/fHRR0FGO26
My last work at Microsoft Research is finally released: https://t.co/OWhvzqFJEH 10 MILLION REAL Bing search queries with 60 MILLON+ REAL user clicks on 10 BILLION ClueWeb22 documents. Have fun scaling up!
Long context is essentially a length generalization problem. Our recent work "Transformers Can Achieve Length Generalization But Not Robustly" (https://t.co/2Qkyw5z3z6) showed a surprisingly simple approach to achieving length generalization: train your model several times using different random seeds, and then you will see one does great on length generalization.
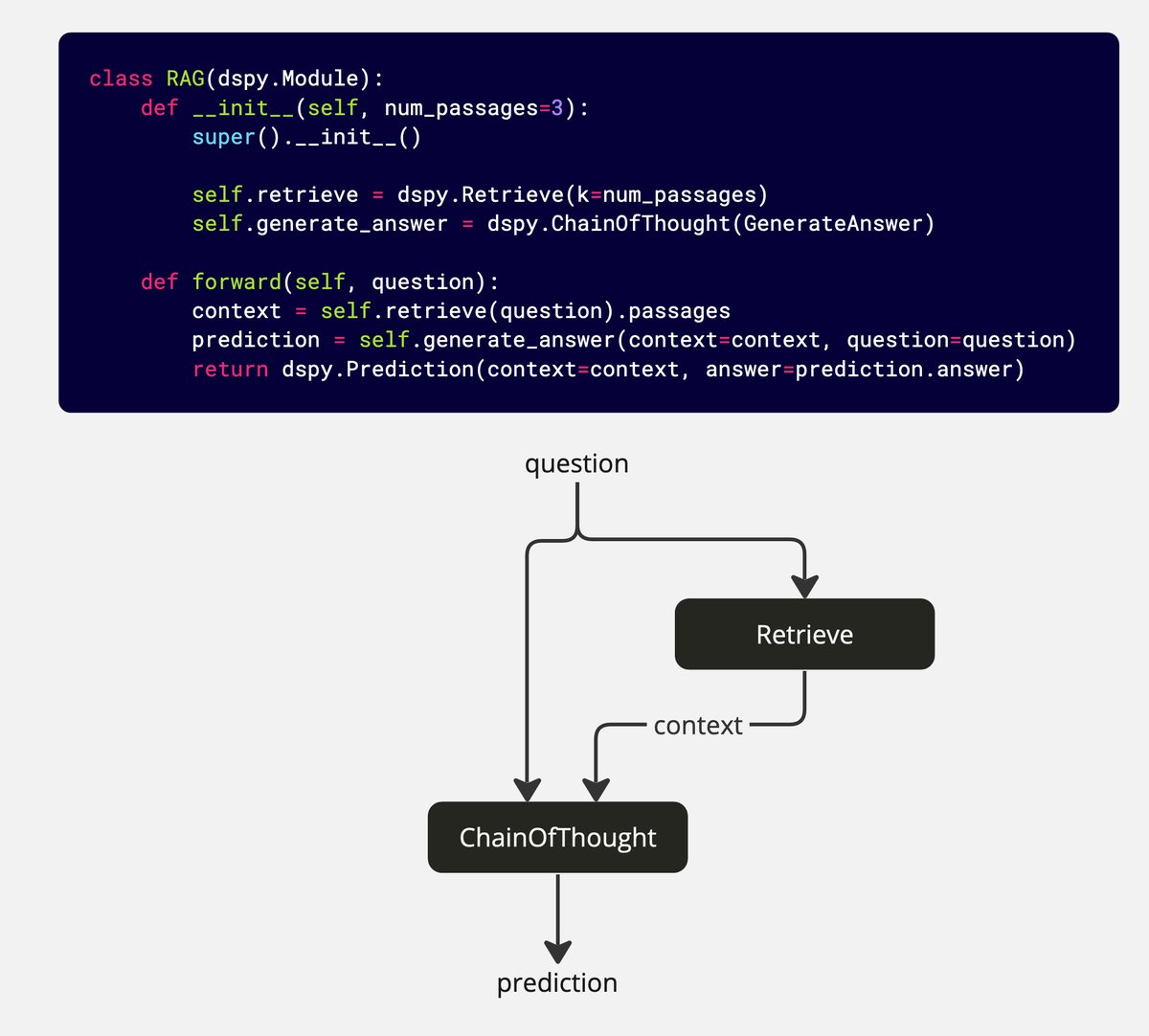
If you haven’t been living under a rock, you have already noticed that the developer community is currently super excited about DSPy.
DSPy is a framework developed by Stanford NLP researchers (@lateinteraction) to help you build LLM-based applications.
In contrast to similar frameworks, DSPy aims to tackle the fragility problem of developing LLM-based applications by prioritizing programming over prompting.
DSPy does this by introducing the following concepts:
- Hand-written prompts and fine-tuning are abstracted and replaced by signatures
- Prompting techniques, such as Chain of Thought or ReAct, are abstracted and replaced by modules
- Manual prompt engineering is automated with optimizers (teleprompters) and a DSPy Compiler
Below, you can see what the code and information flow of a DSPy program for a naive RAG pipeline would look like.
Read more on @TDataScience: https://t.co/AnrpyPaPku