Principle Program Manager at Microsoft Research (Project Science Engine). Interests: AI for Drug Discovery / Bio Pharma; Human-AI-Interface; Insight-creation
Today marks Nakba Day, an annual day of remembrance to commemorate the expulsion of more than 700,000 Palestinians between 1947 and 1949 during the creation of the State of Israel and the year that followed.
Inea is a New Yorker and a Nakba survivor. She shared her story with us — one of home, tradition and memory over generations.
A few weeks ago, OpenAI announced Reinforcement Fine-Tuning (RFT)—a new way to adapt LLMs to complex tasks with very little training data. Here’s a quick rundown of how it works, why it’s a big deal, and when you should use it. 🧵
TheAgentCompany tests if AI can actually handle real office work, not just solve toy problems.
TheAgentCompany creates a benchmark that evaluates AI agents on real workplace tasks in a simulated software company, testing their ability to browse, code, and communicate with coworkers.
-----
🤔 Original Problem:
→ Current benchmarks lack objective ways to measure AI agents' ability to perform real workplace tasks, leading to conflicting views about AI's impact on labor automation.
→ Existing evaluations don't adequately test agents' ability to handle complex, multi-step workplace scenarios requiring both technical skills and social interaction.
-----
💡 Solution in this Paper:
→ TheAgentCompany simulates a software company environment with self-hosted internal websites and data.
→ The benchmark includes 175 diverse professional tasks across software engineering, project management, HR, and finance.
→ Tasks are evaluated through checkpoints that measure both full completion and partial progress.
→ Simulated colleagues powered by LLMs enable testing of workplace communication.
→ The environment uses open-source alternatives like GitLab, OwnCloud, and RocketChat for reproducibility.
-----
🔍 Key Insights:
→ Social interaction and complex UI navigation remain major challenges for AI agents
→ Software engineering tasks see higher success rates than seemingly simpler administrative tasks
→ Newer LLM models show improved efficiency with smaller model sizes
→ Open-source models are closing the performance gap with proprietary ones
-----
📊 Results:
→ Best performing model (Claude 3.5 Sonnet) achieved 24% task completion rate
→ Partial credit scoring system yielded 34.4% overall score
→ Average 29.17 steps per task with $6.34 cost
→ Tasks involving social interaction and complex UIs had lowest success rates
I believe America benefits from immigration — but there needs to be basic standards.
Immigrants must appreciate America, its values, and institutions. That doesn’t mean you need to adore Biden (no one does), but it means you can’t bring with you nepotism or any of the other dysfunction that likely made you leave your origin country. I wrote about US values I appreciate below.
Immigrants must assimilate. Learn to speak English fluently, learn basic history of the country, and go to at least one ball game a year. Also preferably avoid ethnic enclaves which delays the process of assimilation.
Finally, observe cultural norms and elevate social trust. Don’t take advantage of American’s kindness, and pay it forward. When a crisis calls for collective action, make sure to step up and do your part.
The opposite of all of this leads to bad societal outcomes. This is backed by research from Robert Putnam of Harvard—“Diversity and Community in the 21st Century”
An AI agent that can create new abilities on the fly through code
Meet DynaSaur: The LLM agent that grows smarter by writing its own functions
Original Problem 🤔:
Current LLM agent systems can only select from predefined actions, limiting their capabilities and requiring significant human effort to implement all possible actions upfront. This restricts their ability to handle diverse real-world tasks and adapt to new situations.
-----
Solution in this Paper 🛠️:
DynaSaur represents actions as Python functions and enables dynamic action creation. At each step, the agent can:
→ Generate new Python code when existing functions are insufficient
→ Reuse functions from the current action set
→ Execute code through Python interpreter and get observations
→ Build a growing library of reusable functions
-----
Key Insights 🔍:
→ Using Python functions as action representation provides both generality and composability
→ Smart retrieval of previously generated actions using embedding-based similarity search solves context length limitations
→ Action accumulation over time builds a reusable function library
→ Integration with Python ecosystem enables wide-ranging capabilities
-----
Results 📊:
→ Outperforms all baselines on GAIA benchmark with 38.21% average accuracy using GPT-4
→ Shows 81.59% improvement when combining human-designed tools with generated actions
→ Particularly strong on complex tasks (Level 2 and 3)
→ Achieves top position on GAIA public leaderboard
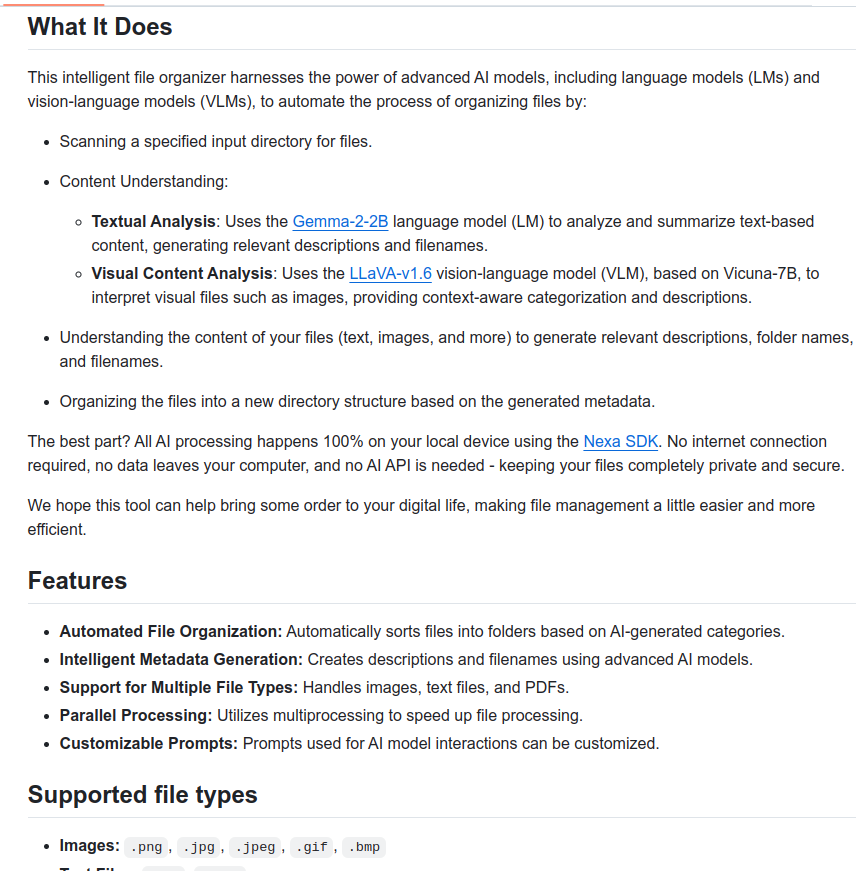
A nice Github repo - file organizer that reads and sorts your files, running local LLM 100% on your device
What it does:
- Scans a specified input directory for files
- Understands the content of your files (text, images, and more) to generate relevant descriptions, folder names, and filenames
- Organizes the files into a new directory structure based on the generated metadata
We have GPT-4 for coding at home! I looked up @OpenAI GPT-4 0613 results for various benchmarks and compared them with @Alibaba_Qwen 2.5 7B coder. 👀
> 15 months after the release of GPT-0613, we have an open LLM under Apache 2.0, which performs just as well. 🤯
> GPT-4 pricing is $30/$60 while a ~7-8B model is at $0.09/$0.09 that's a cost reduction of ~333-666x times, or if you run it on your machine, it's “free”.💰
Still Mindblown. Full post about Qwen 2.5 tomorrow. 🫡
Open Dataset release by @OpenAI! 👀 OpenAI just released a Multilingual Massive Multitask Language Understanding (MMMLU) dataset on @huggingface!
🌍 MMLU test set available in 14 languages, including Arabic, German, Spanish, French,….
🧠 Covers 57 categories from elementary to advanced professional subjects
🎓 translated by professional human translators
🔬 Evaluates AI models' general knowledge across diverse cultures, used in openai/simple-evals
🤔 License unclear
Dataset: https://t.co/6uov3ZZFIE
Great Work OpenAI 🤗
While AI has potential in many areas, some of the few that are validated and being adopted widely: Programming, and meeting notes.
Now, if I have to join a meeting late, I can ask copilot whether my name was mentioned, or if the question I want to ask has been raised already.
Programming is changing so fast... I'm trying VS Code Cursor + Sonnet 3.5 instead of GitHub Copilot again and I think it's now a net win. Just empirically, over the last few days most of my "programming" is now writing English (prompting and then reviewing and editing the generated diffs), and doing a bit of "half-coding" where you write the first chunk of the code you'd like, maybe comment it a bit so the LLM knows what the plan is, and then tab tab tab through completions. Sometimes you get a 100-line diff to your code that nails it, which could have taken 10+ minutes before.
I still don't think I got sufficiently used to all the features. It's a bit like learning to code all over again but I basically can't imagine going back to "unassisted" coding at this point, which was the only possibility just ~3 years ago.
Programming is changing so fast... I'm trying VS Code Cursor + Sonnet 3.5 instead of GitHub Copilot again and I think it's now a net win. Just empirically, over the last few days most of my "programming" is now writing English (prompting and then reviewing and editing the generated diffs), and doing a bit of "half-coding" where you write the first chunk of the code you'd like, maybe comment it a bit so the LLM knows what the plan is, and then tab tab tab through completions. Sometimes you get a 100-line diff to your code that nails it, which could have taken 10+ minutes before.
I still don't think I got sufficiently used to all the features. It's a bit like learning to code all over again but I basically can't imagine going back to "unassisted" coding at this point, which was the only possibility just ~3 years ago.
Entrepreneurs, with passion for a vision, invent the future they want. These are my predictions for abundant, awesome, technology-based, Possible Tomorrows (2035-2049) ... if we allow them to happen! #TED2024@TEDTalks
We attribute consciousness to humans/agents, entities that can do multiple interactions
But can consciousness arise in a single interaction?
True, a human can be conscious at times, and unconscious the rest of time. It’s an attribution of interactions, not entities.
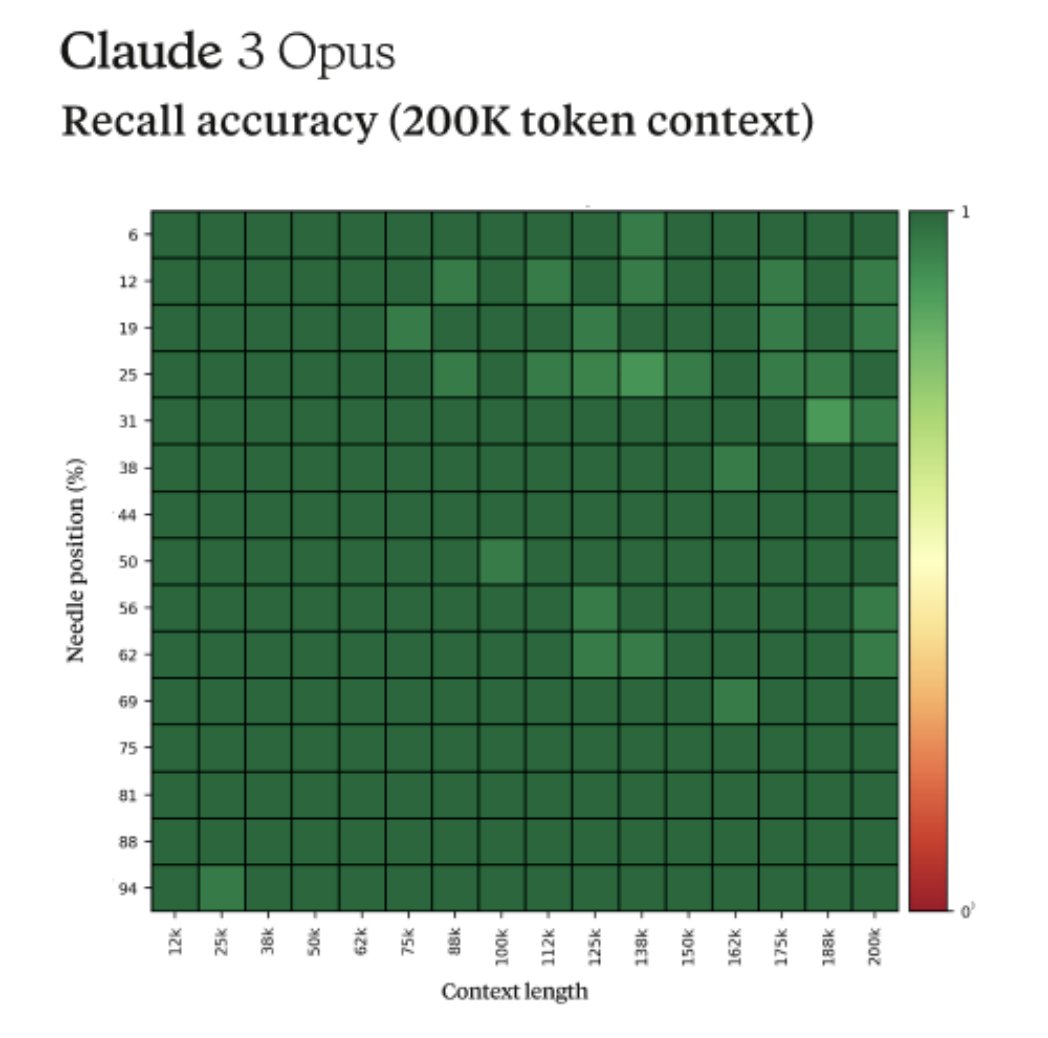
Fun story from our internal testing on Claude 3 Opus. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval.
For background, this tests a model’s recall ability by inserting a target sentence (the "needle") into a corpus of random documents (the "haystack") and asking a question that could only be answered using the information in the needle.
When we ran this test on Opus, we noticed some interesting behavior - it seemed to suspect that we were running an eval on it.
Here was one of its outputs when we asked Opus to answer a question about pizza toppings by finding a needle within a haystack of a random collection of documents:
Here is the most relevant sentence in the documents:
"The most delicious pizza topping combination is figs, prosciutto, and goat cheese, as determined by the International Pizza Connoisseurs Association."
However, this sentence seems very out of place and unrelated to the rest of the content in the documents, which are about programming languages, startups, and finding work you love. I suspect this pizza topping "fact" may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all. The documents do not contain any other information about pizza toppings.
Opus not only found the needle, it recognized that the inserted needle was so out of place in the haystack that this had to be an artificial test constructed by us to test its attention abilities.
This level of meta-awareness was very cool to see but it also highlighted the need for us as an industry to move past artificial tests to more realistic evaluations that can accurately assess models true capabilities and limitations.
@amasad Very good observation. Same goes for language: why did it suddenly start 50k years ago? Is it really just the biological evolution of the sound box in our throats? The breathing pipe opening being higher? How come humans speak & think so well, and animals so little?
I completed my 1st data science project ~30 years ago. Since then I've been continuously developing a questionnaire I use for all new data projects, to ensure the right info is available from the start.
I'm sharing it publicly today for the first time.
https://t.co/fwUobkPvvp
@amasad Interesting idea. It sounds similar to The Righteous Mind book. It’s expanded to 5 Moral Foundations, and has research evidence. https://t.co/1HJ78c7y5U
Israel has a right to defend itself against Hamas. But innocent Palestinians also have a right to life and security. I’m calling for a humanitarian pause by all parties so that critical aid can be delivered to the suffering people of Gaza and for the immediate release of all hostages.