It’s happening. https://t.co/abkb8IjPSH is going live, in person.
For the first time ever, we’re bringing the Vespa community together for a dedicated, in-person conference: https://t.co/abkb8IjPSH Live in London 🇬🇧
If you’ve been building with Vespa, exploring real-time AI, or pushing the limits of search and retrieval, this is the event you don’t want to miss.
This isn’t just another conference. It’s the people behind real-world systems, sharing what actually works at scale.
💥 What makes this special:
• The first-ever Vespa in-person event
• Deep dives into real-time, production-grade AI systems
• Talks from practitioners solving hard problems in search, personalization, and RAG
• A chance to meet the community face-to-face
🎤 And yes, we want to hear from you.
This is your chance to get on stage, share your work, and be part of shaping the Vespa ecosystem.
📍 London: Lumiere London Underwood Flagship Venue
📅 September 10, 2026
Details / submit your talk 👇
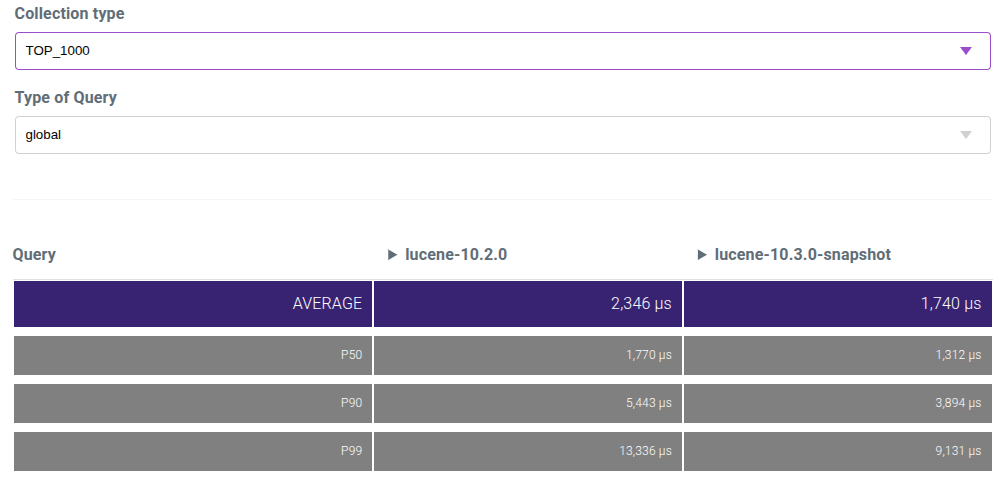
I just ran the Tantivy benchmark (https://t.co/DRB8tO45eD) on Lucene 10.2 vs a Lucene 10.3 snapshot build. Lucene 10.2 already performed very well, but Lucene 10.3 is on another level. Very exciting.
Elastic’s license rug pull, meant to hurt Amazon, ended up making OpenSearch the default. Most orgs I talk to run OpenSearch over Elasticsearch.
Probably the biggest strategic misfire in the software industry.
Also a perfect example of why the freedom to fork matters.
New Vespa features covered in the June newsletter:
- Layered ranking: Rank chunks in documents.
- Elementwise bm25
- top, filter_subspaces, and cell_order tensor functions
- chunking support in indexing
- element-gap: Proximity over chunks
- filtering in grouping results
- allowDropAll in weakAnd
- relevance eval support in PyVespa
- Support for private HuggingFace models
- Azure zones general availability
- Choose query tokenization, composition and syntax separately
- Give query tokenization control to linguistics
- Multiple tokens support in Lucene linguistics
- Detection confidence in language detection
- initial-inflight-factor: Faster feed speed ramp-up
- Vectorized int8 instructions
- Hex tensor rendering option
- Case sensitive matching option
- prioritize-availability option for query routing over groups
- equiv query items can now be nested inside near and onear
... are we shipaholics? 😬
June @vespaengine newsletter is out!
Lots of cool new stuff (e.g. built-in chunking) and educational content (e.g. demo E-commerce apps with new ideas)
Check it out and let us know of any feedback: https://t.co/qtl55FzQir
Until now you've either had to
- index document chunks as separate documents, creating a billion documents with no context, or
- index entire documents with many chunks, preserving context but feeding too much noise to LLMs.
The change has been merged and nightly benchmarks just caught up: https://t.co/kFAEU59BcY. I don't remember many improvements of this magnitude to non-trivial workloads in Lucene's history.
🚀 The Rise of Vision RAG!
Launching a complete RAG app that you can deploy to production in minutes!
- Hybrid fusion of ColPali + BM25 with @vespaengine
- Gemini 1.5 Flash-8B
- FastHTML frontend
- Runs on Huggingface Spaces
Interpretable SERP with snippets + patch highlights!
RAG with ColPali doesn't need to be sluggish.
Huge s/o to the team that built it @thomas_thoresen@andreer@ldalves
Let's be honest for a second: Building great retrieval systems is about people and knowledge (at least for a few years until AGI replaces us all, and we can retreat to our woodworking shops). https://t.co/WdCY0K2SPk
If you have worked in search, you know how freaking hard even getting started with something close to this with traditional methods. Now, you can zero-shot it.
I'm excited about this demo cookbook that drops soon.
ColQwen2 + @vespaengine + FastHTML
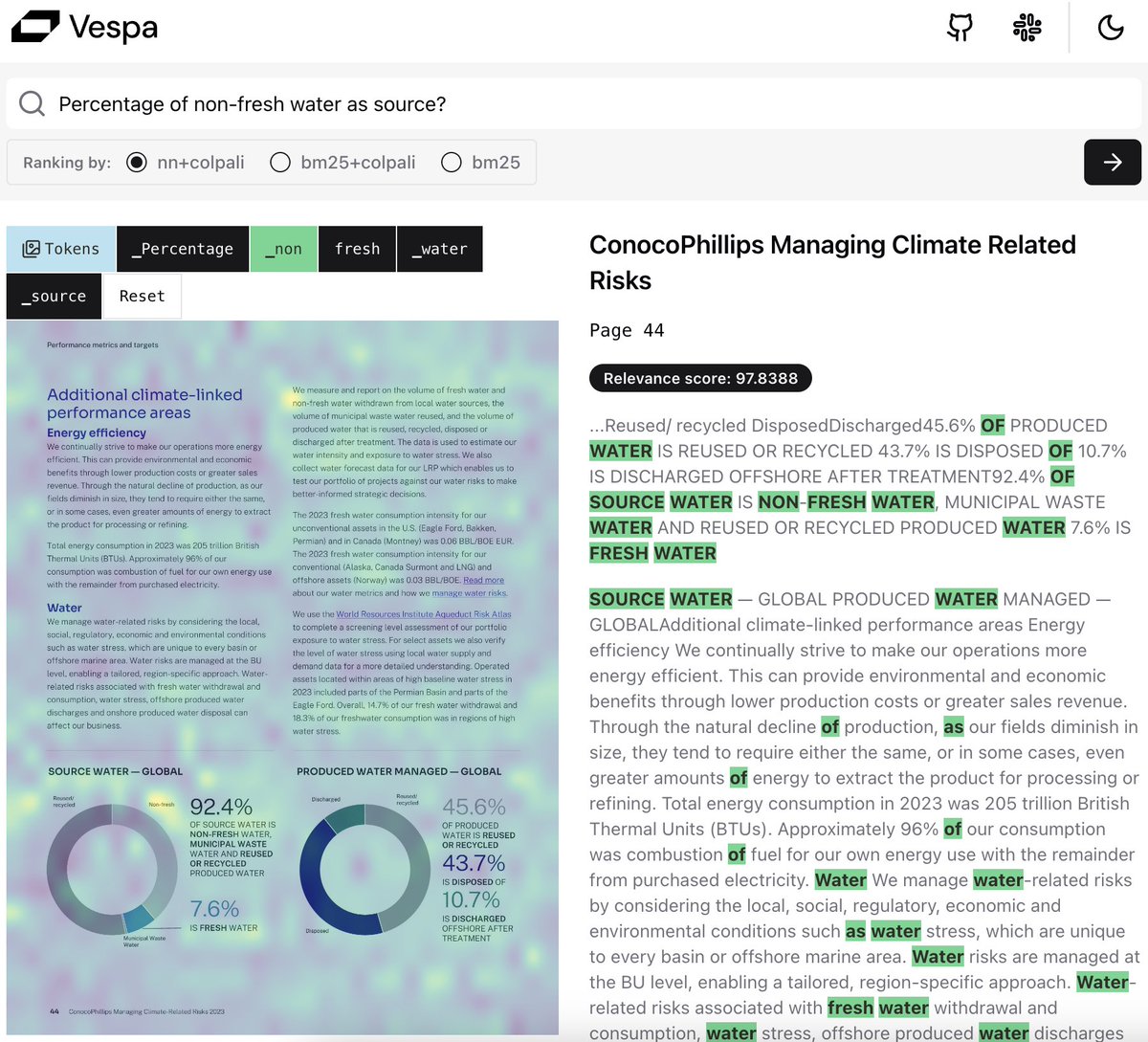
Hybrid retrieval and ranking that scales to billions of PDF pages. It combines extracted text and visual embeddings from the ColPali architecture. Fully Interpretable.
Notice the highlight of the term _non in the image of the page. Excellent work led by @thomas_thoresen! 🚀
Yesterday, @linuxfoundation announced the new OpenSearch Software Foundation, with Amazon transferring the 3½ year old @OpenSearchProj to LF.
This is something I am personally very proud of, because I worked on the 6-page proposal to move OpenSearch to a neutral foundation at Amazon.
https://t.co/WkM7uAjv2l
This is amazing!
A fresh 33M MiniLM-based ColBERT checkpoint that beats the original checkpoint (110M) and many other single-vector models on BEIR. 96 dimensions per token vector.
With Vespa binarization support, this means only 12 bytes per token vector. I will add an ONNX version soon so you can import it directly into @vespaengine https://t.co/ReNx387jcM
I've always been a massive fan of MiniLM, and our work from 2021 used only MiniLM for an end-to-end retrieval and ranking pipeline (single-vector => multi-vector => cross-encoder). https://t.co/Mz6eVSg8Jd
Things we've been up to in May:
👓LLM integration: Build complete RAG applications on Vespa.
🎰Embed to multiple representations at once: An oom cheaper vector search by creating a small vector for search and a larger for ranking.
🎯Combine fuzzy search and prefix match: Ideal for typeahead search.
🚴10x faster export-import between Vespa clusters.
🐎30-900% faster vector search from distance calculation and conversion optimizations.
🐍Lots of new pyVespa features.
#Apache#Lucene finally gets support for #madvise in its MMapDirectory, so the OS kernel (Linux/macOS) can better schedule paging of index pages into RAM. Hopefully solves issues with merging and page cache. Works with #Java 21 or later. #ProjectPanama https://t.co/dnz3LUE2lb