As we await the release of the Big Potato model, GPT-5.4 Pro delivers what I understand to be its most impressive contribution to math to date. Erdős problem #1196 appears to have fallen to the model - solved in one shot after 80 minutes of thinking.
Jared Lichtman: "I care deeply about this problem, and I've been thinking about it for the past 7 years. I'd frequently talk to Maynard about it in our meetings, and consulted over the years with several experts... The problem was not a question of low-visibility per se. Rather, it seems like a proof which becomes strikingly compact post-hoc, but the construction is quite special among many similar variations."
I used to lead the Geopolitics Team at OpenAI. Today I published a few observations on frontier AI companies and their military usage policies from my perspective as a former employee and researcher active in the int’l security space. (Link below.)
Is this what people actually fear, or just the mainstream media agenda? I hope the answers from @steipete are helping to understand what is coming and to start to prepare for it, instead of building up anxiety.
As most of you know, I'm from Germany, so I was able to watch the entire interview with Peter Steinberger on "Zeit im Bild."
It was incredibly painful. Not because of Peter's answer, but because the journalist's questions-typically German-Austrian - almost exclusively revolved around whether we should be afraid of AI, whether data privacy is being respected, what dangers OpenClaw poses, and so on.
The hottest topic in the world was talked down. Instead of sparking curiosity and enthusiasm among viewers, the program ultimately only stirred up more anxiety and resentment. A damning indictment of Europe.
As most of you know, I'm from Germany, so I was able to watch the entire interview with Peter Steinberger on "Zeit im Bild."
It was incredibly painful. Not because of Peter's answer, but because the journalist's questions-typically German-Austrian - almost exclusively revolved around whether we should be afraid of AI, whether data privacy is being respected, what dangers OpenClaw poses, and so on.
The hottest topic in the world was talked down. Instead of sparking curiosity and enthusiasm among viewers, the program ultimately only stirred up more anxiety and resentment. A damning indictment of Europe.
@pvncher I think https://t.co/I2RyGWRorB is a great source to get a feeling for when an Automated Coder will arrive. The two models from @DKokotajlo and @eli_lifland put it for 2027 at ~20% and ~18% chance. They are also "highly uncertain about this ...".
AI 2027 laid out a detailed scenario for how AI would progress from 2025 through 2027, including quantitative predictions and qualitative descriptions of the AI landscape. Now that we're in early 2026, we can grade how its 2025 predictions compare to reality! 1/6
Thread of things you can do on our timelines+takeoff website https://t.co/Wqzzxuk7rH
Includes adjusting model parameters, testing simplifications, sharing trajectories, reading about the model and why we created it, viewing our forecasts, and analysis of model behavior.
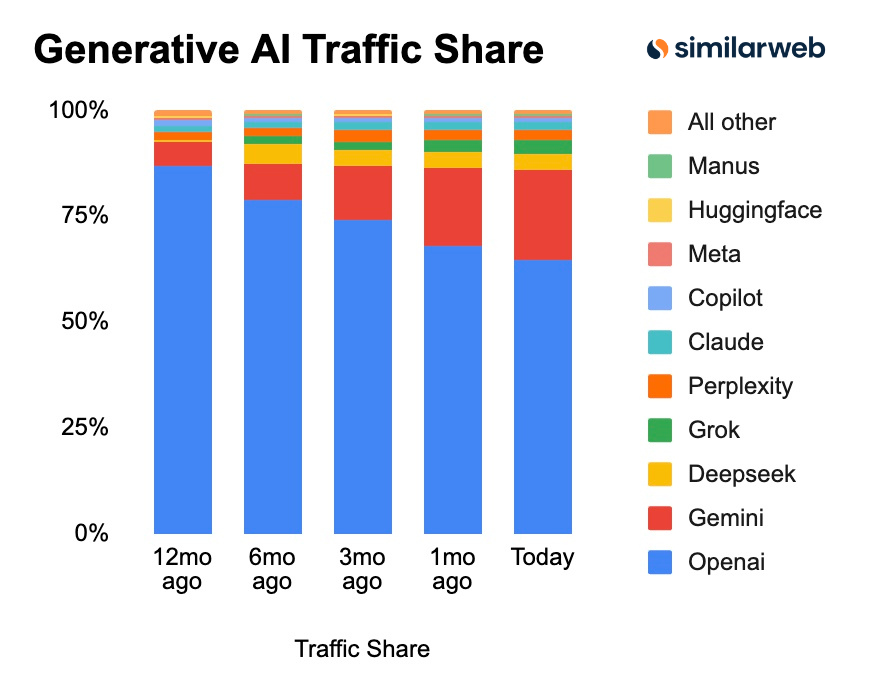
It was to be expected that Open AI loses ground. They kind of started with 100%.
Google might have been late to the party but they where preparing for it. This nice documentation about DeepMind and Alpha Fold shows it nicely https://t.co/sFFuOelxnR.
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask:
"What do you think about xyz"?
There is no "you". Next time try:
"What would be a good group of people to explore xyz? What would they say?"
The LLM can channel/simulate many perspectives but it hasn't "thought about" xyz for a while and over time and formed its own opinions in the way we're used to. If you force it via the use of "you", it will give you something by adopting a personality embedding vector implied by the statistics of its finetuning data and then simulate that. It's fine to do, but there is a lot less mystique to it than I find people naively attribute to "asking an AI".
I’ve been thinking about something for a while now, which I thought I'd share. I don't usually do long-form posts or talk too personally, but here we go.
I love Bitcoin. It changed the direction of my life and shaped the work I do every day. But over the past year, something in me has felt muted. I haven’t been as vocal, as present, or as energised as I've been previously. And I’ve struggled to put my finger on why, until now.
Bitcoin hasn’t changed… but the direction of its narrative has.
Since the ETF era began, Bitcoin has increasingly been viewed through an institutional lens: a sound-money financial instrument curated by large institutions. And while there’s nothing inherently wrong with institutional adoption, something about that shift has quietly pulled the story away from what first lit a fire inside me about Bitcoin - a decentralised, permissionless, global network that empowers individuals.
Many people I’ve spoken to recently feel the same shift.
To be clear, ETFs and institutional growth are NOT a bad thing; they’re actually great for driving awareness of Bitcoin.
But Bitcoin’s value grows when more people strengthen its decentralised, self-sovereign network. That’s harder to do when more new entrants buy Bitcoin through ETFs, where the coins sit with a centralised US custodian. That flow doesn’t strengthen the network or advance Bitcoin self-sovereignty.
The roots of Bitcoin - sovereignty, resilience, freedom - still sit with us. With individuals. With people who hold their own keys, run nodes, transact, learn, and push the world steadily closer to decentralisation. We need to water those roots so that the tree can keep growing.
If we want Bitcoin to succeed in the way that matters most, we can’t rely on institutions to carry the narrative for us. They never will. That responsibility sits with us. And on reflection, I haven’t been carrying my share of it lately.
So I’m going to change that. I want to help strengthen the part of Bitcoin that truly matters: self-custody, decentralisation, and personal sovereignty. I’m going to start talking about these more, alongside the data and analysis I already share.
Bitcoin’s value is the number of people who secure it, who build on it, and who use it as a self-sovereign asset. If that fades, the magic of internet money may fade too.
Small actions compound. Every person who secures their own Bitcoin strengthens the network - and conversations about decentralisation strengthen the culture around it.
Right now, the market is still adjusting to this new era. But zooming out, I’m as optimistic as ever - because if we combine institutional awareness with real usage and a renewed focus on self-custody and decentralisation, Bitcoin’s future is incredibly bright.
Thanks for listening.
The future is bright, the future is orange. 🧡
As a developer, you're not paid to code
You're paid to solve problems
The earlier you get it, the better for you
When you get the problem, try to solve it without coding
If you must code, then do it
It took me many years to learn this
Don't make my mistake
There’s going to be split between two types of teams or companies for the foreseeable future.
Those that re-engineer their processes to take full advantage of AI agents with their given limitations, and those that wait until they’re good enough to not re-engineer anything.
To take full advantage of AI agents today, your workflows must be designed around the idea that AI agents need a lot context to be effective. By default you have a super-intelligent worker but they have no idea who they work for, what their job is, what the best practices are, what the guidelines are, how to work with the right data, and so on.
Most AI agent failures are just wishing this wasn’t true, and imagining AI will just figure all of these things out on its own. This won’t happen anytime soon for a variety of reasons.
The companies and teams that retool their workflows to get agents the right context will be ones that actually can get the most gains from agents right now.
But this will look very different from how most teams work right now. It will mean having well documented processes, data that is set up to actually get to an agent easily, hyper precise goals and prompts, and ultimately mindset that the new human in the loop element is not being involved in every single step of an agent, but editing and reviewing its final output.
The companies and teams that started thinking this way will be able to take advantage of agents right away, and they’ll blow past the ones that don’t.