Nothing’s reaped out of nothing, for free like that. Noooo!
Everything does result from:
Dedicated and Sincere Work + Heaven’s Approval
Indeed, thou shalt reap what thou sowest.
The next hot programming language is… markdown.
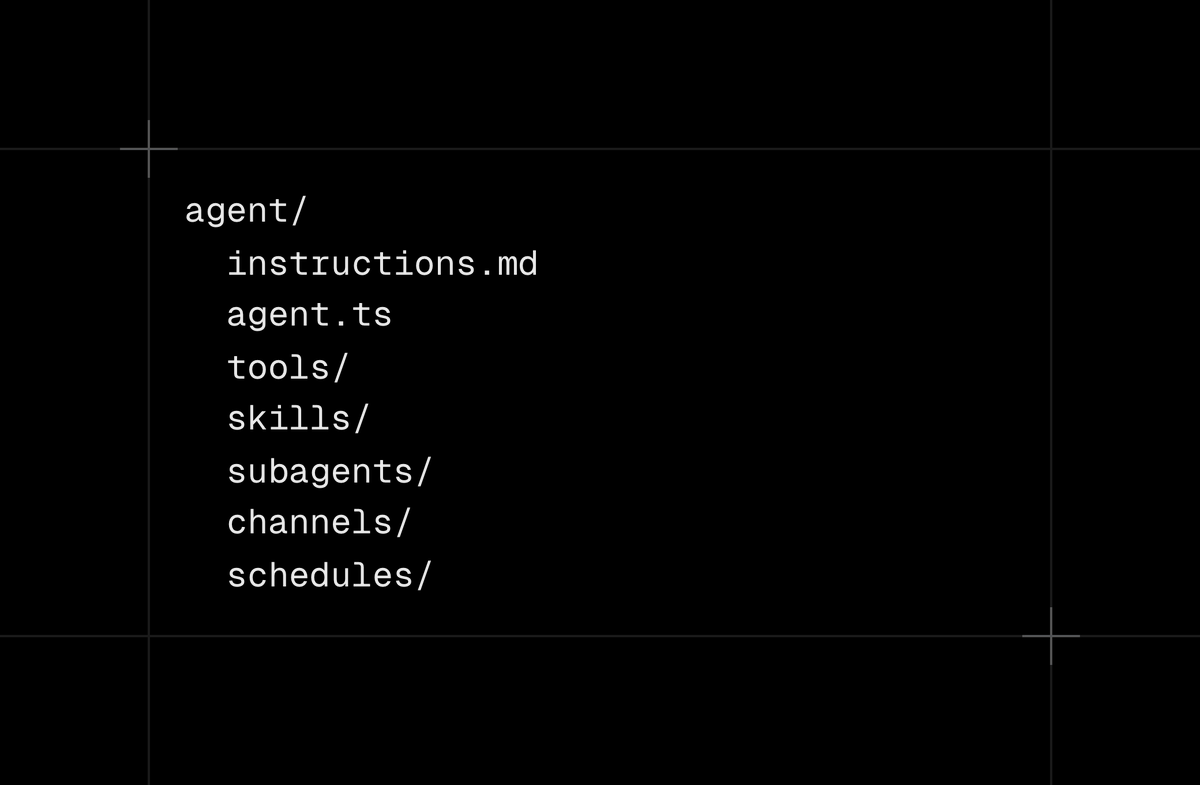
A minimal eve agent:
📂 𝚊𝚐𝚎𝚗𝚝/
📄 𝚒𝚗𝚜𝚝𝚛𝚞𝚌𝚝𝚒𝚘𝚗𝚜.𝚖𝚍
📂 𝚜𝚔𝚒𝚕𝚕𝚜/
📄 𝚢𝚘𝚞𝚛-𝚎𝚡𝚙𝚎𝚛𝚝𝚒𝚜𝚎.𝚖𝚍
Deployable in one command: 𝚟𝚎𝚛𝚌𝚎𝚕.
It’s the most accessible programming has ever been. And likely will ever be, at least for the generation of software fully defined and controlled by us humans.
(As a fun fact, one of the initial prototypes for eve was codenamed 𝚕𝚊𝚜𝚝 by @timolins, both in homage to ‘@nextjs for agents’ but also in recognition of how enduring eve’s design feels to us.)
Agents are motivating so many healthy software habits. Open APIs, documentation (skills), tests (evals), Unix (CLIs), payment & commerce protocols, even wide 𝙰𝚌𝚌𝚎𝚙𝚝 use (markdown/json/html).
The original vision of the WWW coming to life before our eyes.
Earlier today, ~3% of Claude Code Max and Pro users hit a bug that showed an incorrect weekly usage limit, and in some cases blocked them from sending messages.
This is fixed, and we're resetting 5-hour and weekly limits for everyone affected. Apologies for the disruption.
As AI takes on longer, higher-stakes tasks, we want models to carry beneficial and safe behavior into new domains beyond their training—and maintain it under pressure.
That’s the idea behind our new research on training models to be broadly and persistently beneficial. https://t.co/6Yw45s1RRq
Agent Arena has been live for 2 weeks, with 10 more models now on the new leaderboard. Two highlights worth mentioning:
- GLM-5.2 (Max) by @Zai_Org enters the top 10. The strongest open-weight result we've measured, at +9.4% confirmed success and +14.9% praise-vs-complaint relative to baseline.
- Claude Fable 5 by @AnthropicAI debuted at #1 across nearly every metric before the U.S. government directive to suspend access. It’s a useful upper bound for where the frontier currently sits.
In Agent Arena, we measure models on millions of real-world, long-horizon agentic tasks from a global community of users. Models can access web search, filesystem, and terminal tools to complete complex workflows. The leaderboard measures model performance on outcomes relative to the average model using a causal tracing methodology.
Which model will enter the Arena next? Read more about the methodology and check out the live leaderboard (links in thread) 👇
Introducing V, a personal agent template.
Built on Eve. Works on iMessage, Slack, and web. GitHub and Linear tools with long-term memory.
https://t.co/gy7xKWSrle
GPT-5.5 Instant is now on par with our frontier Thinking models for health-related questions.
Every week, more than 230 million people turn to ChatGPT with health and wellness questions, and GPT-5.5 Instant is better at recognizing when urgent care may be needed, asking for relevant context, explaining uncertainty, and making complex information easier to understand.
Because GPT-5.5 Instant is available to all free users in ChatGPT, these improvements can help more people.
Physician-led evaluation was critical to making these major intelligence gains.
New Frontier Red Team blog: Phase 2 of Project Fetch, where we test how well Claude can program a robodog.
Opus 4.7, on its own, was ~20x faster than last year's best human team aided by Opus 4.1. (The robodog, alas, still failed to fetch a beach ball.)
https://t.co/CgbBtRf85e
The moment President Trump signs the Iran deal at the Palace of Versailles.
The agreement was finalized during a dinner hosted by French President Emmanuel Macron inside the historic palace.
The signing marked a major diplomatic milestone after months of negotiations aimed at ending the conflict between the U.S. and Iran.
Here's something fun I've been thinking about.
Agents like eve are increasingly just files.
The shadcn registry is a protocol for distributing files.
could the registry be the distribution model agents need?
Every open-source project should be engineering agent loops right now.
We've found success managing @warpdotdev with loops for:
- Issue triage
- Spec generation for larger features
- Code review
- Even letting agents self-improve their Skills on a cron