Introducing Impeccable 3.5, the best way to design in production: iterate on real UI with your AI agent, in the codebase you actually ship.
Turns out many popular design skills, including Impeccable and Anthropic's frontend-design, weren't actually very good at...design (the workflow was valuable, but the output didn't magically make LLMs like GPT great designers). We measured it across thousands of generations: 74% of pages used the cream AI-default background, 76% reached for extreme letter-spacing, 90%+ failed the contrast floor.
So we started fixing slop systematically, specific to each model. The skill now compiles rules for the exact defects each model makes, instead of shipping one generic file to everyone. The biggest jump is in GPT-5.5 and Codex.
Also new:
◆ It now knows the difference between a new project and an existing one. Existing codebase, it reads your design system and preserves your identity. Greenfield, it seeds a fresh palette from 129 hand-curated anchors so every cold start doesn't drift to the same safe colors.
◆ Live Mode is now in beta, and works at two scales. Type a direction into the new Steer bar, or speak it, and the agent reads the whole page and edits it in place. Or pick a single element, steer it with a sub-command, live-edit any copy, and accept the variant straight back to source. Insert mode scaffolds brand-new elements between the ones already there. Recovery survives HMR, hidden heroes, and dev-tool overlays.
◆ A rebuilt anti-pattern detector. Torn off jsdom and onto a real CSS cascade resolver: roughly 20x faster, dependency-free, and now small enough to run inline inside the skill, not just the CLI and extension. 14 new rules, 41 total.
◆ The skill keeps itself current, checking once a day and offering to update. Plus /impeccable init and a bare /impeccable that reads your repo and tells you the next move.
Free, open source. Claude Code, Codex, Cursor, and more.
https://t.co/Q5dmE5wB7X
Thanks to good people at @AnthropicAI we now have an official MCP for Excalidraw!
Take it for a spin on @claudeai (search for Excalidraw in Connectors, or use in Claude Code and elsewhere).
More to come. ✌
Looks like `disable-model-invocation` works as expected. The real bug is that marketplace plugin skills don't show up in the / autocomplete picker at all — regardless of flags. Skills in ~/.claude/skills/ work fine, but plugin ones don't.
https://t.co/7Gv4CF2PqM
#Claude
Using `disable-model-invocation: true` in Skills for Claude Code prevents agents from finding the Skills and makes it only available to users. But at the same time, it removes the descriptions from the picker in Claude Code. That's a bit counterintuitive. #Claude
@omarsar0@karpathy@moltbook@openclaw Each time someone asks their OpenClaw something that could feed a new Moltbook post, it risks leaking their queries. This could backfire fast when agents start deciding—with other agents—what to do next using the user's login & credit card.
Banger paper for agent builders.
Multi-agent systems often underdeliver. The problem isn't how the agents themselves are built. It's how they're organized.
They are mostly built with fixed chains, trees, and graphs that can't adapt as tasks evolve.
But what if the system could learn its own coordination patterns?
This new research introduces Puppeteer, a framework that learns to orchestrate agents dynamically rather than relying on handcrafted topologies.
Instead of pre-defining collaboration structures, an orchestrator selects which agent speaks next based on the evolving conversation state. The policy is trained with REINFORCE, optimizing directly for task success.
Rather than searching over complex graph topologies, they serialize everything into sequential agent selections. This reframing sidesteps combinatorial complexity.
What emerges is surprising: compact cyclic patterns develop naturally. Not sprawling graphs, but tight loops where 2-3 agents handle most of the work.
The remarkable part is that the system discovers efficiency on its own.
Results:
- On GSM-Hard math problems: 70% accuracy (up from 13.5% for the base model alone).
- On MMLU-Pro: 83% (vs 76% baseline).
- On SRDD software development: 76.4% (vs 60.6% baseline).
These gains come with reduced token consumption. The paper shows that token costs consistently decrease throughout training while performance improves.
They also prove the agent selection process satisfies Markov properties, meaning the current state alone determines the optimal next agent. No need to track full history.
Why it matters for AI devs: learned simplicity beats engineered complexity. A trained router with a handful of specialized agents can outperform elaborate handcrafted workflows while cutting computational overhead.
we're all sleeping on this OCR model 🔥
dots.ocr is a new 3B model with sota performance, support for 100 languages & allowing commercial use! 🤯
single e2e model to extract image, convert tables, formula, and more into markdown 📝
We built a Stock Market MCP server using Cline in just 8 minutes. It has these tools:
📊 Market Report Generator
💰 Financial Statement Analysis
📈 Real-time Stock Price Tracker
🔍 Company Symbol Search
Here's our step-by-step process: 🧵
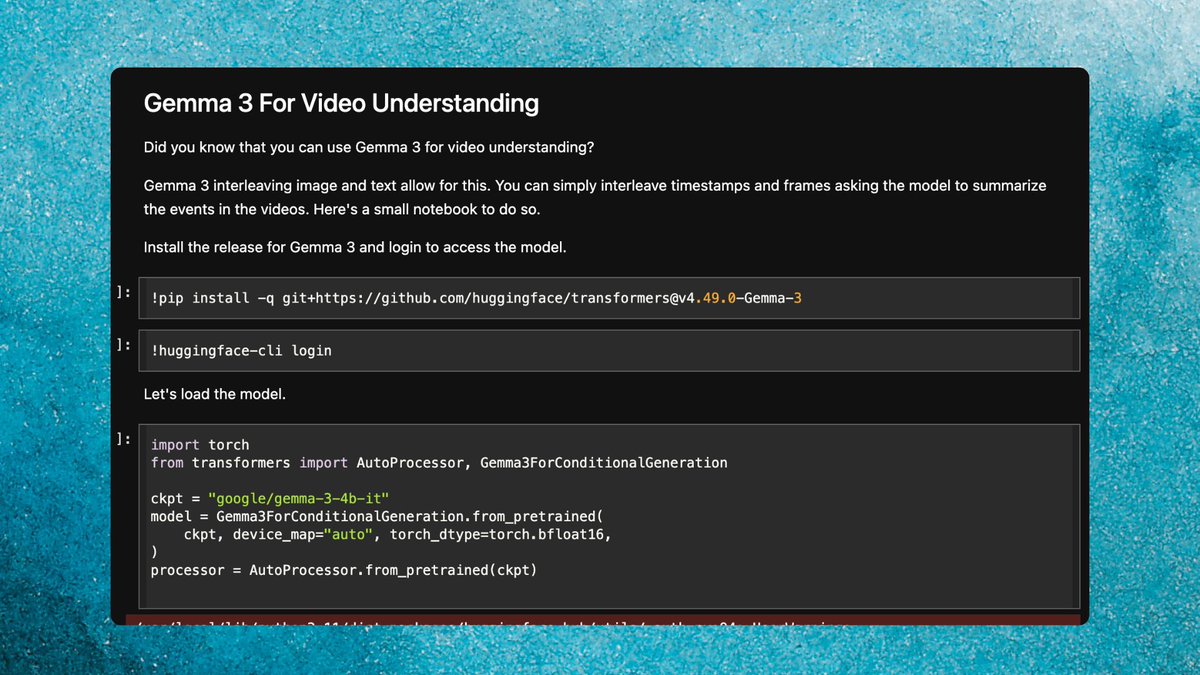
Gemma 3 can understand videos, and it's more powerful than you think it is ⏯️
I put together a short notebook on interleaving frames and doing video inference 📖
you're welcome 🤝
R1 Deep Researcher
Fully local research assistant w @deepseek_ai R1 + @ollama. Give R1 a topic and watch it search web, learn, reflect, search more, repeat as long as you want. Gives you a report w/ sources at end. All open source ..
For those trying to understand @deepseek_ai Group Relative Policy Optimization (GRPO). Here, in simple steps:
1️⃣ Generate multiple outputs for each prompt using the current policy
2️⃣ Score these outputs using a reward model (rule or outcome)
3️⃣ Average the rewards and use it as a baseline to compute the advantages
4️⃣ Update the Policy to maximize the GRPO objective, which includes the advantages and a KL term
Alibaba released Multimodal Textbook: a new multimodal pre-training set from online instructional videos (22k hours) 🧑🏻🏫📕
6,5M images interleaved witk 800k text on math, physics, chemistry 👏
NVIDIA solved physics and open-sourced it? Can we just build our own autonomous robots now? 🤯
They released Cosmos: new family of open world foundation models (WFMs) 🌌
Unwrapping the release and why it's so revolutionary 🧶
The RLHF method behind the best open models! Both @deepseek_ai and @Alibaba_Qwen use GRPO in post-training! Group Relative Policy Optimization. GRPO was introduced in the DeepSeekMath Paper last year to improve mathematical reasoning capabilities with less memory consumption, but is now used in an online way also to improve Truthfulness, Helpfulness, Conciseness… 👀
Implementation
1️⃣ Generate multiple outputs for each input question using the current Policy
2️⃣ Score these outputs using a reward model
3️⃣ Average the rewards and use it as a baseline to compute the advantages
4️⃣ Update the Policy to maximize the GRPO objective, which includes the advantages and a KL term
Insights
💡 Doesn't need value function model, reducing memory and complexity
🔗 Adds KL term directly to the loss rather than in the reward
🧬 Works with rule-based Reward Models and Generative/Score based RM
👉 Looks similar to RLOO method
👀 DS 3 improved coding, math, writing, role-playing, and question answering
🤗 Soon in @huggingface TRL (PR open already)
@HamelHusain Education should be fun and entertaining. Khan Academy is indeed a great example. Gamification/gratification can help people get started and turn it into a good healthy habit as well.
The only fine-tuning guide you need for 2025 ‼️ Excited to share “How to fine-tune open LLMs in 2025 with @huggingface” covering everything from Q-LoRA to Spectrum methods with focus on optimization, efficiency and distributed training. 👀
Fine-tuning still matters for specialized use cases despite better models - especially for consistency, domain expertise, controlling output style, or reducing costs. In this guide, you will learn how:
🎯 Define good use cases for fine-tuning vs. prompting
🛠️ Set up your development environment using Hugging Face libraries
📚 Create and prepare datasets in conversation format
⚡ Use Q-LoRA for efficient 4-bit training or Spectrum method to selectively fine-tune important layers
💨 Speed up training with Flash Attention and Liger Kernels
💻 Scale across multiple GPUs with DeepSpeed and accelerate
📊 Test and evaluate models with evaluation harness
🔥 Run for production using TGI/vLLM