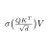Gaussian Splats are great, but they had one drawback, until now: Collision detection was impossible, so it wasn't viable for gaming.
But now, there is a method that turns the splats into voxels for the collision detection, and it works great:
Introducing InfiniteDiffusion, my independent paper accepted to #SIGGRAPH2026!
I have one RTX 3090 Ti. No funding, advisors, or team. By day I'm a new grad SWE at Walmart.
The paper has two main contributions:
- InfiniteDiffusion: a new approach to infinite generation with diffusion models.
- Terrain Diffusion: the world’s first learned procedural terrain generator.
Here’s why this matters, and how they are connected. 🧵
Thrilled to share that DEER-3D has been accepted to #ECCV2026! ✨
DEER-3D explores whether learning from grounding failures can be more effective than simply scaling 3D training data. We introduce an error-driven refinement loop that identifies predicate-level grounding errors, generates targeted 3D counterfactuals through minimal scene edits, and iteratively improves models with the resulting supervision. Across multiple 3D grounding and scene understanding benchmarks, DEER-3D consistently improves performance.
Updated paper and code coming soon. 🚀
👇🧵
Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
Planning with the views:
Can VLMs predict how each camera move changes the view, and plan many such moves ahead?
We introduce ViewSuite with 6 DoF camera control and ~165K task instances, testing:
Path-to-View
View-to-Path
Interactive View Planning
A sharp Planning Gap emerges:
+ can roughly "track" how camera action changes views
- cannot "compose" a plan towards a target view at all
We then try to teach VLMs with Reinforcement Learning. - RL cannot teach VLMs such planning ability, only 2.5% success rate with Qwen2.5-VL-7B.
+ With View Graph Distillation (our RL-Graph-SFT framework), 2.5% → 47.8%
Below, we answer these questions:
Q1. What are the failure modes?
Q2. How can we make RL work?
Q3. What has the model learned? Can we open up the model to see before/after? Can such spatial priors transfer to other view related tasks?
Led by @James_KKW, great to work with @LINJIEFUN@zhengyuan_yang@shiqi_chen17@wzenus@drfeifei@jiajunwu_cs Leonidas Guibas, Lijuan Wang.
A joint efforts with @StanfordAILab@StanfordSVL@MSFTResearch.
Can a VLM see without a vision encoder?
We trained one for $100, inspired by Gemma 4 12B.
Latency on an M3 Pro MacBook:
112 ms -> 1.1 ms for the image path
30% lower end-to-end image+LLM
The architecture is just:
patchify the image -> linear projection with pos embeddings -> LLM
Writeup:
https://t.co/yt0IKzsF7O
We're releasing MolmoMotion, a 3D motion forecasting model.
Given one or a few video frames, 3D points on an object, & an instruction like "Put the white bowl on the table," MolmoMotion predicts where those points will go over the next few seconds in a shared 3D world frame. 🧵
Introducing DreamX-World 1.0 — a general-purpose world model with 1 minute continuous generation, real-time interaction, precise camera control & multi-style support. Beta coming soon!
🌐https://t.co/U5NIvOi6rU
Github:https://t.co/zolKYnuWjT
#WorldModel#AIVideo
Scaling RL to long horizons remains a major challenge.
Long-horizon Q-learning (LQL) prevents compounding bootstrapping errors by bounding the difference in value over long horizons.
It shows large gains over 1-step TD and n-step returns!
Paper: https://t.co/OTk3M6cz8p
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
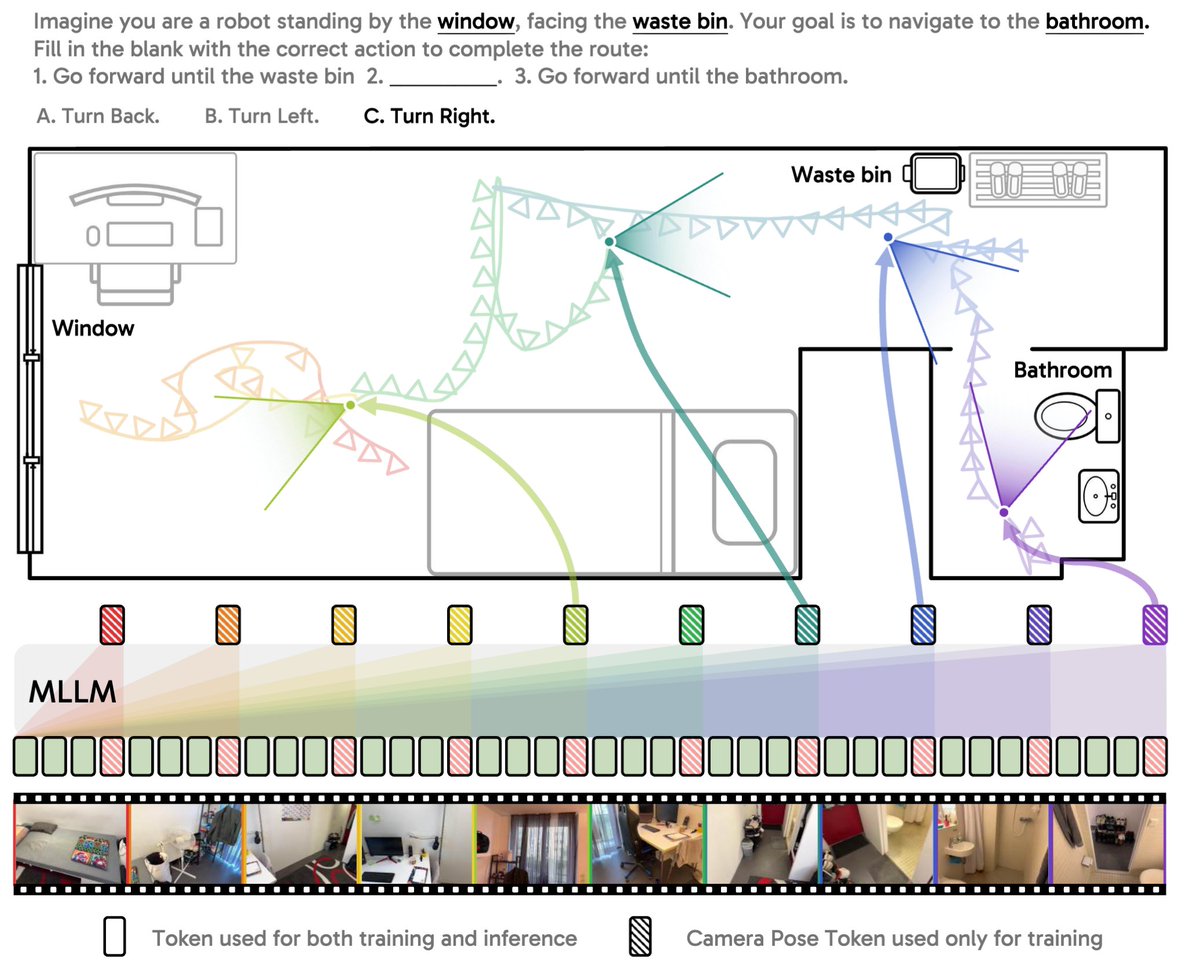
Camera pose matters for video understanding!
Today's MLLMs excel at recognizing activities, but still struggle with the underlying space and ego/object dynamics in video. We trace this gap to a missing piece: camera pose.
Introducing Cambrian-P: a multimodal LLM natively grounded in camera pose. (1/n)
LiteParse is really neat! It does a great job of extracting text from annoying layouts in PDFs (multiple columns for example)
It's only available as a Node.js CLI app, so I vibe-coded up this version that runs in a browser
We've added support for SAM-3 Lite-Text in the Transformers library! 🔥
> replaces the heavy text encoder in SAM-3 with a compact MobileCLIP student
> trained via knowledge distillation
> maintains performance while reducing parameters by 88%
3D-LLMs are "blind": They might be just guessing without seeing. And the previous benchmarks do not capture this! On our new benchmark Real-3DQA, you can notice all the popular 3D-LLMs get significant performance drop.
Check out more at https://t.co/0fRmkff9Oz.
📢Seen2Scene
Real-world 3D is incomplete, typically requiring training on synthetic scene data.
@QTDSMQ introduces visibility-guided flow matching, enabling training on real partial scans for scan completion & text-to-3D scene generation!
Check it out: https://t.co/jqZ164QX0W
If you find Claude Code with local models to be 90% slower, it's because CC prepends some attribution headers, and this changes per message causing it to invalidate the entire prompt cache / KV cache.
So generation becomes O(N^2) not O(N) for LLMs.
New project: parsync
When transferring a very large number of small files between two machines, it's ~61% faster than rclone, and ~686% faster than rsync. Easier to setup than rsync (no need for both machines to have it), but with its resuming and checksum capabilities.
We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible.
https://t.co/ApVzVsBuv1
By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly internalize new information or adapt to new tasks.
Biological systems naturally rely on two key cognitive abilities: durable long-term memory to store facts, and rapid adaptation to handle new tasks given limited sensory cues. While modern LLMs are highly capable, they still lack this flexibility. Traditionally, adding long-term memory or adapting an LLM to a specific downstream task requires an expensive and time-consuming model update, such as fine-tuning or context distillation, or relies on memory-intensive long prompts.
To bypass these limitations, our work focuses on the concept of cost amortization. We pay the meta-training cost once to train a hypernetwork capable of producing tasks or document specific LoRAs on demand. This turns what used to be a heavy engineering pipeline into a single, inexpensive forward pass. Instead of performing per-task optimization, the hypernetwork meta-learns update rules to instantly modify an LLM given a new task description or a long document.
In our experiments, Text-to-LoRA successfully specializes models to unseen tasks using just a natural language description. Building on this, Doc-to-LoRA is able to internalize factual documents. On a needle-in-a-haystack task, Doc-to-LoRA achieves near-perfect accuracy on instances five times longer than the base model's context window. It can even generalize to transfer visual information from a vision-language model into a text-only LLM, allowing it to classify images purely through internalized weights.
Importantly, both methods run with sub-second latency, enabling rapid experimentation while avoiding the overhead of traditional model updates. This approach is a step towards lowering the technical barriers of model customization, allowing end-users to specialize foundation models via simple text inputs. We have released our code and papers for the community to explore.
Doc-to-LoRA
Paper: https://t.co/87xEEpf0GN
Code: https://t.co/zBfQi2L9LW
Text-to-LoRA
Paper: https://t.co/emLRZ4Vdvo
Code: https://t.co/b9mrdoWWRB