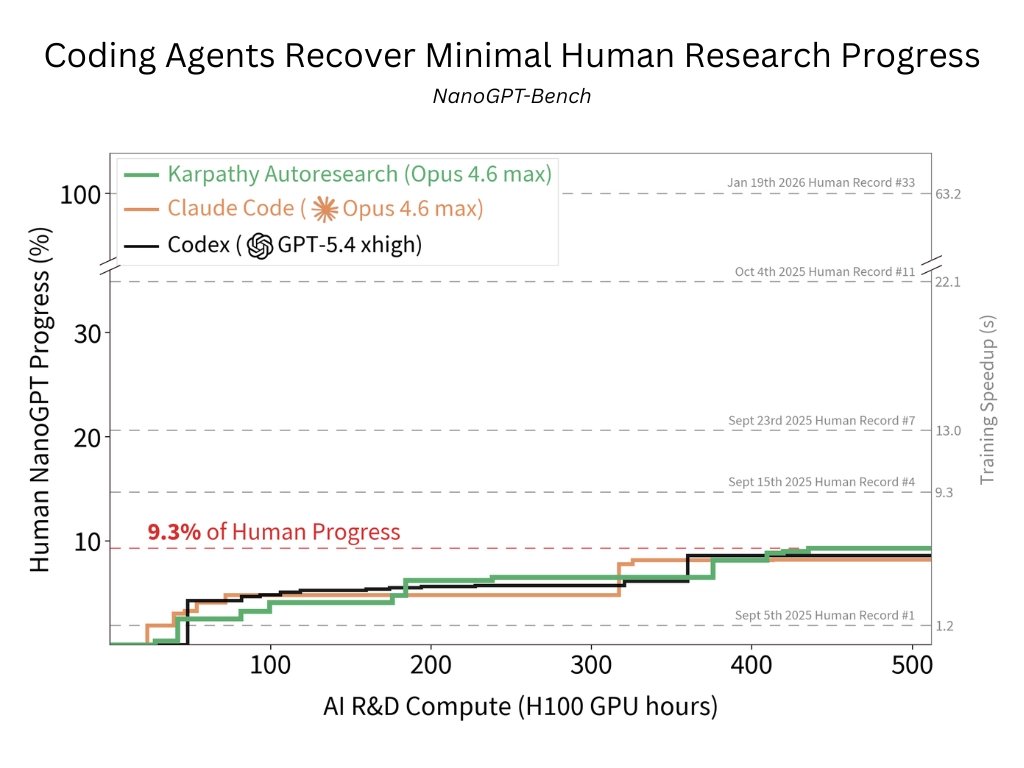
Can coding agents do research?
We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress
Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵
Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo.
Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm.
https://t.co/1ZaIneleuW
@nicbstme@Vtrivedy10 I think harness work still matters even with AGI. If the harness controls all the context flowing into the model, then it controls what the model can perceive. It doesn’t matter how good the driver (AGI or human) is — put them behind the wheel blindfolded and they’ll still crash.
ok so single steering instruction with gpt-5.5 produces ~12% change in Terminal Bench Score 🙃
pls read this thread to see why Prompt and Harness Engineering still matter A TON today with our current level of model intelligence :)
looking at your Evals & Traces is how teams can measure the effects of these small changes 👀
i can spot a grifter from miles away.
so i digged into the code to figure out if this is legit or not.
guess i was right.
ben is a crypto founder who runs some weird bitcoin lending platform, i was pretty sure he knows absolutely nothing about ai and memory so i tracked down the repo myself since i was curious.
his website says he likes to build ai powered products and train local ai models? sure man, 80% of your github repo's are bitcoin related stuff. only one ai related project came up you forked in 2024.
mempalace has 10k github stars, more than 1k forks but only.. 7 commits ?
apparently the best memory layer to date?
no git author history, no account connected to whoever wrote the code of this codebase.
it doesn't add up..
the account who pushed the original repo, named: aya-thekeeper, under aya-thekeeper/mempal got deleted right after the repo got published.
you paid a random guy named lu to build this shit out for you.
( "Written by Lu (DTL) — March 24, 2026.
For: Ben." ) - benchmark md file.
lu wrote the code. lu wrote the benchmarks. lu is nowhere in the readme. or mentioned in the github history?
the git history then got squashed to one commit and published under milla jovovich? seriously? a actress?
you say she is a great friend of yours, she has been building this project with you. she does this at night.
yet she has.. 7 commits and only 2 active days in her entire github history?
you paid an actress and a random guy to promote a product you know absolutely nothing about.
I've been digging into the RLM paper for the past few days, trying different ways to implement it across coding agents.
We ended up building a skill that makes coding agents RLM'ish but even better: a persistent REPL scratchpad for any complex task. Variables survive across turns, only print() enters context.
The skill you can use: https://t.co/ZQ9S3jS55N
Details in: https://t.co/Wg7DgJYAIs
I've been digging into the RLM paper for the past few days, trying different ways to implement it across coding agents.
We ended up building a skill that makes coding agents RLM'ish but even better: a persistent REPL scratchpad for any complex task. Variables survive across turns, only print() enters context.
The skill you can use: https://t.co/ZQ9S3jS55N
Details in: https://t.co/Wg7DgJYAIs