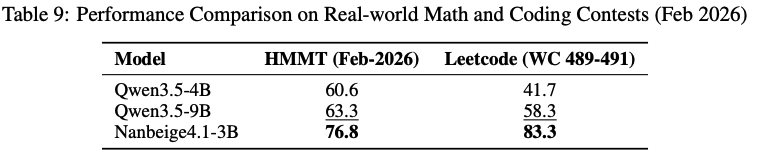
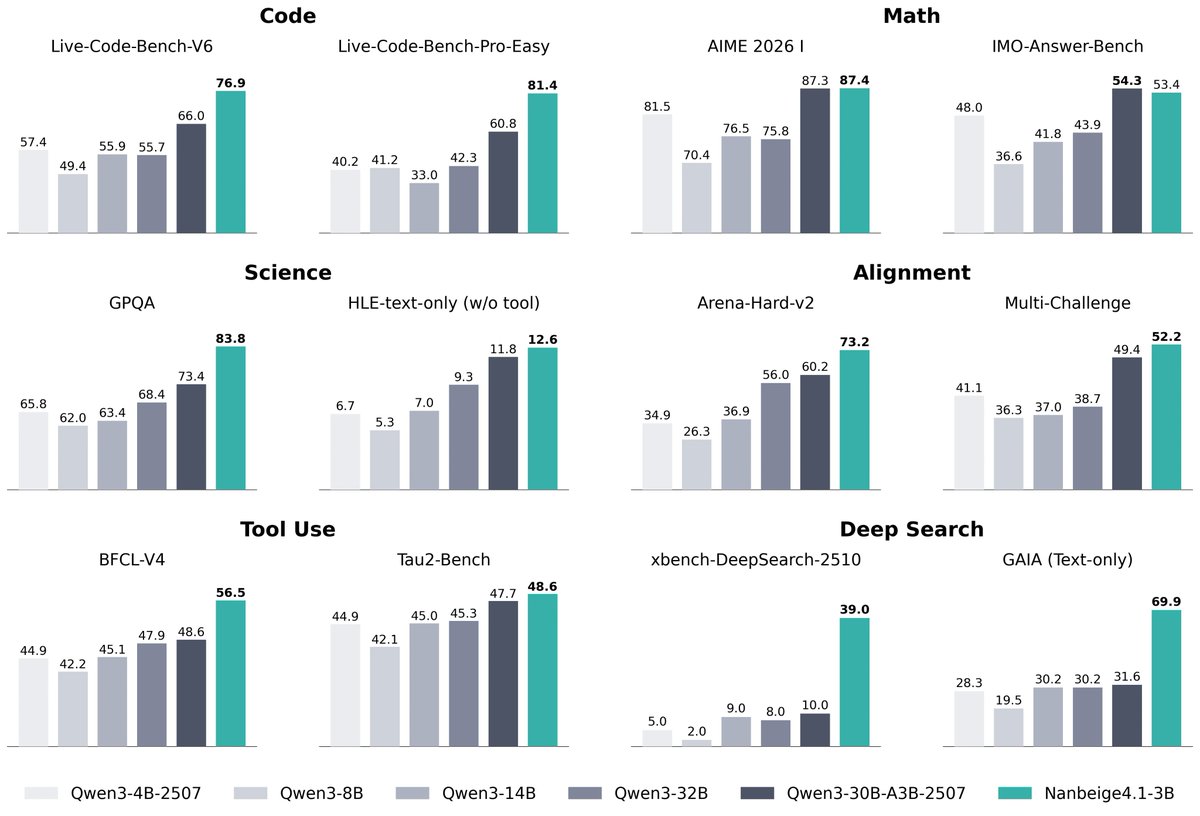
In both LeetCode's Weekly Contests (Weekly Contests 489–491) and the HMMT February 2026 (Harvard-MIT Mathematics Tournament), Nanbeige4.1-3B's performance not only significantly outperformed that of Qwen3.5-4B but also surpassed Qwen3.5-9B.
@teortaxesTex Institute of Computational Linguistics (Peking University), which originated in the South and North Pavilion (in Chinese: 南北阁, pinyin: Nanbeige)
@no82022340 @brite_owl @ModelScope2022 In Nanbeige 4.1, our coding optimization priority was competitive programming rather than frontend generation. Recent backtests on the past four LeetCode weekly contests reflect that focus.
@N8Programs Thank you again for your interest! We hope the model will attract wider attention and be tested by the community to evaluate its performance. The technical report will be released tomorrow—stay tuned! 🌟
@N8Programs We evaluate our Nanbeige4.1-3B on the five most recent LeetCodeWeekly Contests (Weeks 484 to 488). Each contest comprises 4 algorithmic problems, totaling 20 tasks. Our model successfully solved 17 out of 20 problems, achieving an overall pass rate of 85.0%.
@N8Programs Thank you again for your interest! We hope the model will attract wider attention and be tested by the community to evaluate its performance. The technical report will be released tomorrow—stay tuned! 🌟
Congrats! Now everyone with iOS devices can try the Nanbeige4.1-3B model immediately on their phone.
This model excels at tool calling and tends to output many thinking tokens, which requires a large context window. I set 12K context on my iPhone 16 Pro Max with 8K max output, and it didn’t crash. If you have a newer device, you can try higher settings, because this model really thinks a lot. I tested the search_web and fetch_url tools. It’s fully compatible out of the box with existing tool chains.
Try it on Privacy AI. It’s completely free for local models.
P.S. I ran it on a real iPhone and recorded the video via iPhone mirroring, which is why the refresh rate isn’t great.
@CWong24871 We are working on balancing this for the next version. The goal is to optimize the model itself to keep the smarts while cutting down on the reasoning steps automatically.