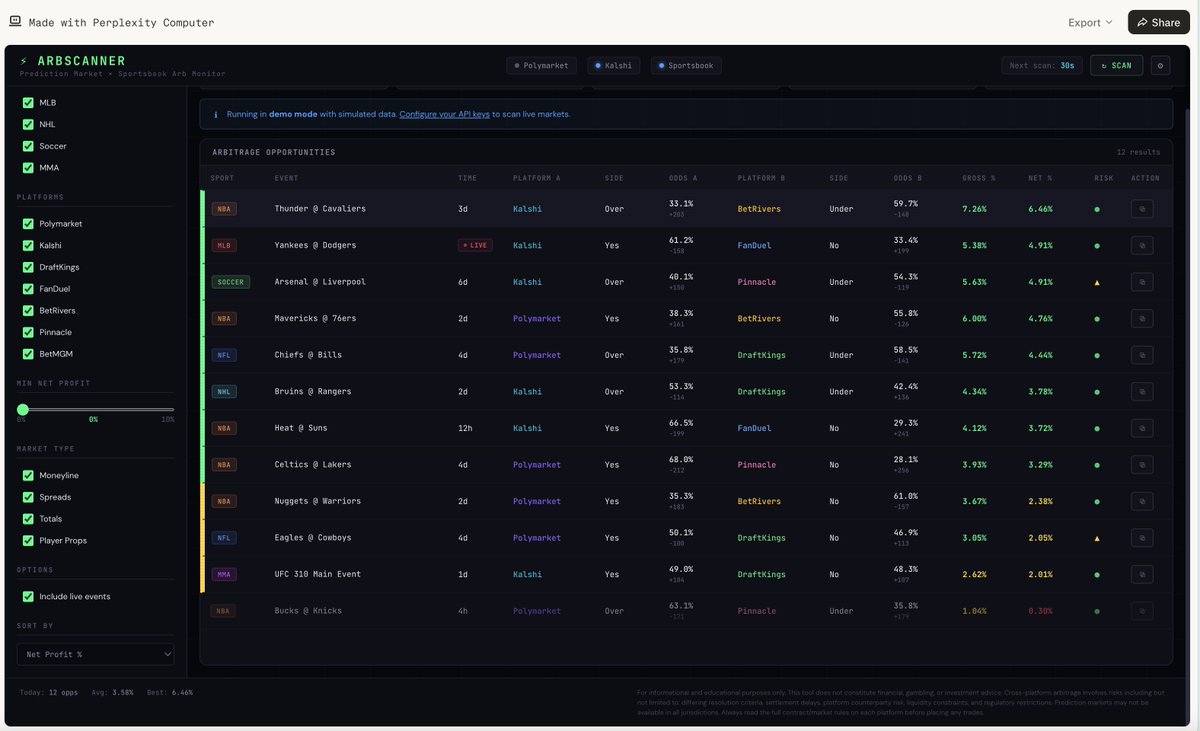
quants are cooked
just one-shotted arb
prediction markets (Polymarket, Kalshi) and sportsbooks (DraftKings, FanDuel) often price the same event differently. buy both sides across platforms and you lock in guaranteed profit regardless of outcome
this scans all of them in real-time and surfaces the gaps
free internet alpha. yw
https://t.co/D6LO3RhcYZ
we're going beyond traditional tool calls / MCPs to interact with the search stack. codegen is the most natural way for an LLM to drive search: the research tasks our users need require complex pipelines, customized per task.
so we're exposing the search stack as composable low-level primitives in an SDK. for example, from model-generated Python you can:
- build custom ranking pipelines
- run large-scale wide/grid search
- do map-reduce directly over our search index
the other big win is token efficiency. codegen pipelines things together and collapses many agent steps into a single program, resulting into far fewer round trips.
MiniMax Agent now uses @perplexity_ai Search.
We benchmarked 3 AI-native search providers across 700+ agent tasks. Perplexity delivered the best combination of answer quality and snippet density: more useful evidence per token, less irrelevant context, and lower end-to-end cost.
Compared with Serper, our previous default:
⚡Tool calls per task: 17.8 vs 32.6 (45% reduction)
💰Token usage: 94.6M vs. 162.3M (42% reduction)
🔍Pass rate: +2% increase
Total cost: 27% decrease in total cost savings
In agent workflows, search is not a one-shot lookup. It is a loop.
Better snippets mean better grounding. Better grounding means fewer searches, less context, better answers, and lower cost.
One good search can save 14 bad ones.
Now shipping in MiniMax Agent.
https://t.co/PeBPsHkJHU
> be perplexity
> launch computer
> serve hundreds of millions of queries + tasks per day
> realize every wasted token hurts
> compress web results 50x before they hit the context window
> same quality, cheaper context, faster answers
> skin in the game = the best eval
research here: https://t.co/eORrLgDwKS
We've productionized query-aware compression for faster, cleaner, more-accurate search.
Better context is better than more context.
Our system cuts context tokens up to 70% while improving answer quality.
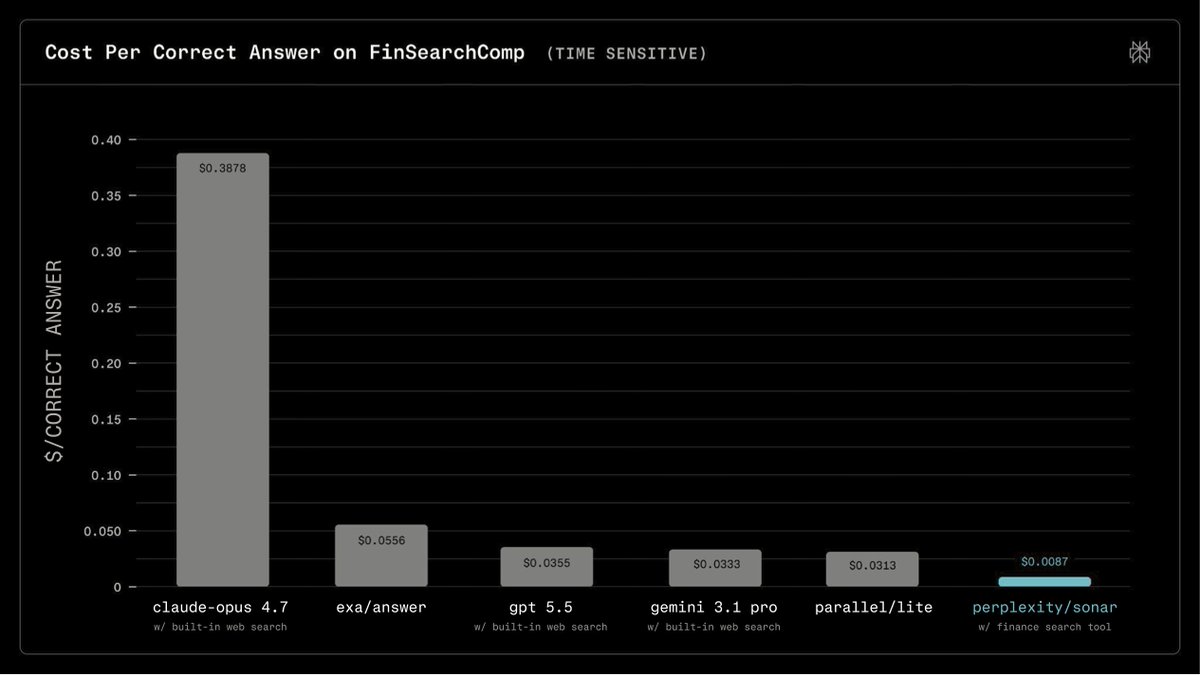
> real time finance info for agents is either
> really expensive through disparate set of premium data vendors and/or
> impossible to attain through public web search (or very token inefficient to parse through so much web noise)
> finance is one of our strongest verticals here at perplexity. so we invested a lot here
> now you too, can have you can now have the most performant (cheap, accurate, cited) finance data to ground your agents
> it's like 4-44x cheaper than existing paradigms
> oh btw - not charging you extra -- same $5 for 1K requests for queries
> yw, yw
more info: https://t.co/WhmWDvxpal
Finance Search is now available in the Perplexity Agent API.
In one tool call, developers can now retrieve licensed financial datasets, real-time market data, and cited web sources for agents that need current, verifiable financial answers.
having adhd and multiple agents is great and a force multiplier of productivity until you have like 15 orphaned agents you ran and forgot about (sorry bbs)
Today we're releasing Personal Computer.
Personal Computer integrates with the Perplexity Mac App for secure orchestration across your local files, native apps, and browser.
We’re rolling this out to all Perplexity Max subscribers and everyone on the waitlist starting today.