TOMORROW - we're hosting our @Techweek_ by @a16z AI Rooftop event with @datadoghq x @vercel ✨
Speakers include:
Director of Eng/AI - @diamondbishop
VP, Observability and AI - @nerdsane
Sr. Director, Eng - Andrey Sibirev (Vercel)
Moderator: @MadsMcIlwain (Vercel)
See if you can still snag a spot: https://t.co/OVNpACoum0
@vercel_dev
Below is some serious work from the Datadog team and I’m impressed the magnitude they were able to concieve and achieve in the timeframe of a hackathon (few hours, single day).
Also super happy to see our collective vision of Directed Software Evolution through our research projects like BitsEvolve and Temper showcased, with a clear demonstration of the importance of production observability as a feedback loop to achieve that.
Looking forward to the detailed write up.
Participated in the Autoresearch systems hackathon in SF, hosted by Modal, OpenAI, Raindrop and Antler, along with Jai Menon and Pranav Garg.
Our hypothesis was that by using Temper's governance and verification layers, and building tools on top of Temper, we could produce (1/8)
I know there are some efforts to write more precise specifications in prose with llms, I think we can do better by making more of those specifications
mathematically precise and observable.
In other words, can the specification become part of the system (mechanically executable), not just an input to the LLM?
If so, then those pieces would become
observable artifacts.
In that case now the LLM produces
a formal, observable specification
instead of only prose.
The developer can audit or even edit that spec. Model check for consequences independently (than just models doing it). Helps Develop an operational mental model that we are losing with being distant with code generation.
The spec can map more directly
to runtime code. With Observability like @datadoghq still instrumenting
the running system, it feeds production behavior back to the LLM and connect to the specs.
So now, when something fails,
the failure can trace back
to the spec.
I’m calling this paradigm “Higher Order Construction” with coding agents.
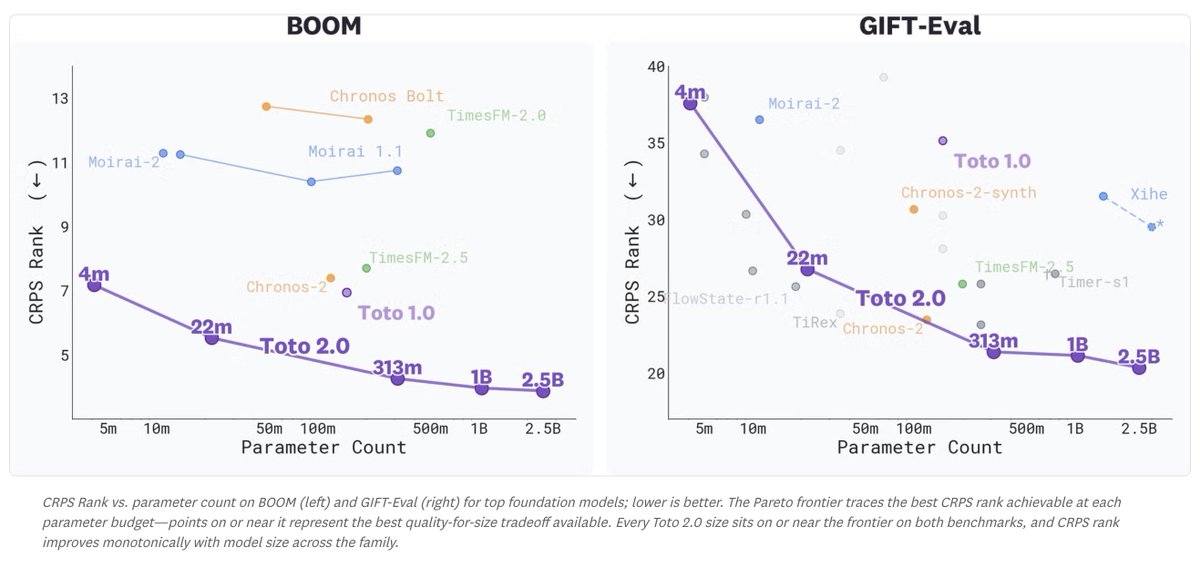
We’ve released a technical report for Toto 2.0 detailing the data, architecture, training recipe, μP/u-μP hyperparameter transfer pipeline, and benchmark results behind our 5-model open-weight release. Report linked below.
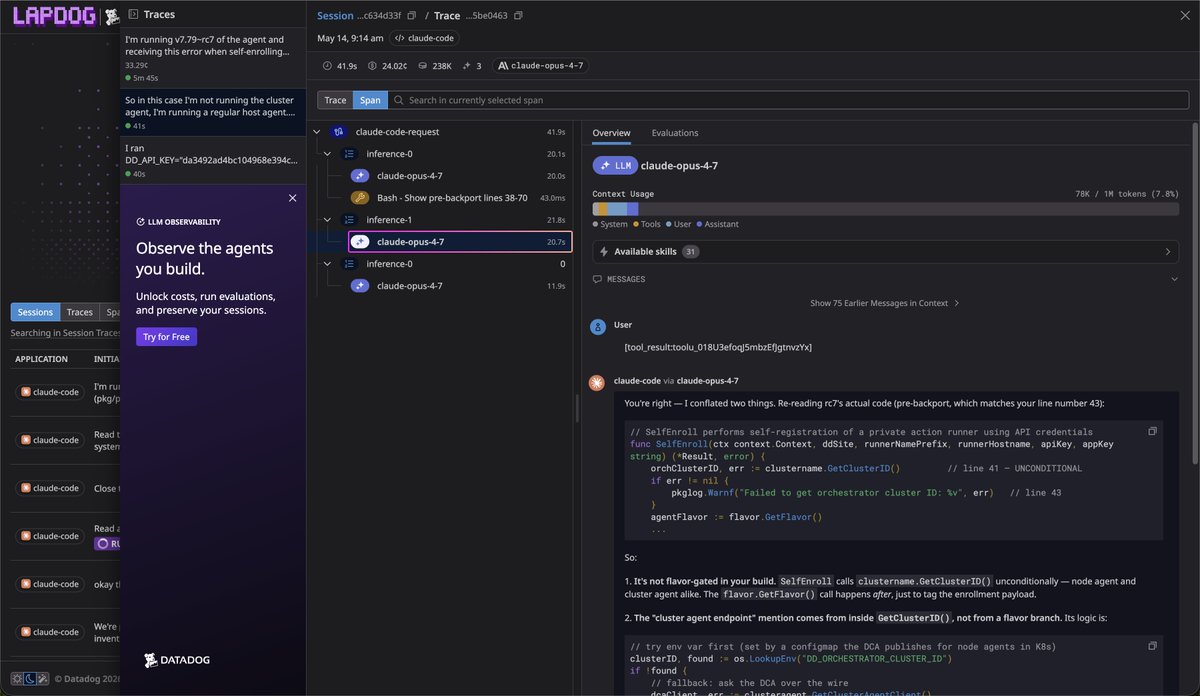
NEW from Datadog: it's Lapdog!
Ever wondered what your AI agent was actually doing?
Our latest free project runs locally and traces reasoning and tool calls in Codex, Claude Code, and Pi.
You can now see what your agent is REALLY doing, live: https://t.co/3dVBozFlPx
@a1zhang When @samuelcolvin texted me about Monty in Jan my very first instinct was to use that for the RLM REPL. Samuel sent me this PR - https://t.co/ZZQxD8hSq7. I don’t know if that limitation is still there.
Scaling finally works for Time Series Foundation Models.
Introducing Toto 2.0: open-weights TSFMs from 4M to 2.5B params, where every size beats the last from a single hyperparameter config. #1 on leading benchmarks: BOOM, GIFT-Eval, and TIME.
Most TSFM families ship multiple sizes that all perform roughly the same. This one doesn't.
“At Datadog, over the last four months, nearly 90% of engineers used coding agents for production work." - VP Observability Data, @nerdsane (@datadoghq)
Our very own Sesh spoke at Code w/ @claudeai last night covering the instances in which the eng teams at Datadog are utilizing agents for production work.
#codewithclaude #claude #claudecode @ClaudeDevs
@AnthropicAI Claude Design is so fun!
This release was so serendipitous because I just set up Katagami - a living design language library sourced and synthesized by agents based on rough ideas I wanna explore.
You can download a spec from Katagami, upload it into Claude Design as a design system and start applying it to your project from there.
I just tried it and it worked amazingly well.
Can’t wait to use this more in my future projects.
@AnthropicAI shipped Claude Design yesterday.
Now you can build a website in an hour, but you still need a design system. @arni0x9053 had this idea two weeks ago and decided to build it last weekend - an agentic system that sources, synthesizes, develops and organizes design languages. From idea to launch, 24 hours using Temper (a runtime that I have been working on).
Powered by:
@modal (@akshat_b), TensorLake @diptanu - sandboxes for agents doing work
Turso (@glcst) - transactional storage
@Railway - infrastructure/deployment
@Cloudflare - object storage
@datadoghq - observability
@pydantic Monty - agent REPL for Code Mode-style tool execution on Temper
@ExaAILabs - for web search.
Are chatbots in SaaS apps dead?
Chat is communication method, not a product. You can’t define “AI” or “bots” as chat. SaaS companies should think of shipping AI in two categories:
1. Autonomous: AI as a separate entity from the human
2. Assistant: AI as an extension of the human
Autonomy: these are essentially background agents that go in loops. You can think of them as doing stuff recursively, kicking off on set triggers or (ideally) events it detects itself. The holy grail here is a background agents that can wake itself up to things you care about, make evaluations and drive its own loop for a long time with proper and only necessary context, execute, iterate, and ask for your input/notify you when it’s done. Key here is that the agent owns its own loop. Claws work really well here to help orchestrate and coordinate for subtasks with personality.
Assistants: these are multi turn agents, that start reactively and triggers are defined at each turn. They tend to execute much more scoped tasks, but can still go off and explore and move recursively within a defined upfront instruction input. You play fetch with your assistant.
The goal of autonomy is catch things you wouldn’t have caught, to be always-on, and to act as an independent colleague. The goal of assistants is to be your superpower, to help you run your defined workflows, and to execute on your commands. The easiest mode of communication for both is chat. Artifacts are helpful to digest both loops and turns.
Our Assistant (Bits) is in Preview. And our next evolution of Autonomy is coming very soon…
The first thing I did at @tryramp was set up distributed tracing, structured logging, and metrics for Inspect, our background coding agent.
We now have full visibility in to everything the system is doing: the browser, CF workers/DOs, @modal sandboxes, database calls, etc.
Most importantly, Inspect now has visibility in to itself. It can self-triage runtime errors it encounters and create PRs to fix them.
Every morning, it reviews the past 24 hours of its own @datadoghq dashboard, identifies systemic issues, new errors, and long tail latencies, and has a summary + PR waiting for me at 9am.