Workflows are the biggest upgrade to Claude Code’s capabilities since skills and subagents.
I dove deep into it with @sidbid to figure out best practices, examples and more. I’m particularly excited about the non-technical tasks it enables for Claude Code.
WAIT. This is actually insane.
A solo dev just won the Anthropic hackathon, shipped a working product in 8 hours with Claude Code, and walked away with $15,000.
Then he open-sourced the entire stack.
153,000 stars on GitHub. Here's full setup:
→ 38 specialized agents (planner, security reviewer, debugger, code reviewer)
→ 156 skills loaded on demand (/plan, /tdd, /security-scan, /quality-gate)
→ 72 custom slash commands
→ AgentShield: 1,282 security tests across CLAUDE .md, MCP configs, hooks, skills
→ 3 Opus 4.6 agents running red-team pipelines (Attacker, Defender, Auditor)
→ Continuous learning layer that builds confidence across sessions
→ Coverage across 12 language ecosystems
This is what Claude Code looks like when someone treats it like infrastructure instead of a chatbot.
🚨 I just watched @bcherny (the guy who built Claude Code at Anthropic) explain why most of us are using Claude completely wrong.
In this 1h20 podcast, he exposes the massive gaps in our workflows:
> How ignoring CLAUDE.md costs you 14% of your baseline quality
> Hidden settings that 95% of users simply never open
> The background features that shift Claude's logic before you type a single word
> Massive workflows hiding behind one little toggle
Skip Netflix tonight.
Watch this instead.
Then read @eng_khairallah1’s article on 40 Claude Code ace features hiding in plain sight 👀↓
https://t.co/7ebEIYPIpE
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Mistakes happen. As a team, the important thing is to recognize it’s never an individuals’s fault — it’s the process, the culture, or the infra.
In this case, there was a manual deploy step that should have been better automated. Our team has made a few improvements to the automation for next time, a couple more on the way.
Understanding GPU Architecture from Cornell
https://t.co/B1tDsYOCVF
During a low-level discussion at a casual meetup, many folks were interested in understanding GPUs more closely.
While CPUs optimize for complex control flow (see those big cores + caches), the GPUs maximize throughput with thousands of simple cores sharing memory. The GPU architecture roadmap is a good starting point for diving deeper.
The FDE strategy is to do things that don't scale - at scale.
The biggest question startups ask me nowadays is whether to build an FDE team. Great to chat with YC's Lightcone Podcast about the early days of Palantir!
https://t.co/sLZQZaxfMl
There is significant unmet demand for developers who understand AI. At the same time, because most universities have not yet adapted their curricula to the new reality of programming jobs being much more productive with AI tools, there is also an uptick in unemployment of recent CS graduates.
When I interview AI engineers — people skilled at building AI applications — I look for people who can:
- Use AI assistance to rapidly engineer software systems
- Use AI building blocks like prompting, RAG, evals, agentic workflows, and machine learning to build applications
- Prototype and iterate rapidly
Someone with these skills can get a massively greater amount done than someone who writes code the way we did in 2022, before the advent of Generative AI. I talk to large businesses every week that would love to hire hundreds or more people with these skills, as well as startups that have great ideas but not enough engineers to build them. As more businesses adopt AI, I expect this talent shortage only to grow! At the same time, recent CS graduates face an increased unemployment rate, though the underemployment rate — of graduates doing work that doesn’t require a degree — is still lower than for most other majors. This is why we hear simultaneously anecdotes of unemployed CS graduates and also of rising salaries for in-demand AI engineers.
When programming evolved from punchcards to keyboard and terminal, employers continued to hire punchcard programmers for a while. But eventually, all developers had to switch to the new way of coding. AI engineering is similarly creating a huge wave of change.
There is a stereotype of “AI Native” fresh college graduates who outperform experienced developers. There is some truth to this. Multiple times, I have hired, for full-stack software engineering, a new grad who really knows AI over an experienced developer who still works 2022-style. But the best developers I know aren’t recent graduates (no offense to the fresh grads!). They are experienced developers who have been on top of changes in AI. The most productive programmers today deeply understand computers, how to architect software, and how to make complex tradeoffs — and who additionally are familiar with cutting-edge AI tools.
Sure, some skills from 2022 are becoming obsolete. For example, a lot of coding syntax that we had to memorize back then is no longer important, since we no longer need to code by hand as much. But even if, say, 30% of CS knowledge is obsolete, the remaining 70% — complemented with modern AI knowledge — is what makes really productive developers. (Even after punch cards became obsolete, a fundamental understanding of programming was very helpful for typing code into a keyboard.)
Without understanding how computers work, you can’t just “vibe code” your way to greatness. Fundamentals are still important, and for those who additionally understand AI, job opportunities are numerous!
[Original text: https://t.co/nqzPC6eUpR ]
Tu Nguyen just published awesome looking Laminar bindings for the WebAwesome (Shoelace.js 3.0) web components library:
> https://t.co/CVoh9DvAUG
> https://t.co/NmkdlGB8N3
You can now easily use even more professionally made web components in #ScalaJS!
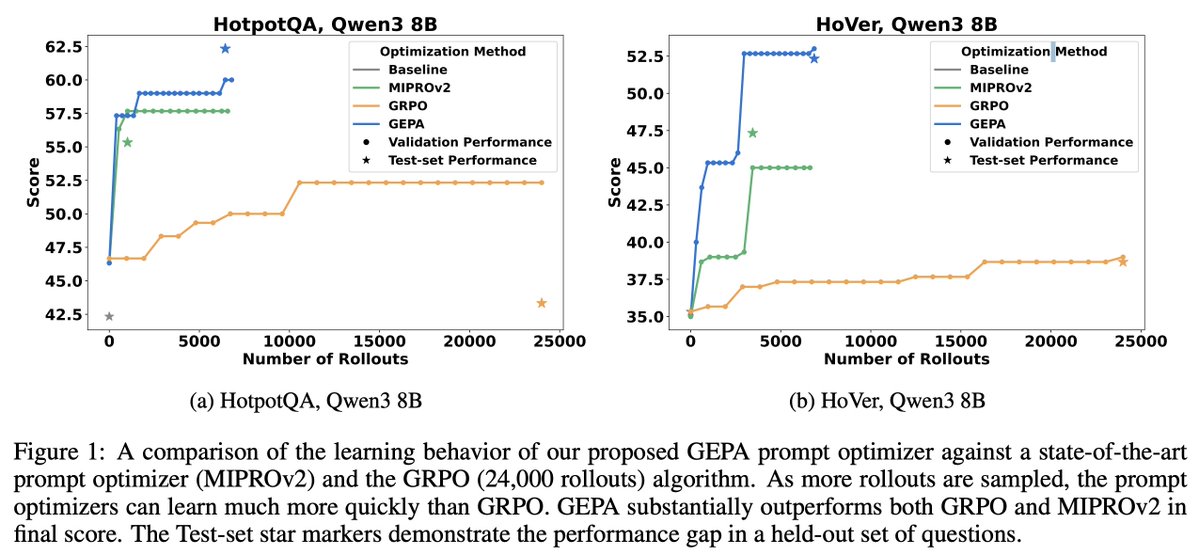
How does prompt optimization compare to RL algos like GRPO?
GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't.
Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵
New paper: Reflective Prompt Evolution Can Outperform GRPO.
It's becoming clear that learning via natural-language reflection (aka prompt optimization) will long be a central learning paradigm for building AI systems.
Great work by @LakshyAAAgrawal and team on GEPA and SIMBA.
Don't use MCP until you read this!
MCP security is completely broken.
This guide helps you understand how tool poisoning attacks occur and how to defend against them...👇
Announcing a new Coursera course: Retrieval Augmented Generation (RAG)
You'll learn to build high performance, production-ready RAG systems in this hands-on, in-depth course created by https://t.co/zpIxRSuky4 and taught by @ZainHasan6, experienced AI and ML engineer, researcher, and educator.
RAG is a critical component today of many LLM-based applications in customer support, internal company Q&A systems, even many of the leading chatbots that use web search to answer your questions. This course teaches you in-depth how to make RAG work well.
LLMs can produce generic or outdated responses, especially when asked specialized questions not covered in its training data. RAG is the most widely used technique for addressing this. It brings in data from new data sources, such as internal documents or recent news, to give the LLM the relevant context to private, recent, or specialized information. This lets it generate more grounded and accurate responses.
In this course, you’ll learn to design and implement every part of a RAG system, from retrievers to vector databases to generation to evals. You’ll learn about the fundamental principles behind RAG and how to optimize it at both the component and whole-system levels.
As AI evolves, RAG is evolving too. New models can handle longer context windows, reason more effectively, and can be parts of complex agentic workflows. One exciting growth area is Agentic RAG, in which an AI agent at runtime (rather than it being hardcoded at development time) autonomously decides what data to retrieve, and when/how to go deeper. Even with this evolution, access to high-quality data at runtime is essential, which is why RAG is a key part of so many applications.
You'll learn via hands-on experiences to:
- Build a RAG system with retrieval and prompt augmentation
- Compare retrieval methods like BM25, semantic search, and Reciprocal Rank Fusion
- Chunk, index, and retrieve documents using a Weaviate vector database and a news dataset
- Develop a chatbot, using open-source LLMs hosted by Together AI, for a fictional store that answers product and FAQ questions
- Use evals to drive improving reliability, and incorporate multi-modal data
RAG is an important foundational technique. Become good at it through this course!
Please sign up here: https://t.co/81DSVlDEOW
One of the best ways to reduce LLM latency is by fusing all computation and communication into a single GPU megakernel. But writing megakernels by hand is extremely hard.
🚀Introducing Mirage Persistent Kernel (MPK), a compiler that automatically transforms LLMs into optimized megakernel, reducing latency by 1.2-6.7x.
🔧Tool: https://t.co/mRJ8sSg7HX
📝Blog: https://t.co/97b0YRSrS6
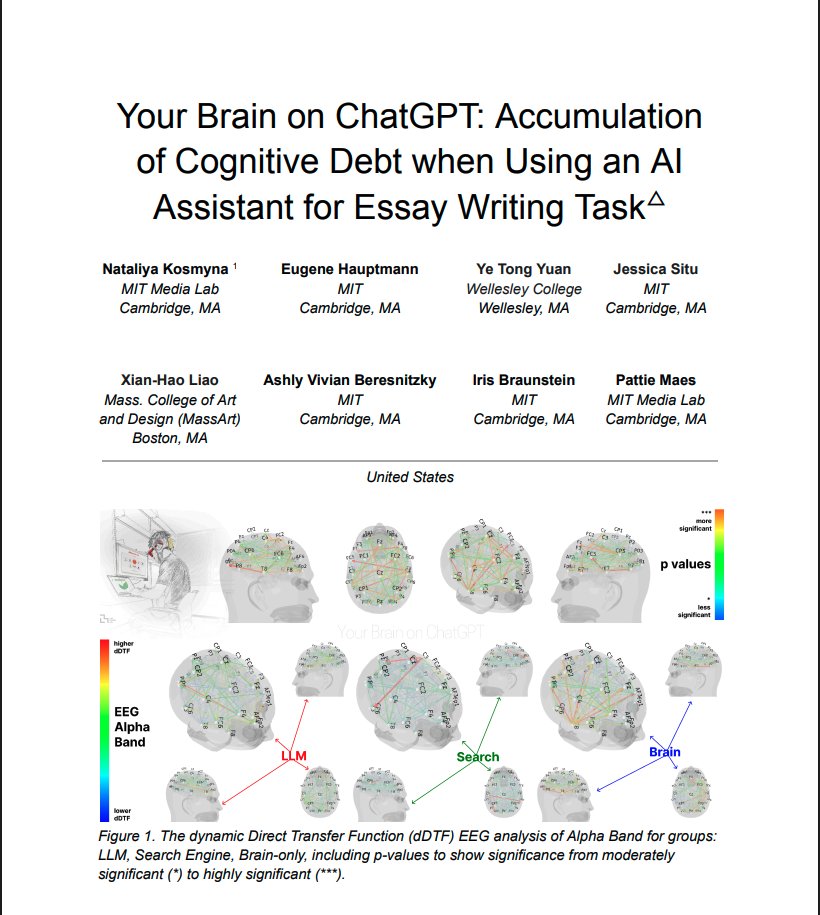
BREAKING: MIT just completed the first brain scan study of ChatGPT users & the results are terrifying.
Turns out, AI isn't making us more productive. It's making us cognitively bankrupt.
Here's what 4 months of data revealed:
(hint: we've been measuring productivity all wrong)




































![AndrewYNg's tweet photo. There is significant unmet demand for developers who understand AI. At the same time, because most universities have not yet adapted their curricula to the new reality of programming jobs being much more productive with AI tools, there is also an uptick in unemployment of recent CS graduates.
When I interview AI engineers — people skilled at building AI applications — I look for people who can:
- Use AI assistance to rapidly engineer software systems
- Use AI building blocks like prompting, RAG, evals, agentic workflows, and machine learning to build applications
- Prototype and iterate rapidly
Someone with these skills can get a massively greater amount done than someone who writes code the way we did in 2022, before the advent of Generative AI. I talk to large businesses every week that would love to hire hundreds or more people with these skills, as well as startups that have great ideas but not enough engineers to build them. As more businesses adopt AI, I expect this talent shortage only to grow! At the same time, recent CS graduates face an increased unemployment rate, though the underemployment rate — of graduates doing work that doesn’t require a degree — is still lower than for most other majors. This is why we hear simultaneously anecdotes of unemployed CS graduates and also of rising salaries for in-demand AI engineers.
When programming evolved from punchcards to keyboard and terminal, employers continued to hire punchcard programmers for a while. But eventually, all developers had to switch to the new way of coding. AI engineering is similarly creating a huge wave of change.
There is a stereotype of “AI Native” fresh college graduates who outperform experienced developers. There is some truth to this. Multiple times, I have hired, for full-stack software engineering, a new grad who really knows AI over an experienced developer who still works 2022-style. But the best developers I know aren’t recent graduates (no offense to the fresh grads!). They are experienced developers who have been on top of changes in AI. The most productive programmers today deeply understand computers, how to architect software, and how to make complex tradeoffs — and who additionally are familiar with cutting-edge AI tools.
Sure, some skills from 2022 are becoming obsolete. For example, a lot of coding syntax that we had to memorize back then is no longer important, since we no longer need to code by hand as much. But even if, say, 30% of CS knowledge is obsolete, the remaining 70% — complemented with modern AI knowledge — is what makes really productive developers. (Even after punch cards became obsolete, a fundamental understanding of programming was very helpful for typing code into a keyboard.)
Without understanding how computers work, you can’t just “vibe code” your way to greatness. Fundamentals are still important, and for those who additionally understand AI, job opportunities are numerous!
[Original text: https://t.co/nqzPC6eUpR ]](https://pbs.twimg.com/media/G0A4amDbAAAXsq7.jpg)