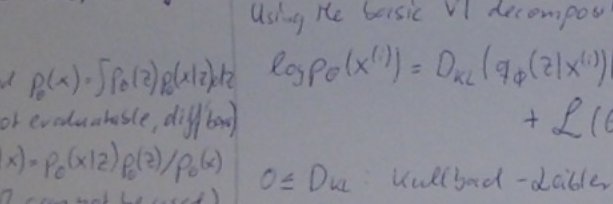A recent study looked at how open-soruce developers use MLOps frameworks.
Surprising: teams rarely use them end-to-end. Instead, they assemble their own custom workflows.
Interesting signal about how ML systems are really built in the wild 🦥
https://t.co/EBJfdlyha4
Claude scans now codebases for vulnerabilities and suggests fixes (currently a limited research preview).
We've applied to participate with MLOX🛡️
Now the question is whether AI is really starting to challenge specialist security vendors.
https://t.co/fbGGYz1pYc
Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
You can now train LLMs in VS Code for free via Colab & Unsloth.
We made a guide showing you how to connect any fine-tuning notebook in VS Code to a Colab runtime.
Train locally or on a free Google Colab GPU.
Guide: https://t.co/ZHJCb0oHQT
GitHub: https://t.co/2kXqhhvLsb
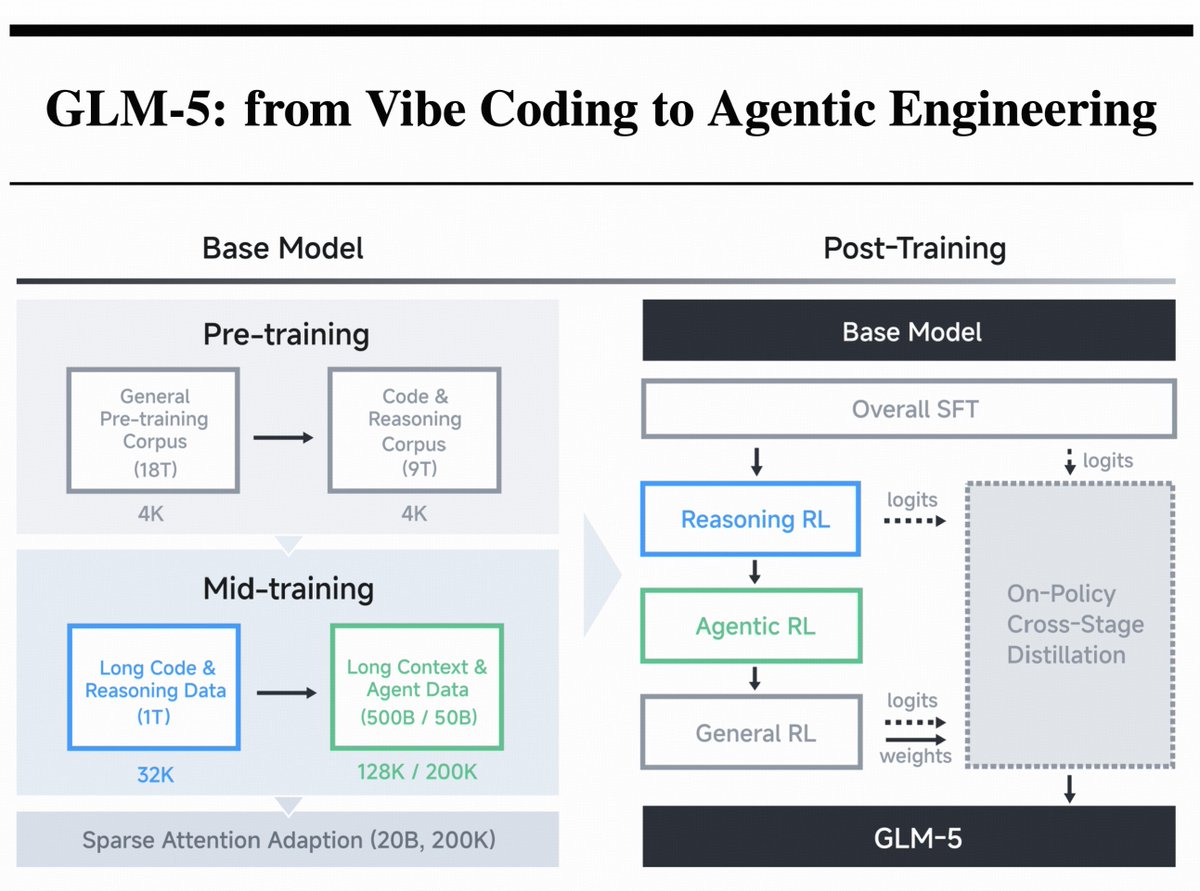
Presenting the GLM-5 Technical Report!
https://t.co/CGjxEISvFK
After the launch of GLM-5, we’re pulling back the curtain on how it was built. Key innovations include:
- DSA Adoption: Significantly reduces training and inference costs while preserving long-context fidelity
- Asynchronous RL Infrastructure: Drastically improves post-training efficiency by decoupling generation from training
- Agent RL Algorithms: Enables the model to learn from complex, long-horizon interactions more effectively
Through these innovations, GLM-5 achieves SOTA performance among open-source models, with particularly strong results in real-world software engineering tasks.
A paper worth paying close attention to.
It presents Lossless Context Management (LCM), which reframes how agents handle long contexts.
It outperforms Claude Code on long-context tasks.
Recursive Language Models give the model full autonomy to write its own memory scripts. LCM takes that power back, handing it to a deterministic engine that compresses old messages into a hierarchical DAG while keeping lossless pointers to every original. Less expressive in theory, far more reliable in practice.
The results:
Their agent (Volt, on Opus 4.6) beats Claude Code at *every* context length from 32K to 1M tokens on the OOLONG benchmark. +29.2 points average improvement versus Claude Code's +24.7. The gap widens at longer contexts.
The implication is one we keep relearning from software engineering history: how you manage what the model sees may matter more than giving the model tools to manage it itself. Every agent framework shipping with "let the model figure it out" memory strategies may be building on the wrong abstraction entirely.
Paper: https://t.co/LtqS7pzmP4
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
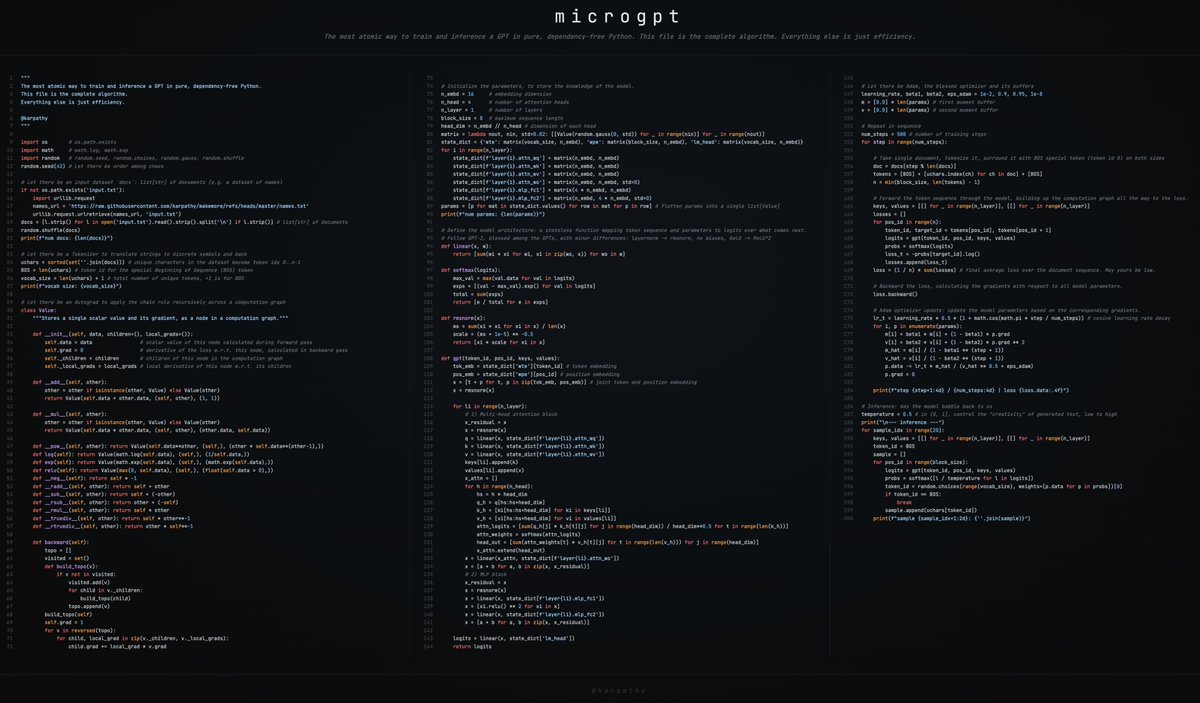
I spent more test time compute and realized that my micrograd can be dramatically simplified even further. You just return local gradients for each op and get backward() to do the multiply (chaining) with global gradient from loss. So each op just expresses the bare fundamentals of what it needs to: the forward computation and the backward gradients for it.
Huge savings from 243 lines of code to just 200 (~18%).
Also, the code now fits even more beautifully to 3 columns and happens to break just right:
Column 1: Dataset, Tokenizer, Autograd
Column 2: GPT model
Column 3: Training, Inference
Ok now surely we are done.
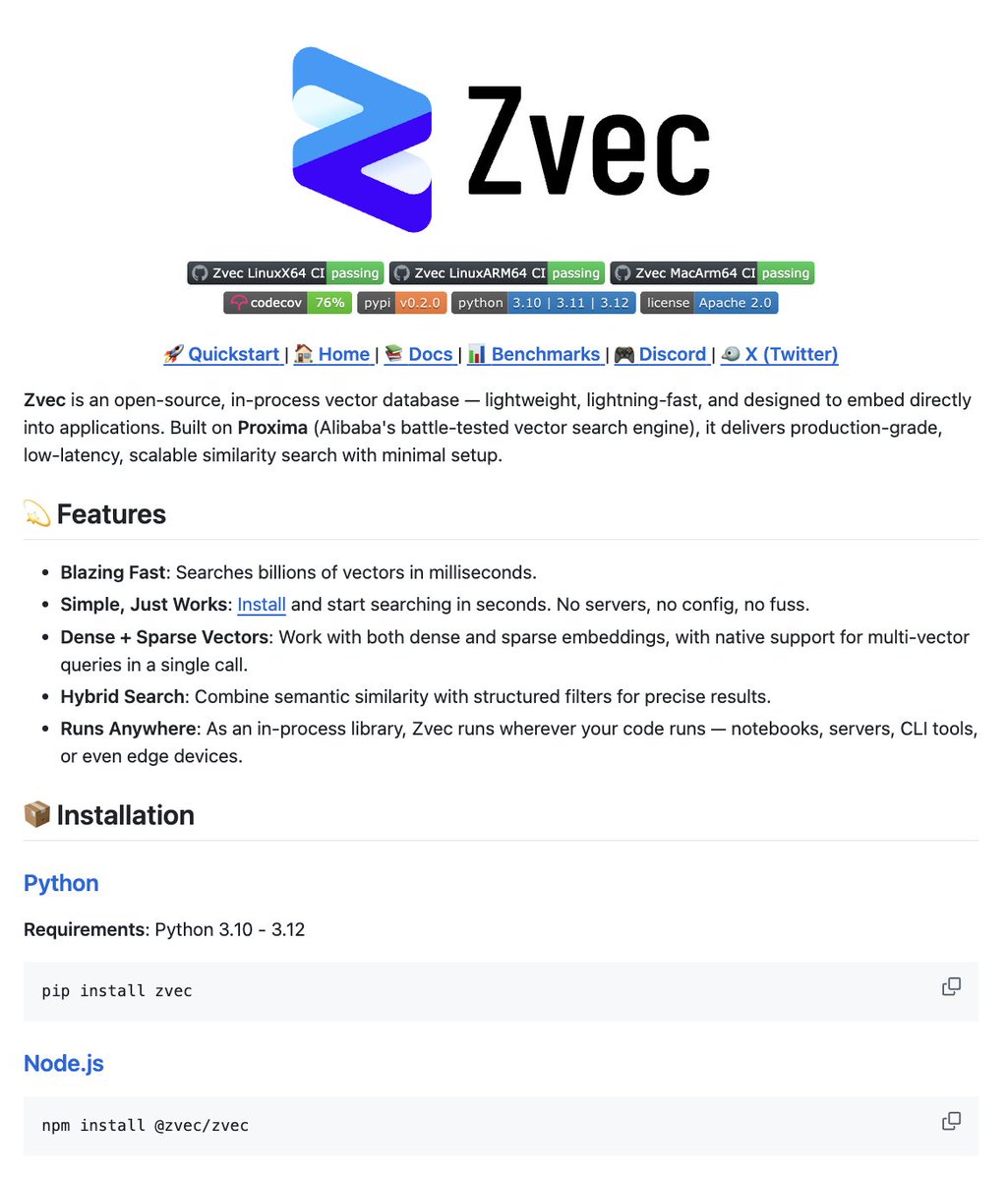
China's Alibaba just opensourced the SQLite of vector databases.
zvec runs as a library inside your app and is built for on-device RAG
no external server. no pinecone. no qdrant instance.
100% opensource.
I'm joining @OpenAI to bring agents to everyone. @OpenClaw is becoming a foundation: open, independent, and just getting started.🦞
https://t.co/XOc7X4jOxq
Qwen3.5 is here 🚀
397B params, just 17B active.
Native multimodal agents for coding, reasoning, GUI + video.
200+ languages. Open weights. Real scale.
The next frontier is open.
🔗 https://t.co/pQQOEDAXBi
Montags-Update 🦥
MLOX now has a plugin system.
Core stays lean.
Extensions can be added modularly.
Fewer forks, more flexibility.
Still early but this feels like the right direction.
#OpenSource#MLOps
If you’re in media, this is worth a watch.
Cloudflare handles ≈20% of global traffic, so when CEO Matthew Prince warns at Cannes that AI bots are reshaping the web, publishers need to adapt or risk being left behind.
NVIDIA just dropped PersonaPlex-7B 🤯
A full-duplex voice model that listens and talks at the same time.
No pauses. No turn-taking. Real conversation.
100% open source. Free.
Voice AI just leveled up.
https://t.co/YfzFQfBzMS
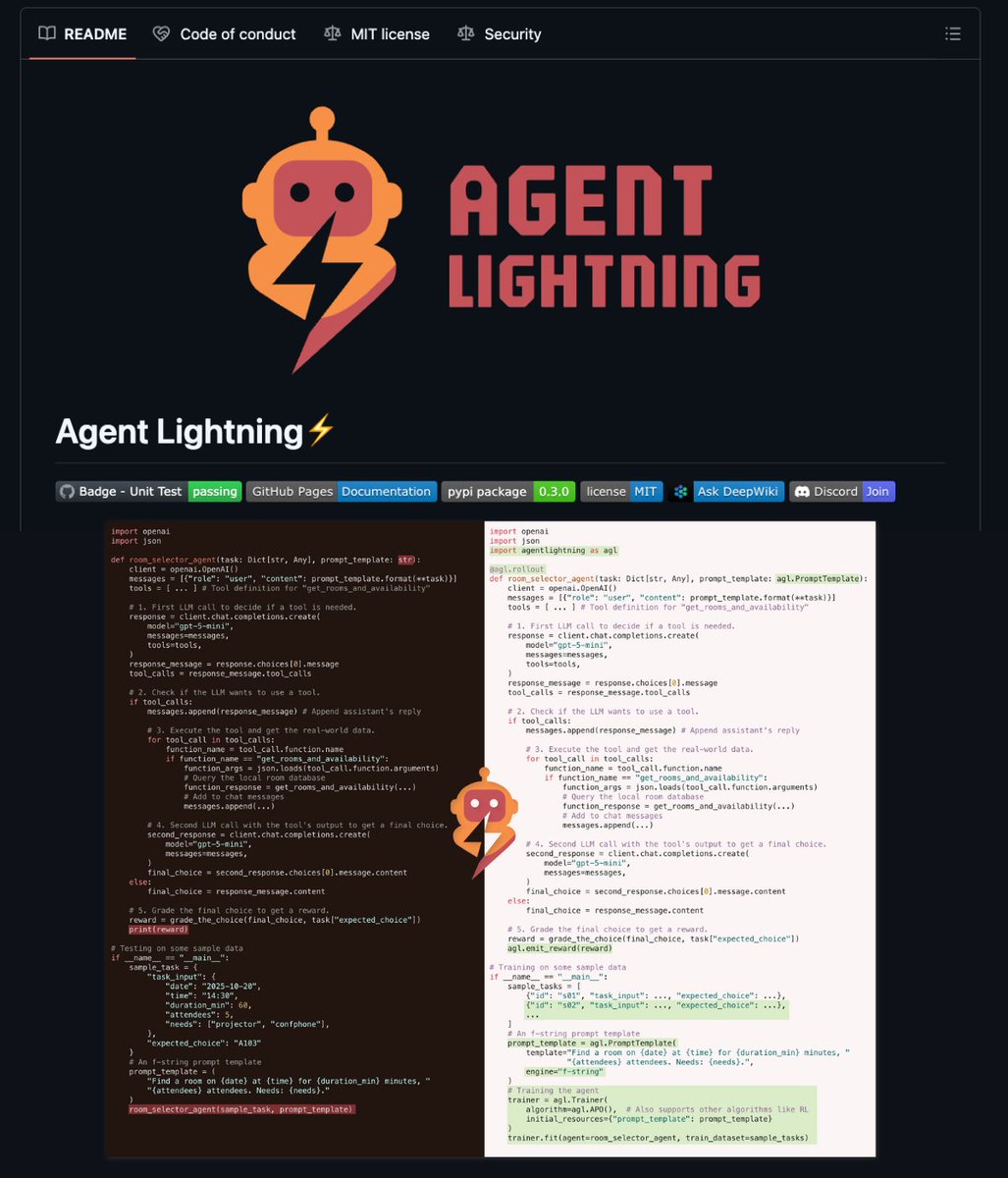
🚨BREAKING: Microsoft just solved the "Agent Loop" problem.
Agent Lightning is an open-source framework that lets agents learn from their own mistakes using Reinforcement Learning.
Your agent fails a task → Agent Lightning analyzes why → Updates the prompt automatically → Next run succeeds.
100% Opensource.