DeepSpeed now supports the Muon Optimizer.
Optimized specifically for internal 2D weights within neural networks, Muon is gaining traction for its significant memory savings and strong convergence metrics during LLM training.
In our latest blog post, the DeepSpeed team shares a deep dive into their integration setup, implementation of hybrid optimizer strategies, and early benchmark results. @PKUWZP
Read the full technical breakdown here 👉 https://t.co/t7JxOqkM6S
People of https://t.co/oUoqqL9hAp. We have a new website. It's a still a bit WIP, but our humongous web team is working on it day and night.
You can now also update pi itself via pi update. Thank @mitsuhiko for the perfect font choice.
10 years ago today, we lost Sir David MacKay FRS. Physicist. Mathematician. Polymath. Gone at 48. I was working on my PhD at Cambridge, and attended some of his last lectures and symposium. He was a reason that attracted me to Cambridge over MIT in 2014.
His textbook, Information Theory, Inference, and Learning Algorithms, was the first ML book I ever read — recommended to me by none other than Geoff Hinton.
He used that same information theory to build Dasher — a text entry system where users steer through a continuous stream of letters flowing toward them, with a probabilistic language model making likely next letters larger and easier to reach, so that any tiny movement — a finger, a gaze — becomes efficient writing. It was the first ML application that truly blew my mind, and sent me deep into a rabbit hole: arithmetic coding, PAQ8 compression, nonparametric models. A journey I partly owe to his PhD student Christian Steinruecken, who also happened to share my love of Japan.
As Chief Scientific Advisor to the UK's Department of Energy & Climate Change, he brought a physicist's clarity to policy. In Sustainable Energy – Without the Hot Air, he ran the numbers on our entire energy diet — and made me confront an uncomfortable truth. One of the biggest single factors? Beef — roughly 1,000 days of cow-time per steak. Hard to argue with the data. Hard to act on it when you were born and raised in Japan. I'm still working on that one, David.
At his final symposium in Cambridge — just a few weeks before his passing — the room told the full story. Geoff Hinton and his Caltech PhD advisor John Hopfield — both Nobel Prize winners in Physics 2024 — gave tributes. Environment policy advisers spoke. Dasher users sent video messages of thanks from around the world — people who found their voice because of him. It was extraordinary to witness, in one room, just how many minds and lives a single person had touched.
The story of how Hinton first noticed him: at a conference workshop poster session, among everyone who stopped by, it was the young MacKay who asked the sharpest, most penetrating question. Hinton remembered it. That's how it begins.
I've always liked physicists who cross into ML — they bring a groundedness, a refusal to hide behind formalism without meaning. David MacKay and Max Welling are the role models I point to. Not just for the mathematics they built, but for how they carried it: with humility, curiosity, and a stubborn insistence on reaching beyond academia.
He seemed to know his time was limited, and gave everything anyway. His legacy stays.
AI Engineering Buildcamp is project-driven.
You learn AI engineering by building.
15 projects you can build during the course 👇🏼
(You get lifetime access to the course if you sign up)
In a world where everyone can build websites, apps and features easily (thank you Cursor, Lovable, Claude and the likes), it will take more for you and your company to differentiate themselves (which is in my opinion the basis for success).
That's why we're seeing more and more people and companies starting to train, optimize and run their own models (rather than outsource this to third parties).
This is the future we want to enable with Hugging Face: empower millions of people to build AI themselves, not just be API users.
Cool new project in this vein from @mishig25: auto-research built on top of @huggingface so that your agents find and push their intermediary checkpoints, datasets, learn from papers and collaborate on the hub: https://t.co/YWCzp5ZIfC
Let's make all AI builders rather than AI users!
The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (https://t.co/nDVjmNhATM).
We would greatly appreciate your attention and help in sharing it.
If you're using Claude Code for research: stop making it read directly from PDFs
We've introduced a SKILL.md that fetches structured, AI-friendly paper overviews from alphaXiv 👀
@mitsuhiko If I am not mistaken, it appears to be Arabic written from left to right!! 😄 (my native language is Persian, and both languages are written from right to left.)
Find me a conference with a better line-up, I dare you.
There are still some tickets available, buy now.
https://t.co/2xJAMFoNcF
Or, even better, if you're a serious open source developer in your free time, email me and we'll give you a free ticket. samuel at https://t.co/3z9bgyCxyj.
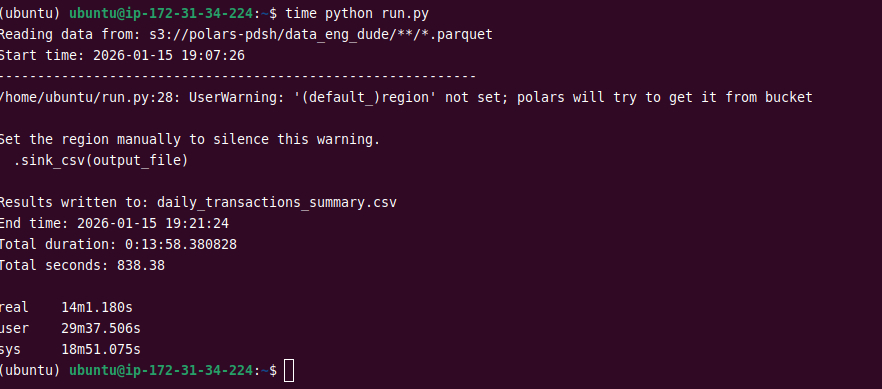
So there was quite a sensational rant post titling "DuckDB beats Polars for 1TB of data" and the video "Polars Got Destroyed by DuckDB in this 1TB Test" that was shared a lot.
There was no code shared for Polars and upon request, we were ignored. These posts were conveniently shared in posts and newsletters because they fit a narrative.
In any case, I went through the effort to reproduce the dataset and run the exact benchmark.
The post mentioned 64GB RAM, so I ran on a 5a.8xlarge (32vCPU / 64GB RAM).
Polars did not go OOM, but finished the query in 14 minutes never exceeding 14GB RAM usage.
On the same machine DuckDB also took 14 minutes. Both tools hit the bandwidth limit: 1 TB / 10 Gbps = 13.3 min, but that makes less of a title 😉.
The whole benchmark was just hard to reproduce, the 1TB part of it made it unwieldy, but didn't matter. It could have done with a 100GB benchmark as the cardinality of the groups was just ~1800.
Here is the Polars query: https://t.co/62oLSctcSd
So I guess... Code or it didn't happen.
The SCEDC hosts one of the most comprehensive and accessible earthquake datasets in the world! We've packed it with features from waveforms to focal mechanisms to metadata-rich event catalogs and more!
We’ve even got tutorials to help you get started:
https://t.co/5jUD003Zg7
#Seismology #Earthquake #SCEDC #SCSN #Data
"Qseek: A data-driven Framework for Automated Earthquake Detection, Localization and Characterization" —
By @seismolicious
Read it on @ResearchGate: https://t.co/6hcPC4LiNz