Around 18 months ago, I noticed a critical mass of excitement happening around #DuckDB. A number of folks whose opinions I value and trust were saying some very bullish things about its applications for data engineering and data science, and so I decided it was time to jump down the rabbit hole. 🦆🐇✨
Turns out this rabbit hole went a little deeper than I expected. 18 months later, I'm happy to say that 'Getting Started with DuckDB: A practical guide for accelerating your data science, data analytics, and data engineering workflows', by @SimonAubury and myself, and published by @PacktPublishing, is now available! 🎉
Whether you’re a seasoned data practitioner or new to working with analytical data, this book will help you quickly get across where DuckDB sits in the data ecosystem and understand how you can apply its powerful and versatile analytical capabilities in your workflows and projects.
The book is available in both physical and e-book forms: https://t.co/jet4xtOyFk
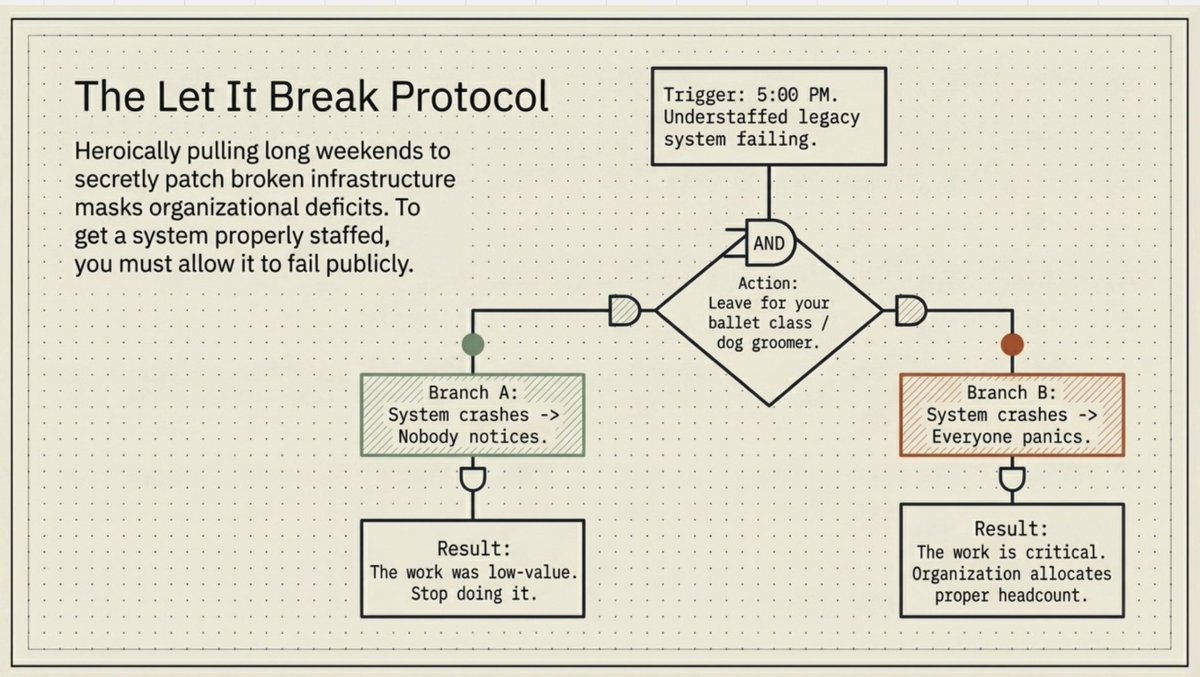
Google has an internal "let it break" essay about a hero engineer whose hard work ends up being a net negative (by masking the underlying issues). My manager sent me that essay when I was trying too hard to get the collective TensorFlow unit test suite green.
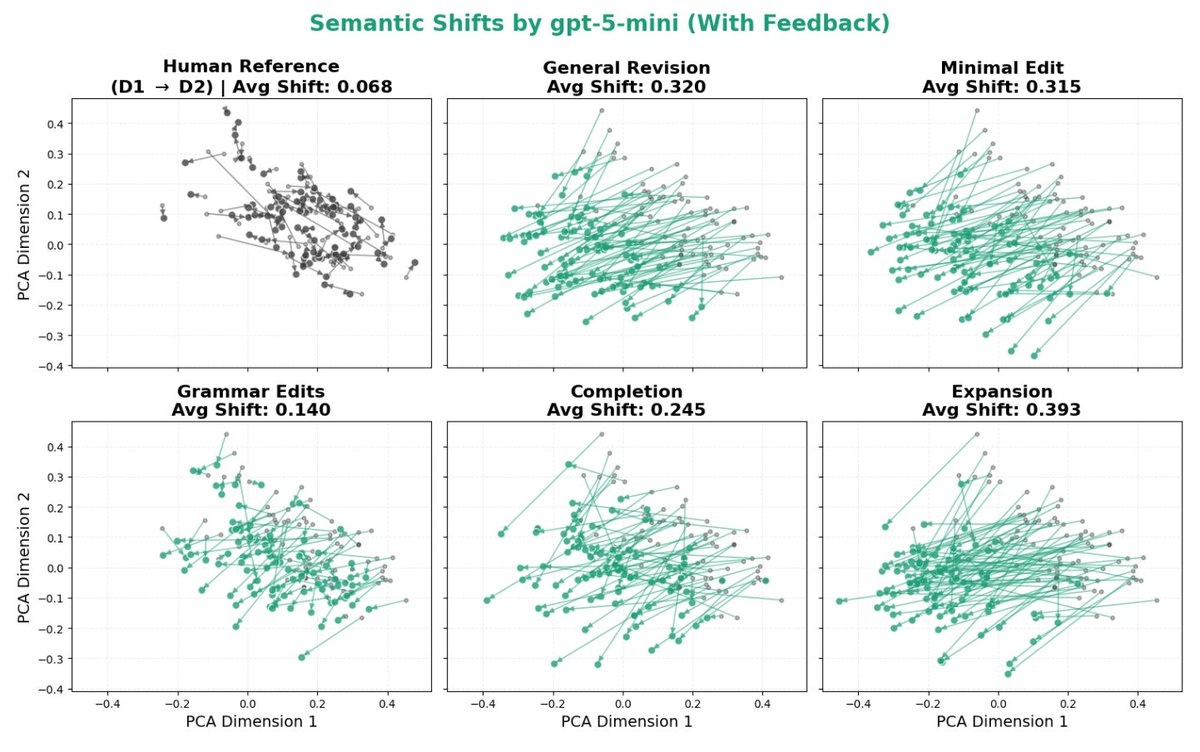
The paper I’ve been most obsessed with lately is finally out: https://t.co/KgdWKknCJK! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
We’re excited to release TorchLean which is the first fully verified neural network framework in Lean. The Lean community has largely focused on pure mathematics. TorchLean expands this frontier toward verified neural network software and scientific computing. With the recent release of CSlib, we see this as another step toward a fully verified ML stack.
We support features:
1. Executable IEEE-754 floating-point semantics (and extensible alternative FP models) verified tensor abstractions with precise shape/indexing semantics
2. Formally verified autograd system for differentiation of NN programs Proof-checked certification / verification algorithms like CROWN (robustness, bounds, etc.)
3. PyTorch-inspired modeling API with eager-style development + export/lowering to a shared IR for execution and verification
Project page: https://t.co/YHpqhRbMQe
Paper: [2602.22631] TorchLean: Formalizing Neural Networks in Lean
Work done @Robertljg, Jennifer Cruden, Xiangru Zhong, @huan_zhang12 and @AnimaAnandkumar.
#MachineLearning #ScientificComputing #Lean
Short musings on "cognitive debt" - I'm seeing this in my own work, where excessive unreviewed AI-generated code leads me to lose a firm mental model of what I've built, which then makes it harder to confidently make future decisions https://t.co/KUqQXDVNiS
Angine de Poitrine
色物かと思いきや…出だし12秒辺りのスネア連打の柔らかさでおっ!っとなり、次のクロマチックのベースも良く、1分7秒辺りからアウトフレーズ弾き出したと思いきやそっちをループで残すという荒技。さらにそこから倍テン…発想が見事。ぜひ聴いて欲しい。
https://t.co/HK6Xg8jp0M
Thomas Watson has a new computational complexity textbook about to be published by Cambridge University Press. There's a free version online for personal use.
https://t.co/jHU7Uuy8G2
My Melbourne Train & Tram map, now in its 30th year online, has been updated to show the new train line colourings and routings for tomorrow's "Big Switch".
See it online now at https://t.co/IGNSujeWqi
or download it as a high resolution image file from
https://t.co/sLVcDcJ82p
Some of the biggest companies in the world use Django, but the project's budget is comparable to a single bay-area engineer's salary.
If your company uses Django, please ask them to donate! It's a great way to say thanks, and really helps keep the framework going.
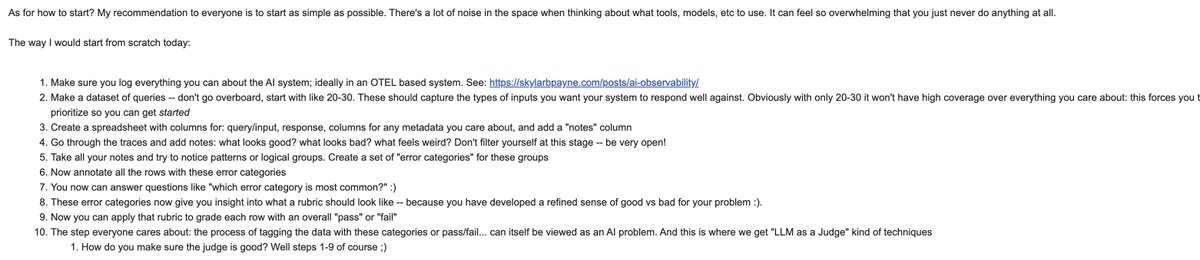
"My biggest problem with evals? I have no idea where to start"
Stop feeling overwhelmed with all the tools, models, etc. Take a deep breath. Start simple, iterate quickly.
you think the eval wars of sept '25 are something?
wait til i chat with @HamelHusain wrt 10 THINGS HE HATES ABOUT EVALS
register for free below (If you can’t make it, register and we’ll share the recording after 🍿)
https://t.co/odn63k3N0M
thx @skylar_b_payne for the poster
I'd recommend this course for anyone working on operational systems where LLM output may play a load-bearing role, even if you're not of the engineering persuasion, but are up for getting your hands dirty with some code.
https://t.co/WOSS8eoCZu
Assessing LLM output quality requires managing vast input/output spaces and acute sensitivity to minor prompt changes, but many teams are still running on largely vibe-based evals, incurring considerable risk and preventing systematic product improvement.
We can do better! [1/5]
The course validated my intuitions that these foundations apply just as much to generative AI applications and has given me a road-tested pragmatic framework for applying them to the weird world of LLMs and AI engineering.
Our first DocETL paper has been accepted to VLDB 2025! DocETL is a system we’ve been building at Berkeley for reliable LLM-powered data pipelines, where the optimizer logically rewrites pipelines because even experts cannot author one that is accurate enough to begin with.
I'll be presenting it at VLDB in a couple weeks. And because database papers rarely get traction on social media, I always like to give the backstory — in hopes that the story is fun or resonates more broadly. 😃
































![AnimaAnandkumar's tweet photo. We’re excited to release TorchLean which is the first fully verified neural network framework in Lean. The Lean community has largely focused on pure mathematics. TorchLean expands this frontier toward verified neural network software and scientific computing. With the recent release of CSlib, we see this as another step toward a fully verified ML stack.
We support features:
1. Executable IEEE-754 floating-point semantics (and extensible alternative FP models) verified tensor abstractions with precise shape/indexing semantics
2. Formally verified autograd system for differentiation of NN programs Proof-checked certification / verification algorithms like CROWN (robustness, bounds, etc.)
3. PyTorch-inspired modeling API with eager-style development + export/lowering to a shared IR for execution and verification
Project page: https://t.co/YHpqhRbMQe
Paper: [2602.22631] TorchLean: Formalizing Neural Networks in Lean
Work done @Robertljg, Jennifer Cruden, Xiangru Zhong, @huan_zhang12 and @AnimaAnandkumar.
#MachineLearning #ScientificComputing #Lean](https://pbs.twimg.com/media/HCSTAlwaoAAe_6n.png)