ML engineer at Apple. PhD in Neural Machine Translation. Background in ML, data science and SW engineering. Chinese lang enthusiast. Life-long learner. 学无止境
La plataforma Langtern empra la IA per ajudar els professors a crear exercicis a partir de textos i vídeos en línia, que classifica per nivell de dificultat
https://t.co/HEj7lWfqiZ
@erogol I was planning to get familiar with ggml at some point, but for now I have been just lurking and tracking its progress. There is already a TTS for ggml: https://t.co/J8n5Az2FMk . Maybe parts of it can be useful for a future "xtts.cpp"
GPT-4 and GPT-3.5 Turbo models in the API now support calling your custom functions, allowing the model to use tools you design for it. Also — reduced pricing & new model versions (including 16k context for 3.5 Turbo): https://t.co/dalfgEQ9k2
@nataliasirera The PyDataBCN 2023 has been incredible!
We are grateful for all the organizers, volunteers, speakers, sponsors and assistants.
See you at our next event!
We are pleased to share a multilingual extension to holistic bias dataset which allows to unveil demographic biases for languages at scale, see our first findings: https://t.co/Az8rYZdAaQ
@gdb • Longer context
• Random seed parameter
• Tiktoken in JS/wasm to count tokens correctly (https://t.co/yhAObbmKZQ)
• Models tailored to specific languages, to use fewer tokens to represent the same text, e.g. for Chinese chars
New version of Langtern with improved flashcards!
• Auto-advance mode
• Can go back to the previous cards
• In Chinese, flashcards can play the word pronunciation
• Pronunciation played automatically in auto-advance mode
Great to review vocabulary while doing something else!
@ramsri_goutham@OpenAI To count tokens, I was previously relying on JS package gpt-3-encoder, recommended by OpenAI, which matches the tokenizer web tool. After switching to tiktoken, my estimation and the actually consumed tokens matched perfectly.
@gdb: is in @OpenAI 's plans to mitigate this issue? (e.g. offering models that are trained on vocabulary that represents other scripts more efficiently). My case is with simplified Chinese, which has approx num tokens = 2 x num chars
Most people don't understand @OpenAI GPT-3's tokenization and how expensive/inefficient it is to build a GPT-3 app in non-English!
English: John - 1 token
Telugu: స్తి - 12 tokens 🤯
Byte pair encoding divides a character like స్తి further!
స్తి (12 tokens)= స్త + ి (8+4)
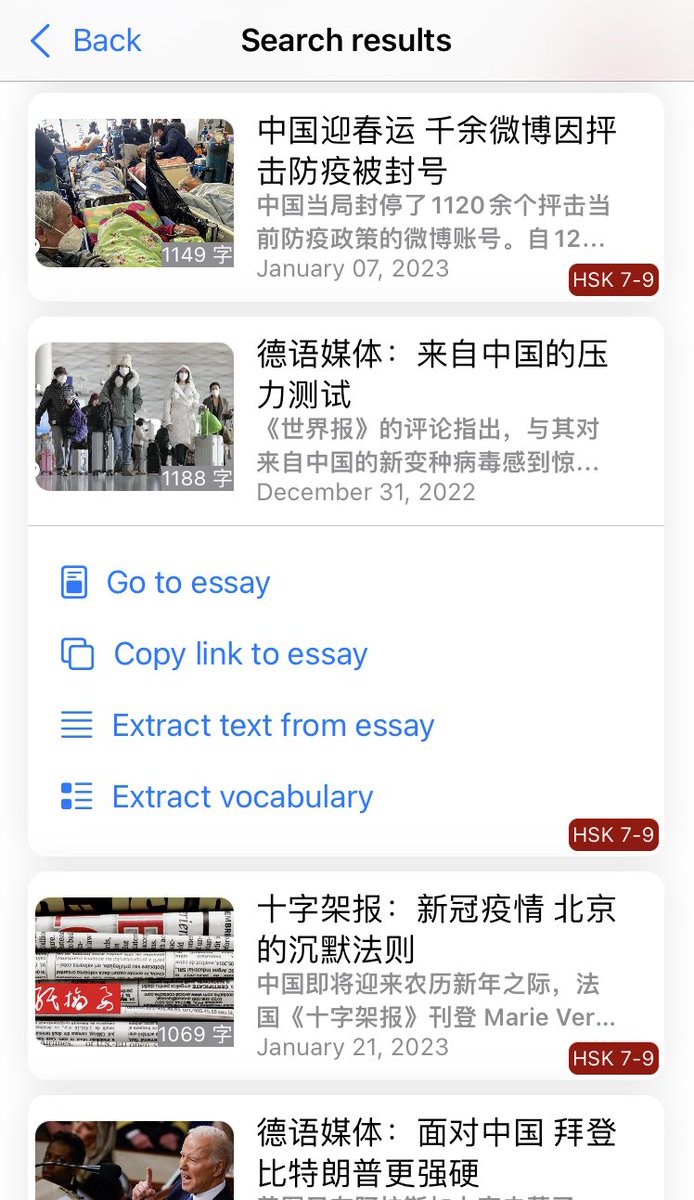
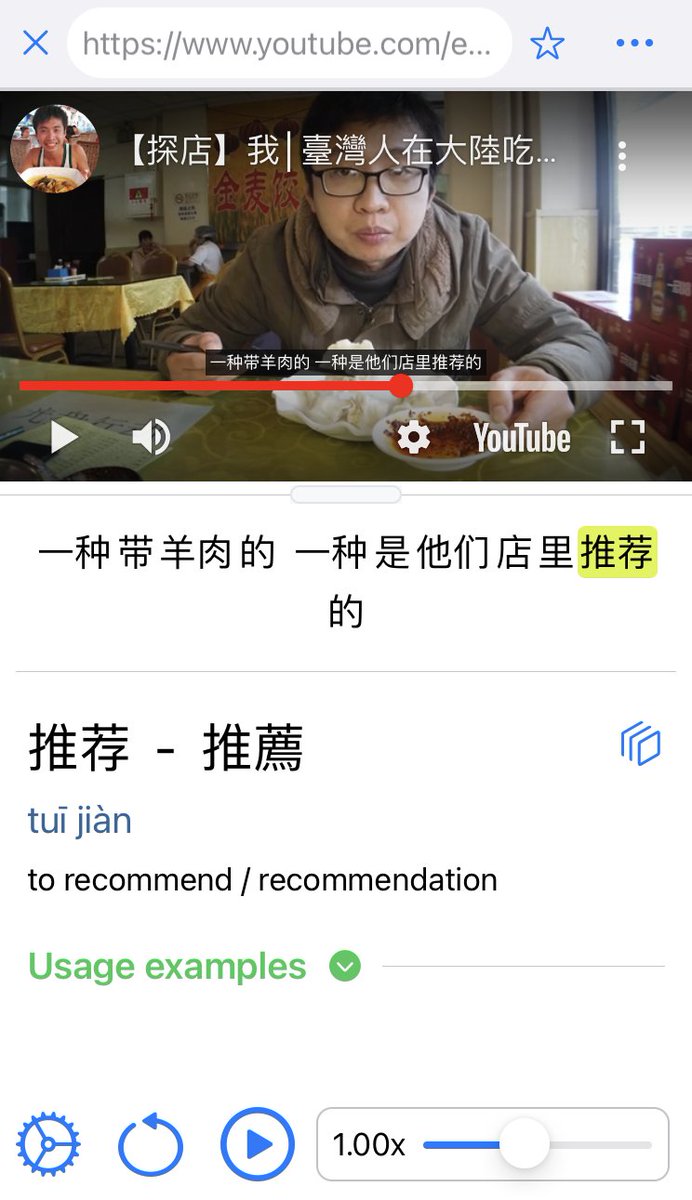
And the new main feature: the online content search engine, where you can search videos and essays by keywords/content but also by HSK level and duration/length! Check it out! 4/6
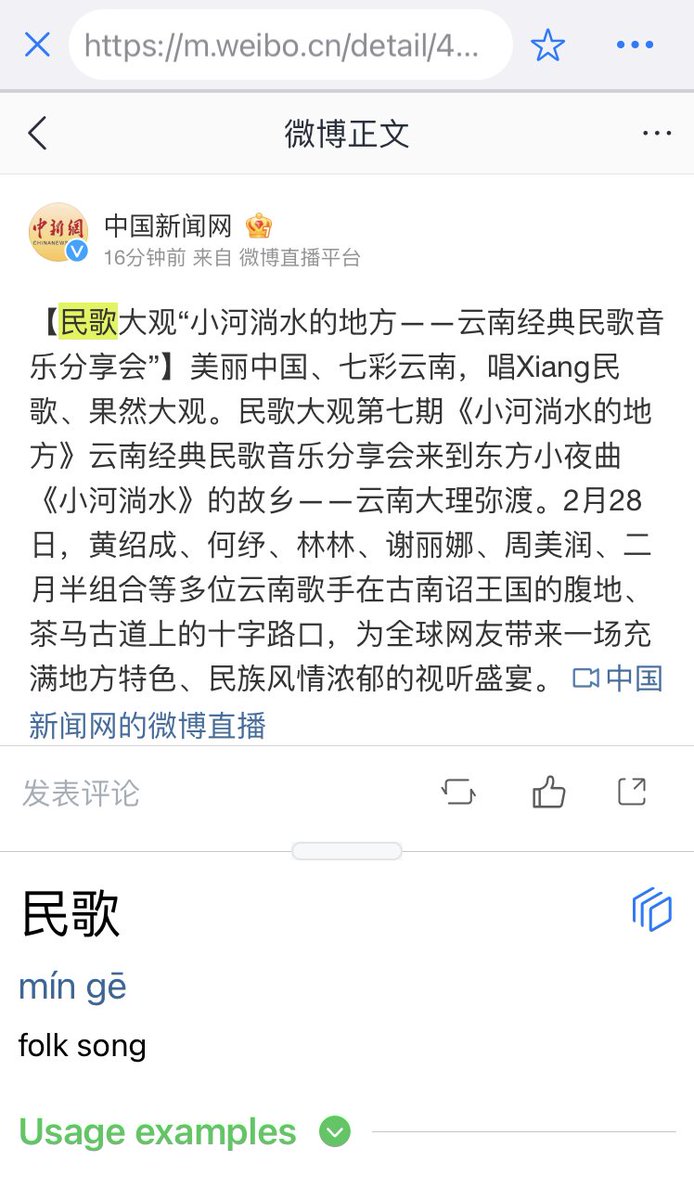
In the Online Content, we have also added social media accounts in Chinese from Twitter and Weibo, web novels, short stories and podcasts with transcription. 3/6
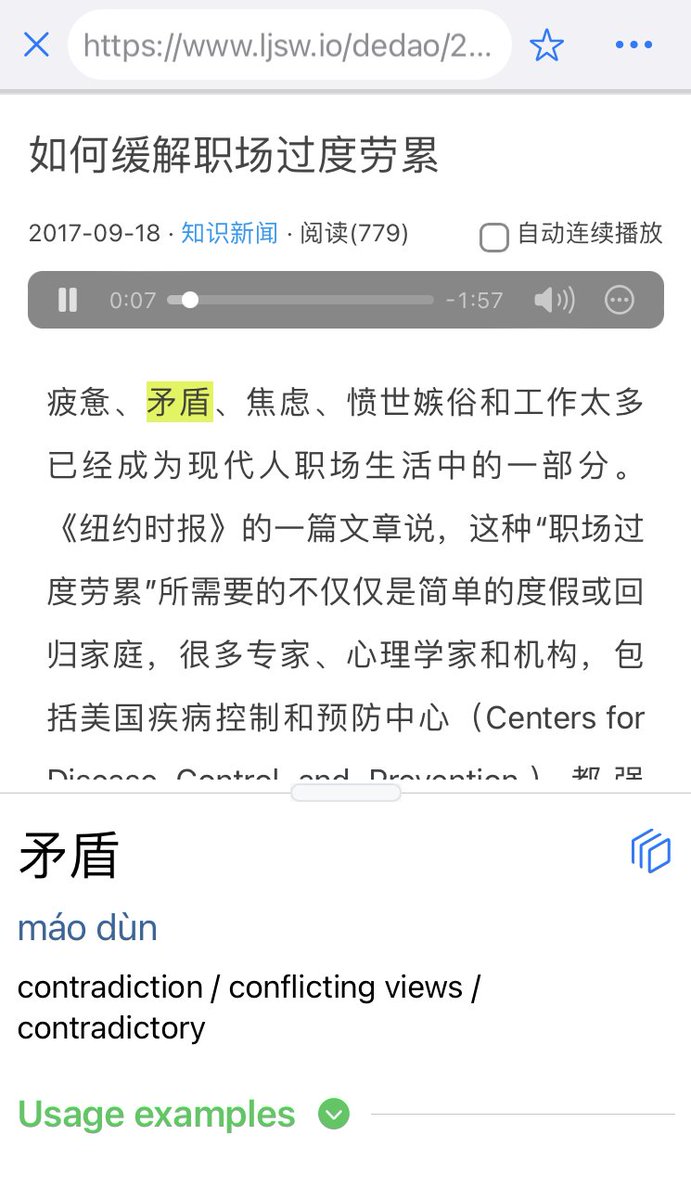
The Online Content section now has more videos in Chinese from Youtube and now also from Bilibili, organized by category and channel. With an improved popup dictionary for captions! 2/6