gpt-oss is out!
we made an open model that performs at the level of o4-mini and runs on a high-end laptop (WTF!!)
(and a smaller one that runs on a phone).
super proud of the team; big triumph of technology.
Congrats @elonmusk@xAI@X! Excited for @JuniperNetworks to be a part of the Memphis Supercluster team and to bring our networking solutions to this innovative work.
Today we’re releasing Code Llama 70B: a new, more performant version of our LLM for code generation — available under the same license as previous Code Llama models.
Download the models ➡️ https://t.co/GApdj5PW83
• CodeLlama-70B
• CodeLlama-70B-Python
• CodeLlama-70B-Instruct
🚨 Challaghatta to Whitefield = 43 km
Ola Cab - ₹1000
Ola Auto - ₹600
BMTC Bus - ₹70
Metro - ₹60 (just 60-70 min journey)
Bengaluru to get better in just 2 years after the opening of upcoming metros. #Karnataka
Historic: 🌖🇮🇳
India becomes the first ever country to successfully land a space probe near the lunar South Pole and the fourth country to soft-land the probe on the lunar surface.
The LM successfully touched down on a flat plain near the south pole of the moon at around 6:02 pm IST (12:32 pm UTC) on 23 August 2023, making India the first country in history to achieve a soft landing on this region of the moon. The LM will deploy its ramp and release the RM soon which will begin its exploration of the lunar terrain.
The mission’s main objective is to explore the south polar region of the moon, which is believed to contain water ice and other resources that could be useful for future human settlements. The mission also aims to conduct various scientific experiments on the lunar surface using its instruments. After orbiting the moon for about a month, the LM separated from the orbiter on 23 August 2023 and began its descent towards the lunar surface. The LM performed a series of automatic maneuvers to reduce its speed and align itself vertically to the landing site.
The LM and the RM communicated with each other and with the orbiter, which relayed their data and images to the ground station in India. The mission’s scientists and engineers celebrated this remarkable feat, which was also witnessed by millions of people around the world through live telecast and streaming.
A proud moment for @isro, India, and all of humanity!
You'll soon see lots of "Llama just dethroned ChatGPT" or "OpenAI is so done" posts on Twitter. Before your timeline gets flooded, I'll share my notes:
▸ Llama-2 likely costs $20M+ to train. Meta has done an incredible service to the community by releasing the model with a commercially-friendly license. AI researchers from big companies were wary of Llama-1 due to licensing issues, but now I think many of them will jump on the ship and contribute their firepower.
▸ Meta's team did a human study on 4K prompts to evaluate Llama-2's helpfulness. They use "win rate" as a metric to compare models, in similar spirit as the Vicuna benchmark. 70B model roughly ties with GPT-3.5-0301, and performs noticeably stronger than Falcon, MPT, and Vicuna.
I trust these real human ratings more than academic benchmarks, because they typically capture the "in-the-wild vibe" better.
▸ Llama-2 is NOT yet at GPT-3.5 level, mainly because of its weak coding abilities. On "HumanEval" (standard coding benchmark), it isn't nearly as good as StarCoder or many other models specifically designed for coding. That being said, I have little doubt that Llama-2 will improve significantly thanks to its open weights.
▸ Meta's team goes above and beyond on AI safety issues. In fact, almost half of the paper is talking about safety guardrails, red-teaming, and evaluations. A round of applause for such responsible efforts!
In prior works, there's a thorny tradeoff between helpfulness and safety. Meta mitigates this by training 2 separate reward models. They aren't open-source yet, but would be extremely valuable to the community.
▸ I think Llama-2 will dramatically boost multimodal AI and robotics research. These fields need more than just blackbox access to an API.
So far, we have to convert the complex sensory signals (video, audio, 3D perception) to text description and then feed to an LLM, which is awkward and leads to huge information loss. It'd be much more effective to graft sensory modules directly on a strong LLM backbone.
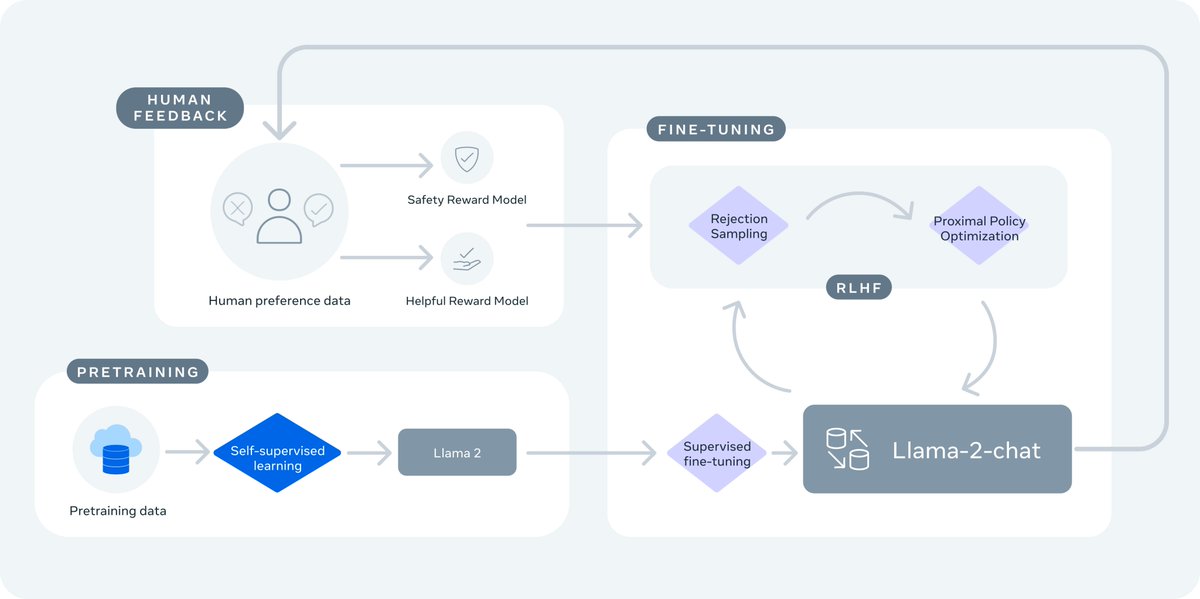
▸ The whitepaper itself is a masterpiece. Unlike GPT-4's paper that shared very little info, Llama-2 spelled out the entire recipe, including model details, training stages, hardware, data pipeline, and annotation process. For example, there's a systematic analysis on the effect of RLHF with nice visualizations.
Quote sec 5.1: "We posit that the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHF."
Congrats to the team again 🥂! Today is another delightful day in OSS AI.
This is huge: Llama-v2 is open source, with a license that authorizes commercial use!
This is going to change the landscape of the LLM market.
Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face and other providers
Pretrained and fine-tuned models are available with 7B, 13B and 70B parameters.
Llama-2 website: https://t.co/PKrrXgHdem
Llama-2 paper: https://t.co/aINNrXNhMb
A number of personalities from industry and academia have endorsed our open source approach: https://t.co/N7HwgW9Suh
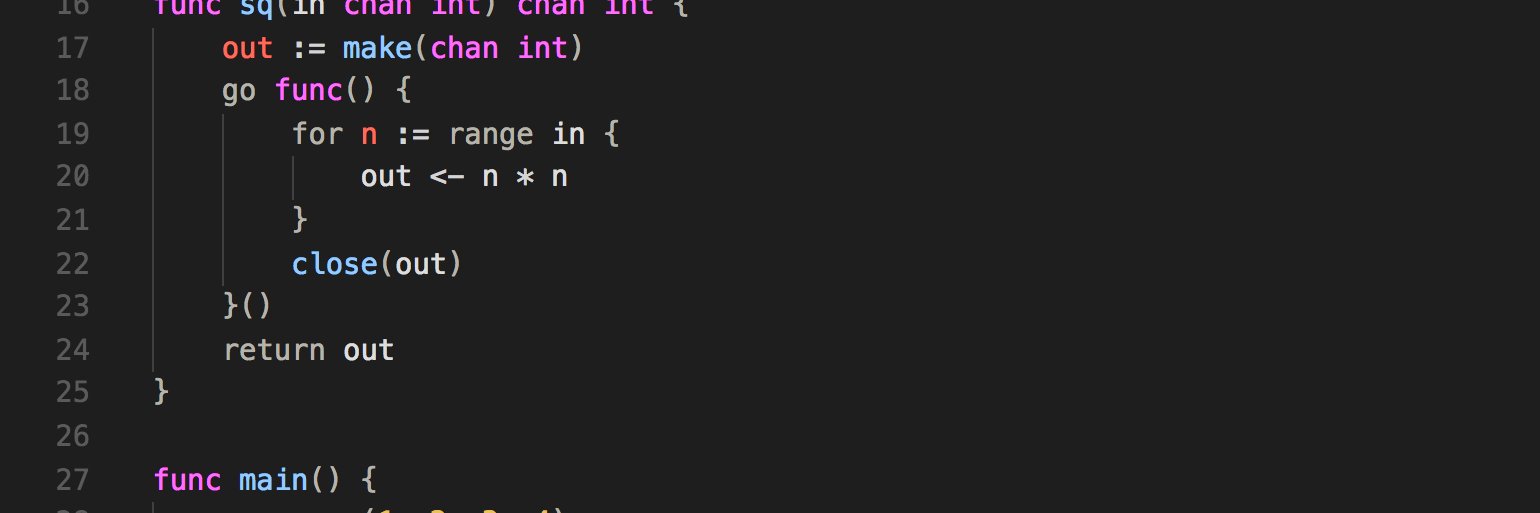
- Each value has a variable known as the owner
- Only one ower at a time
- When the owner goes out of scope, the value will be dropped
No malloc/free & No GC. That's Rust for you. Sweet.
#rustlang
Happy 104th Birthday to one of the most miraculous personalities of scientific history, Prof. Richard Feynman.
1965 Nobel prize winner for his works on QED (along with J. Schwinger and Tomonaga), Dr. Feynman was a remarkably amazing educator and a great physicist.