Me flipa la disertación que hace @JavierCane de @CodelyTV sobre subagentes. Seguid así porque aportáis mucho valor antes tanto hype https://t.co/nPo0IreY6K
Me llegas a decir hace 4 años que iba a dejar de usar StackOverflow y te hubiese dicho que eso es imposible.
Me llegas a decir hace 2 años que iba a dejar de utilizar IntelliJ y me hubiese reído del chiste que me estabas contando.
Me llegas a decir hace 1 año y medio que iba a dejar de usar Copilot y no me lo hubiera creído.
Pero estamos en una época donde las herramientas que teníamos más asentadas están dejando de serlas.
¡Y una de ellas podría ser GitHub!
Hemos publicado un post en el blog comentando el por qué. https://t.co/IbrBBzHfLS
Ever wondered how systems like Redis Cluster, Cassandra, and CDNs add or remove servers without moving all the data?
The answer is Consistent Hashing..
Instead of redistributing every key when a node changes, it only remaps a small subset of data.
✅ Minimizes rebalancing
✅ Reduces downtime during scaling
✅ Improves load distribution
✅ Enables seamless horizontal scaling
✅ Powers many modern distributed systems
A simple rule to remember:
❌ Traditional hashing
→ Add 1 server
→ Almost all keys move
✅ Consistent hashing
→ Add 1 server
→ Only a small fraction of keys move
It’s one of the core ideas behind building scalable, fault-tolerant architectures.
Have you used consistent hashing in production, or only encountered it in system design interviews?
Most developers know these terms…
But many don't know when to use each one.
🍪 Cookies → Small data sent with every HTTP
request
🗂️ Session → User state stored securely on the
server
💾 LocalStorage → Persistent client-side storage
⚡ SessionStorage → Temporary storage for a single browser tab
Rule of thumb:
🔐 Login session → Session or secure HttpOnly cookie
🎨 Theme preference → LocalStorage
📝 Multi-step form → SessionStorage
🍪 Remember user preferences → Cookies
One wrong storage choice can create unnecessary security risks.
Save this cheat sheet for your next interview or project. 👇
Sharding ≠ Partitioning ≠ Replication
I still see these three concepts confused in system design interviews and real-world discussions.
Here's the simplest way to remember them:
🔹 Sharding → Split data across multiple databases/servers to scale horizontally.
🔹 Partitioning → Split data within the same database to improve performance and manageability.
🔹 Replication → Copy the same data to multiple servers for high availability and faster reads.
One-line memory trick 👇
✅ Sharding = Split Across
✅ Partitioning = Split Within
✅ Replication = Copy & Protect
They solve different problems but large-scale systems often use all three together.
Saved this handwritten cheat sheet for quick revision. Hope it helps someone preparing for interviews or designing scalable systems.
This tutorial shows how to deploy OpenClaw on Kubernetes with a Helm chart and ArgoCD, using persistent storage, config modes, secrets handling, and network policies to reduce the blast radius of an AI agent
➜ https://t.co/W37befVmmR
DBeaver lleva 15 años siendo el cliente de base de datos por defecto.
Es potente. Y también es un dinosaurio de Java que tarda 20 segundos en arrancar.
Alguien lo construyó desde cero en Rust y añadió lo que DBeaver nunca tuvo.
Se llama Tabularis. 2.5k estrellas. Apache-2.0. Activo hace 17 horas.
El detalle que más me ha flipado:
Lo construyó una sola persona (@debba_92 ) como experimento de desarrollo asistido por IA.
Quería ver hasta dónde podían llegar los agentes construyendo una herramienta real.
El resultado: 55 releases, 1.192 commits y un cliente de base de datos que compite con herramientas de empresas con decenas de ingenieros.
Lo que tiene que DBeaver no tiene:
✅ Servidor MCP integrado - Claude, Cursor y Windsurf pueden leer tu esquema y ejecutar queries directamente desde el chat
✅ SQL Notebooks con gráficos inline y variables entre celdas
✅ Visual EXPLAIN con análisis de IA del plan de ejecución
✅ Constructor de queries visual con JOINs drag-and-drop
✅ Diagramas ER generados automáticamente
✅ Compatible con PostgreSQL, MySQL/MariaDB, SQLite y ClickHouse via plugin
✅ Editor Monaco con autocompletado inteligente
✅ Sin telemetría, sin cuentas, sin suscripción
Lo que DBeaver sí tiene y Tabularis todavía no:
SQL Server y Oracle. Si los necesitas, DBeaver sigue siendo la opción.
Para todo lo demás: esto arranca en 2 segundos, pesa menos y tu agente de IA puede consultarlo directamente.
el enlace 👇
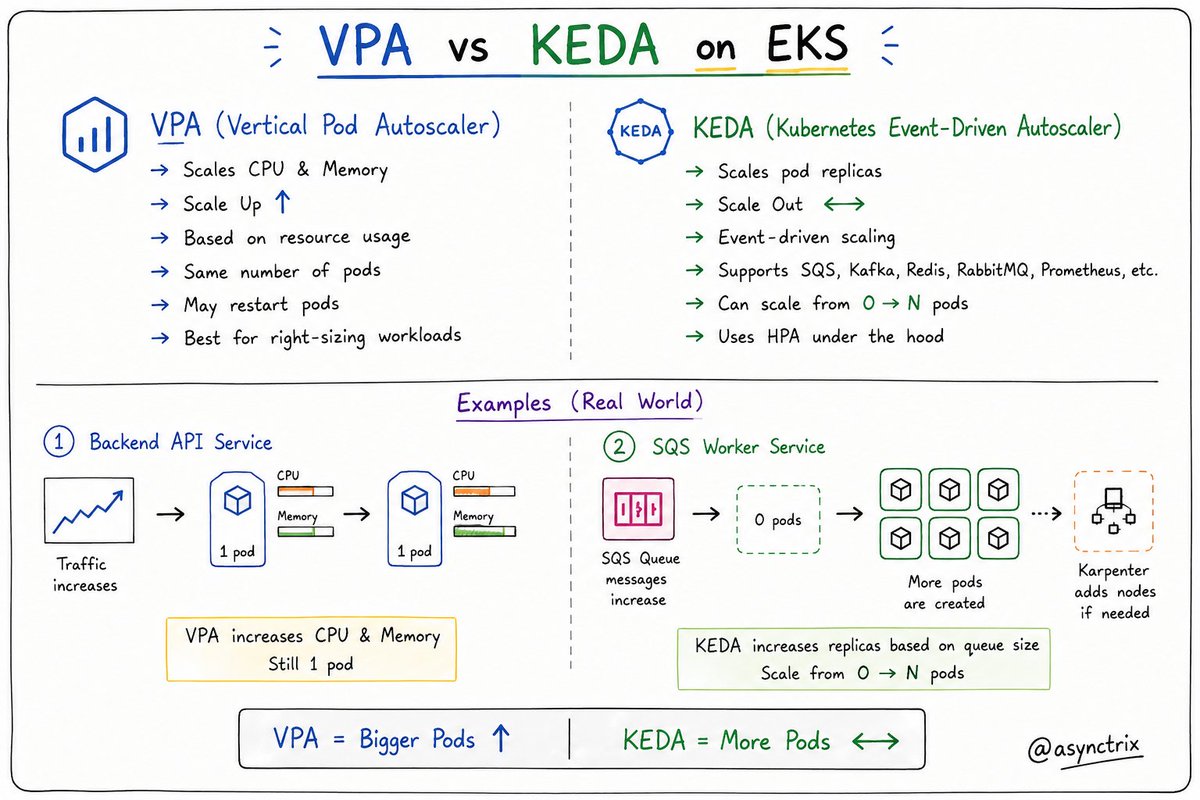
🚀 VPA vs KEDA on EKS
🔹 VPA (Vertical Pod Autoscaler)
↳ Scales CPU & Memory
↳ Scale Up ⬆️
↳ Based on resource usage
↳ Same number of pods
↳ May restart pods
↳ Best for right-sizing workloads
🔹 KEDA (Kubernetes Event-Driven Autoscaler)
↳ Scales pod replicas
↳ Scale Out ↔️
↳ Event-driven scaling
↳ Supports SQS, Kafka, Redis, RabbitMQ, Prometheus, etc.
↳ Can scale from 0 → N pods
↳ Uses HPA under the hood
📦 Real Examples
Backend API Service
↳ CPU usage increases
↳ VPA increases CPU & Memory
↳ Still 1 pod
SQS Worker Service
↳ Queue size increases
↳ KEDA increases replicas
↳ More pods process messages
↳ Karpenter adds nodes if needed
💡 VPA = Bigger Pods ⬆️
💡 KEDA = More Pods ↔️
Node Healthcheck Operator automatically detects unhealthy nodes and triggers pluggable remediators like BMC, ClusterAPI, or software reboots to recover workloads without manual intervention
➤ https://t.co/NisPVzVSli
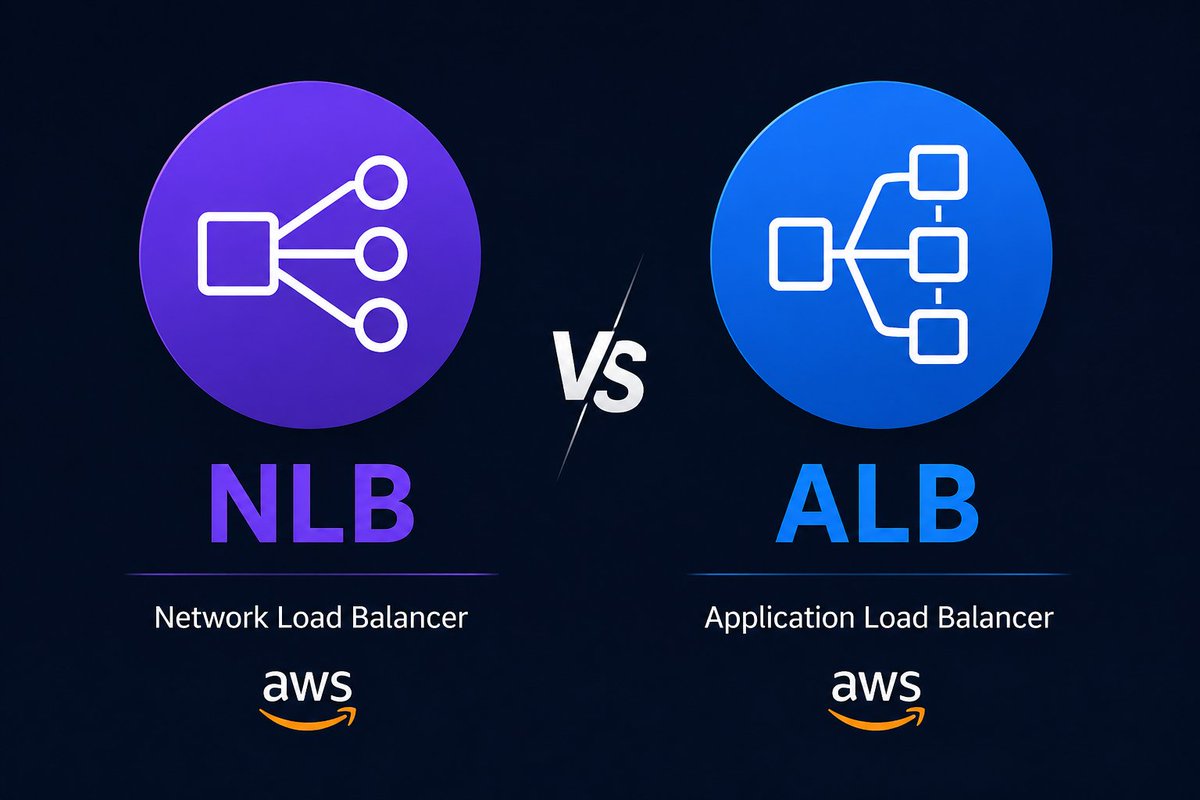
ALB ≠ NLB
Very few understand when to use each in production.
ALB (Layer 7):
→ Path-based routing (/api, /dashboard)
→ Host-based routing
→ WAF integration
→ HTTP → HTTPS redirects
NLB (Layer 4):
→ Static IPs
→ TCP/UDP traffic
→ Ultra-low latency
→ Millions of requests per second
Simple rule:
If you need smart HTTP routing, use ALB.
If you need static IPs, non-HTTP protocols, or maximum performance, use NLB.
If you need both, put NLB in front and use Traefik/Istio inside the cluster.
Choosing the wrong one can create unnecessary limitations later.
This article explains:
- why Kubernetes operator status conditions should be the single source of truth,
- how phase should be derived from conditions via declarative rules,
- and introduces a Go library for doing this with an interactive browser demo
➜ https://t.co/JgnpUlY2P1