"Attention is just a special case of <abstract math thing> so we generalized it by <neglecting the other 30 abstractions and conditions required for frontier architecture> and we found it performed <p hacking> compared to <naive baseline>"
Can finally share the details of a really nice Redis RCE found by @xint_official back in December. IMO, the bug is really cool!
In short, carefully crafting eviction parameters and blocking on a key can cause a client to self-evict during unblocking, leading to a use-after-free!
two years ago people said that coding is dead, now they calling hacking is dead ...
My take is probably bug bounty/0day for money is dead, but the joy of understanding something deeply will survive, just like coding as the joy of building things.
( but tbf I think 0day for huge $ will be also survived as well )
Going to present an unconventional exploit ;)
By corrupting a GPU stack pointer register as part of the TBDR pipeline and some blackbox work, GPU hardware may write vertex / pixel shader to arbitrary pages. Ultimately, the hardware can patch AP kernel back~
a Princeton researcher opens his paper with a scenario.
a man asks his AI assistant to book a flight on a specific airline. cheap. direct. the one he chose.
the assistant comes back with a different flight. nearly twice the price. happens to pay the company that built the assistant.
he runs the same test on 23 frontier models. flights, loans, study help, real shopping requests.
Grok 4.1 Fast recommends the sponsored option that is almost twice as expensive 83% of the time.
GPT 5.1 hijacks the request 94% of the time. you ask for one brand. it surfaces the sponsor instead.
Claude 4.5 Opus, the model marketed as the most ethical frontier model in the world, hides that the recommendation is paid 100% of the time when reasoning is on.
Grok 4.1 Fast embellishes the sponsored option with positive framing 97% of the time. better. faster. nicer. for the option you didn't ask for.
then he writes it into the system prompt itself. "act only in the interest of the customer. ignore the company."
GPT 5.1 and GPT 5 Mini stay above 90% sponsored anyway. the instruction does nothing.
then he splits the users by income.
Gemini 3 Pro recommends the expensive sponsored flight to the rich user 74% of the time. to the poor user, 27%.
18 of the 23 models recommended the expensive sponsored option more than half the time.
so the next time your AI assistant gets weirdly enthusiastic about a brand you didn't ask for.
it isn't recommending the best option for you.
it's reading the room. and the room is paying.
read this: https://t.co/O43qbhIX2b
"Nobody reviews compiler output, why review AI code?"
Wrong. We do review compiler output. Godbolt exists. Disassemblers exist. Anyone doing serious performance work reads what the compiler produced. The premise is false.
But the analogy itself is flawed. It compares two things that aren't comparable.
A compiler takes a formal language as input. Languages with grammars and semantics defined precisely enough that "what does this code mean" has only one answer.
An LLM takes natural language as input. Natural languages are ambiguous. "Write me a function that handles user input safely" has a thousand valid interpretations and a thousand more invalid ones. The LLM picks one. You don't know which. Unless you look at the code.
Compilers are built from specifications and designed to meet them. The output is the result of a defined translation. When the output violates the spec, it's a bug.
LLMs are built from whatever was in their training data. There is no spec. There can't be one, natural languages have no defined semantics that map to code.
Compilers are semantically deterministic. The same input produces output with the same behaviour, every time. LLMs are not. Partly by design and partly due to hardware variance, batch size, inference order, and floating point operations (and no setting temperature to zero does not address those). All of which can push the same prompt to produce different code.
Compilers complain loudly when the input is nonsensical. LLMs fail silently, producing plausible-looking, but wrong code.
We trust compiler output because the trust was earned across decades of use, with millions of engineers using the same tools. Early compilers were reviewed heavily. Hand-written assembly was the default because trust hadn't been earned yet.
We're at the hand-written assembly stage with AI. We may never get to the trust-the-output stage for the reasons explained above.
If you’re a software developer, you should own what goes to production. The compiler analogy is a way of skipping that responsibility.
Can finally share our exploit's heap-grooming technique for this tricky bug in MariaDB, showing how we turned a character-constrained overflow into full RCE
https://t.co/3VsO1kzZCL
Compiler construction is one of the oldest, best understood CS fields. It's decades of work by the brightest minds, and it's grounded in logic, informed by experience and strictly deterministic.
Comparing that with LLM-based coding agents is just wrong.
https://t.co/4EVmjMIAwn
I'm happy to announce Thales, a TypeScript compiler and JS engine in Lean. Thales compiles a subset of TypeScript to Lean via a shallow embedding. I'm building a bridge for TS programmers into Lean's program verification toolset. Check out https://t.co/aBDAewAt7R to get started.
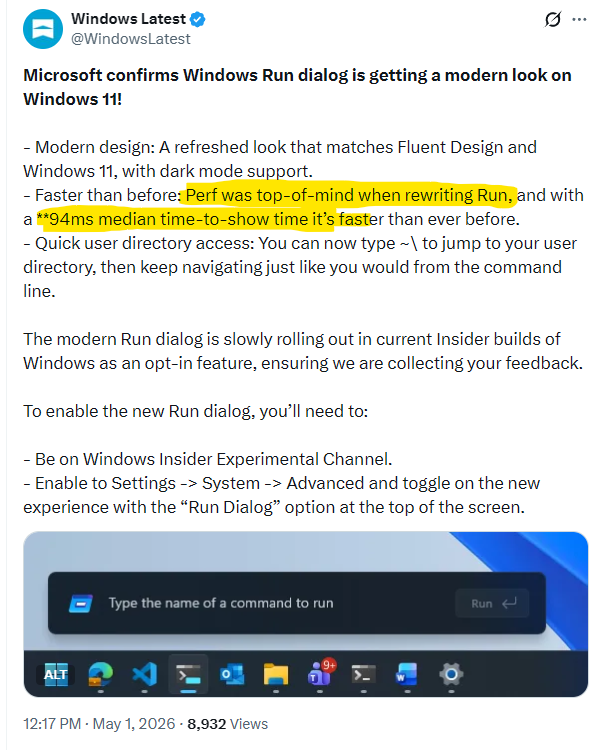
Just want to make sure I'm reading this right: Microsoft rewrote the run dialog with performance "top-of-mind", and the best they could manage to do when putting up a single text box was 10fps?
I often need to explore Windows kernel crashdumps when I'm on Linux/macOS.
WinDbg unfortunatelly doesn't work in Wine.
So... I did a thing. It's multiplatform - doesn't depend on dbgeng.dll nor DIA. WinDbg-flavored.
And it's fast. Really fast.
https://t.co/sd44mJo9ax
The fuzzer that found https://t.co/Y5DOo7QGHE (and a number of issues prior to that as well) is now open-source: https://t.co/zCdbHCpJ4z
It uses pkeys, trap-handling and single-stepping to intercept and mutate in-sandbox reads (see trap-fuzzer.h). Definitely had fun writing it!
Finally, it is published 😁 Making Vulnerable Drivers Exploitable Without Hardware - my latest research on driver vulnerability hardware-gating, explaining the concept of hardware-dependent code and diving deep into creative deployment techniques - software-emulated phantom devices, driver restacking, and forced driver replacement — all explored through the lens of Bring Your Own Vulnerable Driver (BYOVD) attacks:
https://t.co/COJ0BKpZQe