When AI becomes super efficient, human craftsmen will be an exquisite class.
The minor imperfections made by human will make a product even more valuable
🧠 Gemma 4 QAT checkpoints are out, and vLLM is Google's recommended way to serve them!
Open-source inference is at its best when one engine spans research and production — glad vLLM's is the recommendation for Gemma 4 QAT.
Get started 👇 https://t.co/9yeRmPjiVC
Good prompt:
___
https://t.co/tdvE4oRZxF study the rails docs. they have been updated a lot recently. is there anything worth applying/implementing to our app? am I missing any best practices?
___
Everything You Need To Know About
Inference Engines and Running LLMs Locally at Home
Explains why Inference Engines exist in the first place
- Prefill is not Decode
- VRAM is not bandwidth
- Fit is not speed
- KV Cache is the real memory problem
- Quantization only matters if the engine has good kernels for it
- Batching is not scheduling
- MoE and the routing problem
- How long context changes the serving problem
- Multi-GPU changes the interconnect problem
- Production: latency, p99s, backpressure, routing, metrics, and failure behavior
Then maps the Engines including:
- llama.cpp → portability king
- MLX / MLX-LM → Apple Silicon weapon
- ExLlamaV3 → multi-GPU consumer CUDA / local MoE
- vLLM → default open-source production server
- SGLang → long-context, MoE, routing, ugly workloads
- TensorRT-LLM → max NVIDIA performance
- NVIDIA Dynamo → fleet orchestration
The point of this article is not “use vLLM” or “use TensorRT-LLM” or “use llama.cpp”
But rather fully grasp how the Inference Engines are the traffic cop, memory manager, kernel dispatcher, scheduler, cache accountant, parallelism planner, API surface, and sometimes the deployment framework
Do not pick the engine first
- Pick the hardware
- Pick the workload
- Pick the serving model
Then the engine becomes obvious
Opensource / Local AI FTW
THIS GUY LIVES UNDER SFO'S TAKEOFF PATH SO HE BUILT A CEILING PROJECTOR THAT TRACKS EVERY PLANE FLYING OVER HIS HOUSE IN REAL TIME
he uses a cheap $30 radio receiver to pick up the signals that planes broadcast while flying.
then projects them onto his ceiling in real time
when a jet flies over his house you hear it outside and at the exact same moment a plane glides across his ceiling labeled with the airline, aircraft type, and destination
pure black background so the projector's rectangle disappears and only the aircraft are visible
but he didn't stop at planes
it also draws the real sky behind them. sun, moon, bright stars, constellations, and live satellites including the ISS. all at their true positions for his exact location and time in real time
so he's lying in bed watching the actual night sky projected onto his ceiling with real planes crossing through it as they take off from SFO
there is a huge market for every man alive that runs outside to see the helicopter
vibe coded the whole thing himself with a cheap radio, a projector, and some clever software
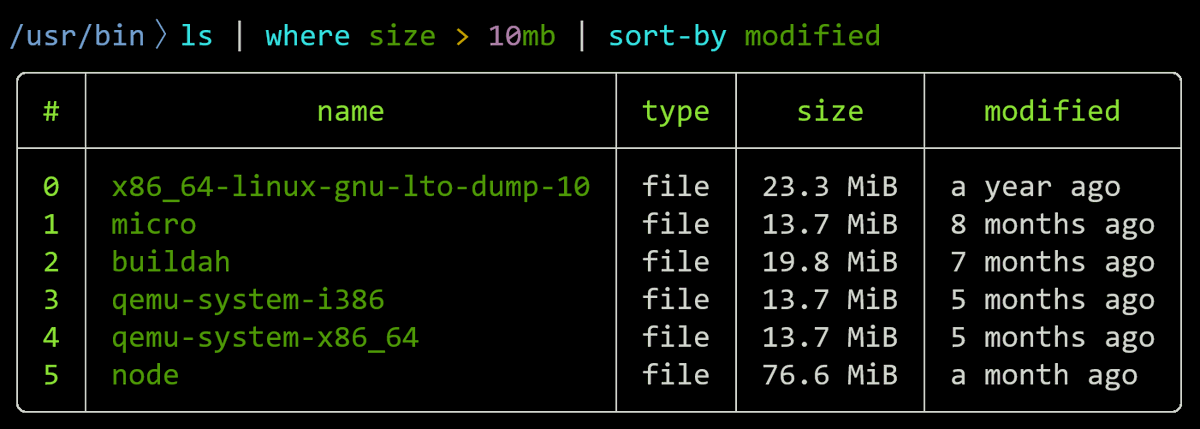
What is Nushell?
It's a modern shell (written in Rust) that treats everything as structured data — tables, records, lists — instead of raw text.
Pipelines feel like PowerShell + functional programming, but cross-platform and delightful.
https://t.co/Bfh6BOwBH5
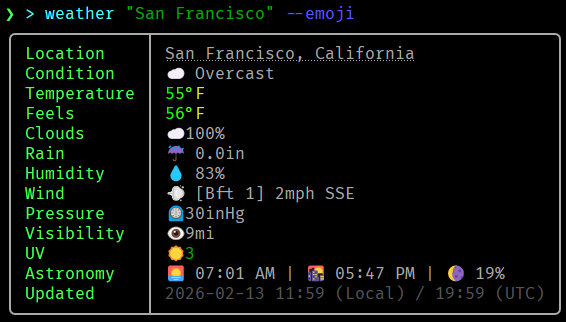
Did you know? You can pull beautiful weather from https://t.co/VtuCVhQ4Sl directly into Nushell and get clean, structured tables instead of raw text!
Current conditions, forecasts, and more — all pipeable and ready to use. No grep or sed needed. ☀️
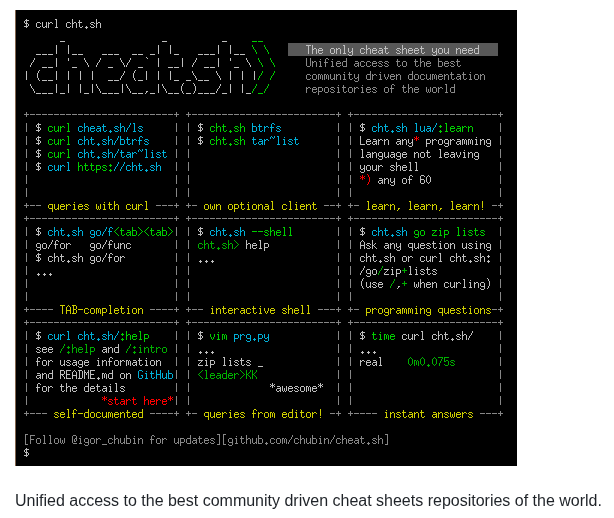
https://t.co/VtuCVhQ4Sl was fully rewritten from scratch, this time in Go.
What we achieved: high performance and reliability (the main goals), the new architecture is very clean, deployment is trivial now (a single binary), and the code is super simple too. I like it.
New open model Ideogram-4.0-Quality has landed at #8 in the Text-to-Image Arena. This makes the new model by @ideogram_ai the #1 open model in that arena! Scoring 1204, this open model approaches the performance of Nano Banana Pro.
Congrats to the @ideogram_ai team on this release!