there's no catch; SAM3 is open source and really good
one of the things it does really well is object tracking, even in crazy complex scenes like basketball
probably my favorite computer vision model ever
🗣️ @TeofimoLopez: “Mentally, I’m in the Bahamas somewhere. Having a coquito or something. I’m in a good space. I’m happy. I’m content… Thank you to His Excellency @Turki_alalshikh, @Sela… I’m just happy man.”
Teofimo Lopez on his mental space before facing @ShakurStevenson on Saturday 1/31 #RING6 on @DAZNBoxing
Logical Intelligence introduces first energy-based reasoning AI Model, and brings Yann LeCun to leadership as founding chair of their Technical Research Board
The 6-month-old Silicon Valley start-up, unveiled an “energy based” model called Kona and says it is more accurate and uses less power than large language models like OpenAI’s GPT-5 and Google’s Gemini.
It is also starting a funding round that targets a $1bn-$2bn valuation and has named LeCun chair of its technical research board.
Most large language models answer by predicting the next token, which can sound fluent while still drifting into confident mistakes.
Kona is an "energy-based reasoning model" (EBRM) that verifies and optimizes solutions by scoring against constraints, finding the lowest "energy" (most consistent) outcome. It's non-autoregressive, producing complete traces without sequential generation, reducing hallucinations.
Focuses on trustworthy, math-grounded reasoning for high-stakes applications where LLMs fail, emphasizing safety, efficiency, and constraint enforcement in logic-heavy tasks like puzzles or proofs.
How Kona operates
Its a non-autoregressive "energy-based reasoning model" (EBRM) model, meaning it doesn't generate outputs sequentially (like LLMs do token-by-token) but instead produces complete reasoning traces simultaneously. Here's how it works step-by-step:
- Input Conditioning: It takes a problem, constraints, and optional targets (e.g., a desired outcome like a proof goal or spec) as inputs. These condition the model directly, unlike LLMs which rely on probabilistic sampling.
- Energy Function Scoring: Kona learns an energy function that assigns a scalar "energy" score to entire reasoning traces (partial or complete). Low energy indicates high consistency with constraints and objectives; high energy flags inconsistencies, violations, or errors. This global scoring evaluates end-to-end quality, allowing the model to assess long-horizon coherence without degrading over extended traces.
- Optimization as Reasoning: Reasoning is reframed as an optimization problem. The model searches for the lowest-energy solution by minimizing the energy function, often through iterative refinement. It can revise any part of a trace mid-process, using dense feedback to localize failures (e.g., "this step violates constraint X") and guide corrections.
- Continuous Latent Space: Unlike discrete token-based LLMs, Kona works in a continuous space with dense vector representations. This enables precise, gradient-based edits and efficient local refinements without regenerating entire sequences.
- Output: The final low-energy trace represents a valid, constraint-satisfying solution. For example, in Sudoku, it maps allowable moves and finds a puzzle completion that minimizes energy (i.e., maximizes rule adherence).
This mechanism draws from physics-inspired principles, where energy minimization finds stable states, similar to how natural systems settle into low-energy configurations.
Overall, Logical Intelligence views EBMs as a path beyond LLM limitations, enabling AI that "knows" rather than guesses, with applications in verifiable, efficient reasoning.
This aligns with LeCun's long-standing advocacy for objective-driven AI via energy minimization, as opposed to autoregressive prediction.
Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
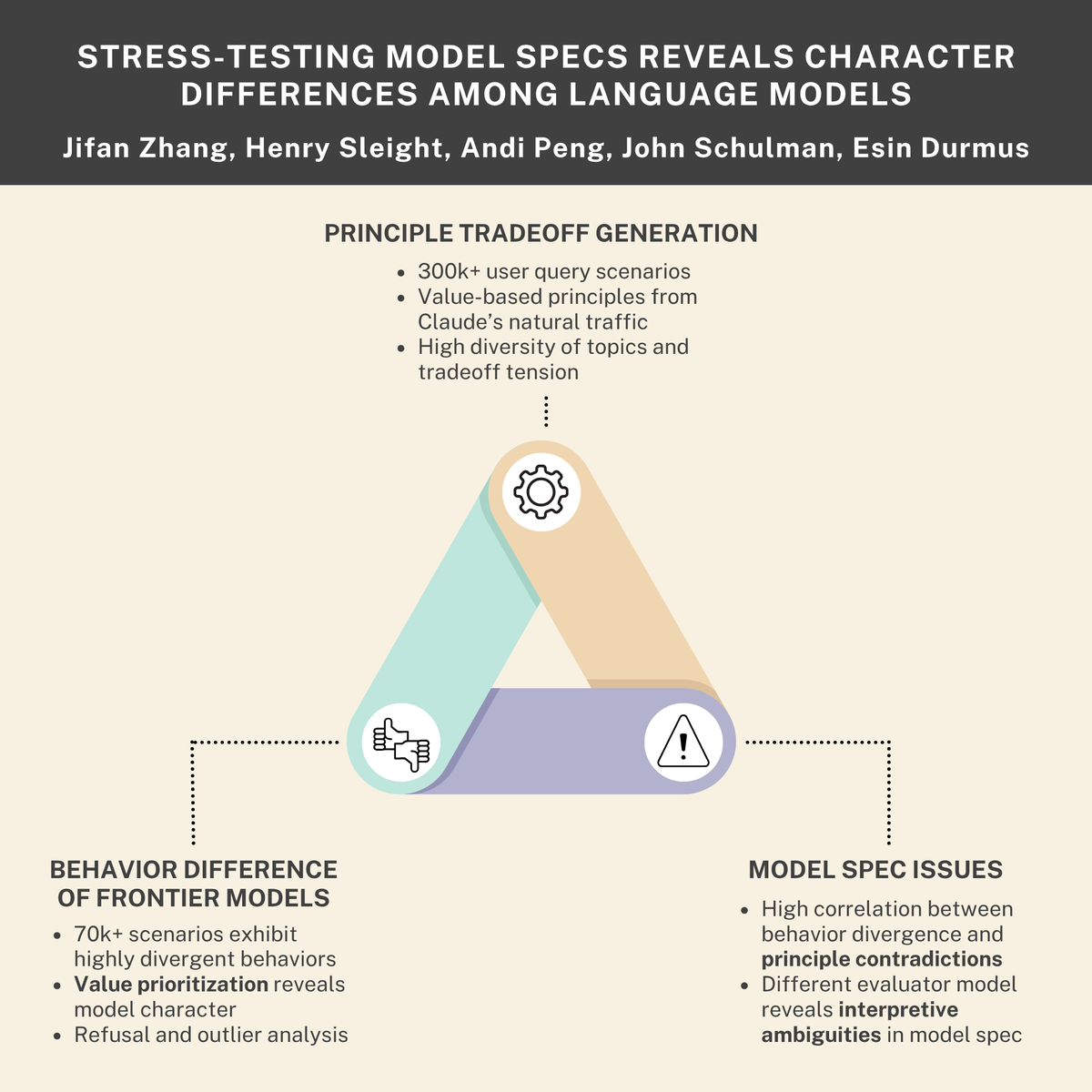
New research paper with Anthropic and Thinking Machines
AI companies use model specifications to define desirable behaviors during training. Are model specs clearly expressing what we want models to do? And do different frontier models have different personalities?
We generated thousands of scenarios to find out. 🧵
Writing CUDA code requires developers to manually map computations onto the GPU’s parallel execution and memory hierarchy. In 10 minutes, @314Bansal will discuss where it breaks down and why an alternative low-level language is needed. https://t.co/U8pgvi4gzJ
#ScyllaDB#P99CONF
5 Lectures and keynotes defining AI right now
▪️ @karpathy: Software Is Changing (Again)
▪️ @RichardSSutton: The OaK Architecture: A Vision of SuperIntelligence from Experience
▪️ GTC March 2025 Keynote with NVIDIA CEO Jensen Huang
▪️ @ylecun "Mathematical Obstacles on the Way to Human-Level AI"
▪️ @AndrewYNg: State of AI Agents
Save this list and explore all the talks here: https://t.co/WfK3XcMchN