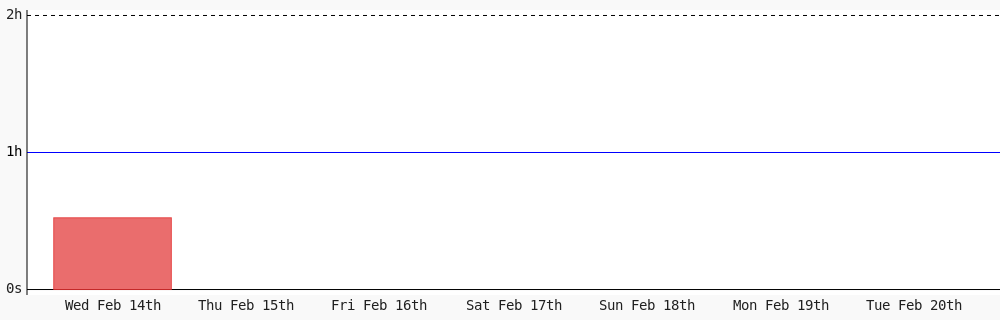
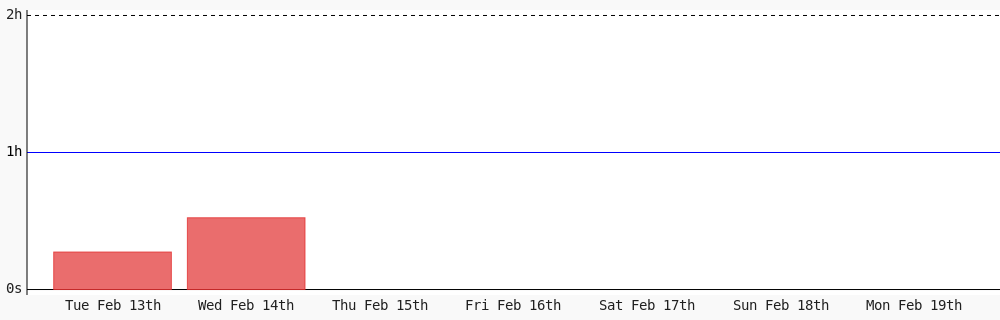
I found the OCR tool built for the LLM era.
It is called olmOCR.
olmOCR takes PDFs, scans, PNGs, and JPEGs and turns them into clean Markdown that models can actually understand.
It handles the stuff that normally breaks document pipelines:
→ Tables
→ Equations
→ Handwriting
→ Multi-column layouts
→ Figures
→ Insets
→ Old scans
→ Headers and footers
→ Natural reading order
So instead of feeding your AI a messy PDF dump, you give it structured Markdown that preserves how the document was meant to be read.
This matters because so much of the world’s knowledge is still trapped inside PDFs.
Research papers.
Legal filings.
Financial reports.
Medical documents.
Scanned archives.
Government docs.
Internal company knowledge.
Everyone is building RAG on top of documents.
But if your OCR is bad, your AI is already wrong before retrieval even starts.
olmOCR fixes the first mile.
The boring layer.
The layer nobody talks about until their agent starts hallucinating from broken PDF text.
https://t.co/H1pdZny6SK
System Design Playbook
Giveaway Alert!!
• System design foundations.
• Condensed notes to read for the system design interview.
• Must know concepts from software engineering case studies.
(24 hours only!)
To get it:
1 Like, Retweet & Follow @systemdesignone
2 Reply "Playbook"
Then I'll DM you the details.
Banyak konflik kerja bukan karena kurang pintar, tapi soft skill lemah
Ada yang pintar tapi susah kolaborasi. Ada yang rajin tapi gak adaptif.
Gue ada kuis yang bisa bantu lo mengukur soft skill yang lo punya
Follow, like, retweet & reply “KUIS”
Gue send link nya di DM
PYTHON is difficult to learn, but not anymore!
Introducing "The Ultimate Python ebook "PDF.
You will get:
• 74+ pages cheatsheet
• Save 100+ hours on research
And for 48 hrs, it's 100% FREE!
To get it, just:
1. Like & RT
2. Reply "PY"
3. Follow @Ronycoder [MUST]











![Ronycoder's tweet photo. PYTHON is difficult to learn, but not anymore!
Introducing "The Ultimate Python ebook "PDF.
You will get:
• 74+ pages cheatsheet
• Save 100+ hours on research
And for 48 hrs, it's 100% FREE!
To get it, just:
1. Like & RT
2. Reply "PY"
3. Follow @Ronycoder [MUST] https://t.co/Sm7EtJpUgM](https://pbs.twimg.com/media/GmPd6pkbIAAxW2k.jpg)