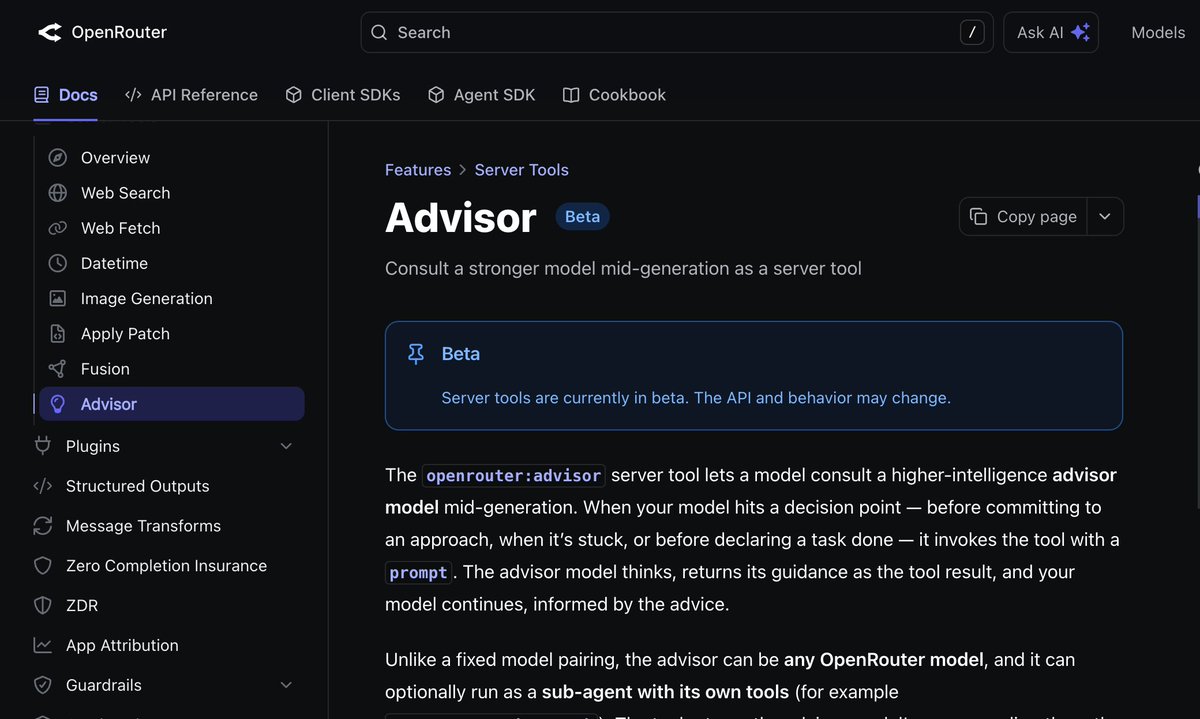
New server tool: Advisor
Let smaller models consult a higher-intelligence "advisor" model.
Helps them escape doom loops, and helps you migrate to cheaper models! 🧵
🚀 1,000+ TOKENS/S ON A 1T MODEL! 🚀
We are thrilled to release Xiaomi MiMo-V2.5-Pro-UltraSpeed in collaboration with @TileRT_AI , breaking the 1,000 tokens/s output speed on a 1 Trillion parameter model for the FIRST TIME!
Not wafer-scale integration like Cerebras. Not pure on-chip SRAM chips like Groq. We achieve 1,000 tps on a 1T MoE model using just a SINGLE, STANDARD 8-GPGPU NODE.
Read the full technical deep dive:https://t.co/MX0kjHKdKi
Want to experience the future of real-time AI?
👉 Apply for UltraSpeed now: https://t.co/aeWAxyhwVk
⏳ Limited-Time Access: Application-based · Jun 8 – Jun 23 (PDT)
💬 Chat Experience: Completely FREE for a limited time — try the blazing-fast web chat now.
⚡ UltraSpeed API: Just 3x the price for a ~10x boost in output experience.
🤝 Enterprise & Large-Scale Needs: [email protected]
Nex-N2 is now open source!An agentic model series from Nex AGI built for coding, tool use, deep research, and long-horizon workflows. 🧠🔎
🛠️ https://t.co/p2n2cMdBlR
⚙️ https://t.co/k67uqVgDDP
● Models: Nex-N2-Pro 397B total, 17B active; Nex-N2-mini 35B total, 3B active
● Agentic Thinking: adaptive reasoning depth + coherent reasoning across coding, search, tool calling, and execution
● Efficiency: Nex-N2-mini saves roughly 20% overall token cost vs forced thinking while matching or slightly exceeding task performance
● Open-model lead: 75.3 on Terminal-Bench 2.1, 80.8 on SWE-Bench Verified, 83.7 on BrowseComp, and 1585 on GDPval among listed open baselines
● Deployment: customized SGLang fork, reasoning parser, tool-call parser, Docker image
● License: Apache 2.0
ok @q_yeon_gyu_kim 's @AnthropicAI oss support is gone after ultracode copy thing
now it's our turn
ultracode -- which is our 'ultrawork'
but in your codex.
```
npx lazycodex-ai install
```
and $ulw-loop instead of your ultracode copy shit
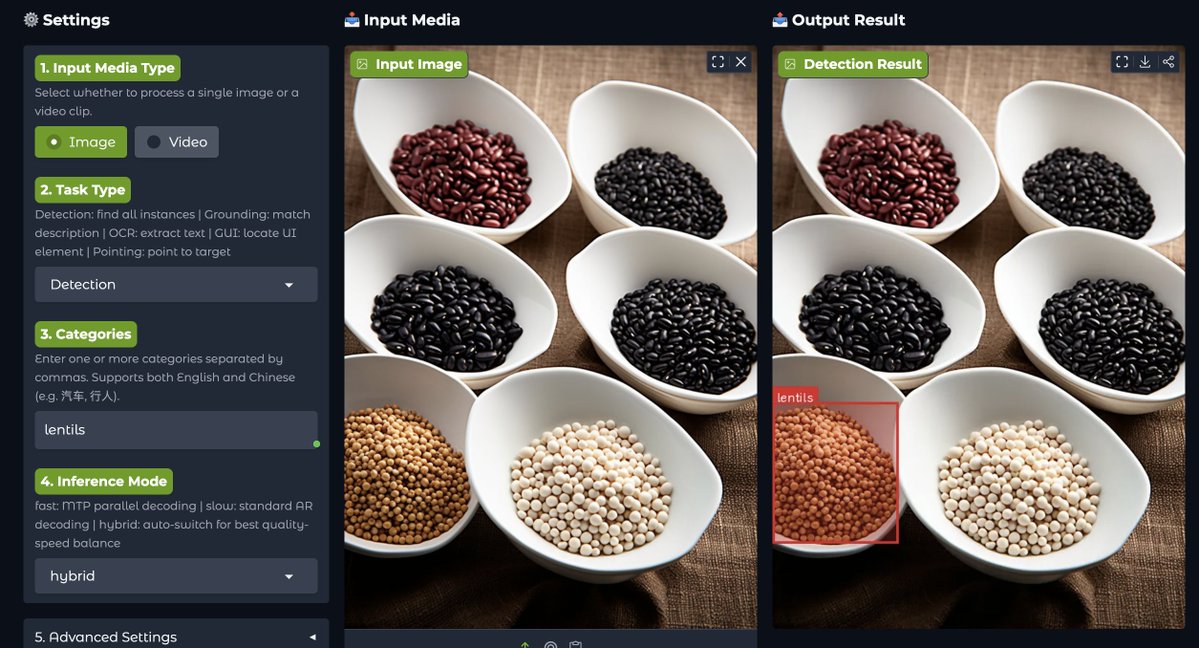
Just tried out NVIDIA's latest vision language detection model.
Tried with 2 images. As you can see, the first image is where I asked to detect only lentils, and in the other one, I tried to find more than one thing.
Worked really well. I tried it in Hugging Face Spaces.
NVIDIA just dropped LocateAnything-3B, which is new vision-language model that could be a major step forward for embodied AI and robotics.
Instead of generating bounding box coordinates one token at a time, it introduces Parallel Box Decoding, allowing AI systems to locate objects much faster while improving accuracy.
The model was trained on over 138 million language queries and 785 million bounding boxes, enabling everything from object detection and GUI understanding to robotics and autonomous systems
NVIDIA claims up to 2.5x higher throughput, making AI agents faster at seeing, understanding, and interacting with the real world.