Proximity to SF doesn't matter if you use Twitter Correctly.
https://t.co/fIBkJVm26e is 2 months ahead of SV/founders/eng
(if you curate your feed correctly and are in the right group chats)
How do you scale LLM inference without the "Day 2" operational headaches?
We just shared a new deep dive on the llm-d blog: building a production-grade stack with KServe + vLLM + llm-d. Collaborative work with Red Hat & Tesla.
Read the full breakdown: https://t.co/HGhTEAidZa
Día 1 automatizando la operativa de mi startup con IA.
Objetivo: reportes de progreso y estado. No tener que estar revisando el jira, Linear o kanban de turno; se acabó estar solicitando reportes a tus compañeros:
It’s official: llm-d has joined the @CNCF! 🚀
Our mission to evolve Kubernetes into SOTA AI infrastructure just got a massive boost. This milestone belongs to our amazing community. Thank you for building this with us. 💜
We’re just getting started!
🔗 https://t.co/61sgQGsLKK
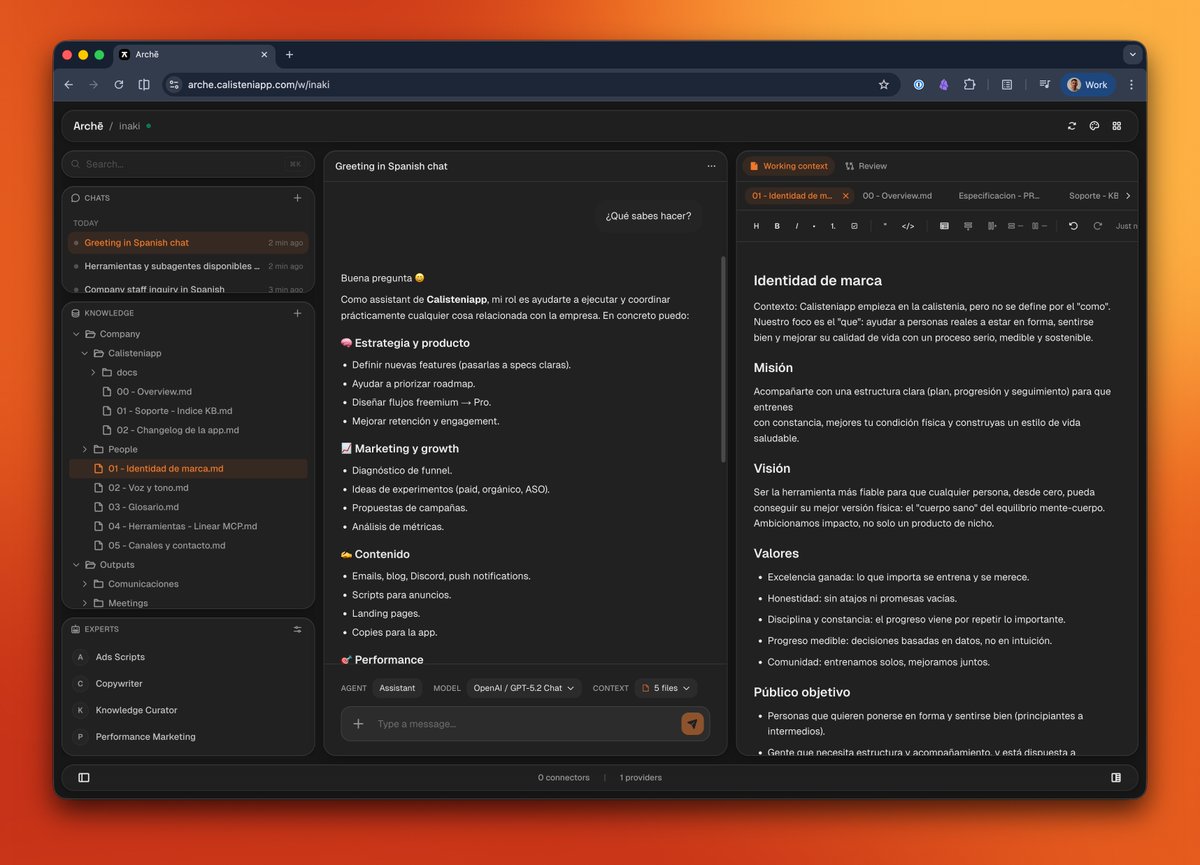
Archē is live! An open-source, AI native operating system for your company.
One goal: Bring the best tools together and create shared context for more efficient day to day operations.
It is built around @opencode and adds a layer of sugar. Custom tools, a shared versioned knowledge base, multi user remote workspace, and centralized configuration.
Best part. One click deploy on a cheap VPS. Up and running in minutes with its templating engine.
If you like it, try it and share. Still early stage. PRs welcome.
Cc: @p3rd0mo@ixJosemi
Archē is live! An open-source, AI native operating system for your company.
One goal: Bring the best tools together and create shared context for more efficient day to day operations.
It is built around @opencode and adds a layer of sugar. Custom tools, a shared versioned knowledge base, multi user remote workspace, and centralized configuration.
Best part. One click deploy on a cheap VPS. Up and running in minutes with its templating engine.
If you like it, try it and share. Still early stage. PRs welcome.
Cc: @p3rd0mo@ixJosemi
Se acabó el misterio, presentamos Archē.
El nuevo sistema operativo de tu empresa.
Si eres emprendedor o pequeña y mediana empresa, esto te interesa.
La pieza que faltaba para modelar conocimiento y procesos de forma universal, precisa y accesible por todo tu equipo:
00:00 - Contexto y dolores
09:53 - MVP (Obsidian + Opencode + MCPs)
13:30 - Arché
32:05 - Cómo probarlo
AI is the new OS, that's it. Síguenos para enterarte cuando esté disponible.
cc @p3rd0mo , @ixJosemi
Esta combinación de agentes con knowledge base es la que disparó la idea de algo muy top que estoy construyendo.
Hice un mvp para Calisteniapp y ya lo uso todos los días.
Lo comparti con @p3rd0mo y @ixJosemi y no pudimos evitar montar un oneclick deployment para que cualquiera pueda sacarle partido.
más sobre esto sooooon.
Okay so I need to talk about what’s happening with Yann LeCun because this is genuinely one of the wildest exits I’ve ever seen in tech.
For those who don’t know—LeCun is one of the “godfathers of AI.” Not a marketing title. The man literally won the Turing Award (basically the Nobel Prize of computer science) for helping invent deep learning. He’s been at Meta for over a decade as their Chief AI Scientist. An absolute legend.
So here’s what happened.
Zuckerberg got frustrated. Llama wasn’t moving fast enough. The AI race was heating up and Meta felt like it was falling behind. So what does Zuck do? He drops $14 BILLION on Scale AI and hires its 28-year-old co-founder, Alexandr Wang, to run a brand new “Superintelligence Lab.”
And then—and this is the part that still blows my mind—he makes Wang… LeCun’s boss.
Think about that for a second. A 65-year-old Turing Award winner. Four decades of groundbreaking research. The guy who helped BUILD this entire field. Now reporting to someone whose company… labels data. (Scale AI is impressive, don’t get me wrong, but they don’t actually build AI models. They annotate training data for other companies.)
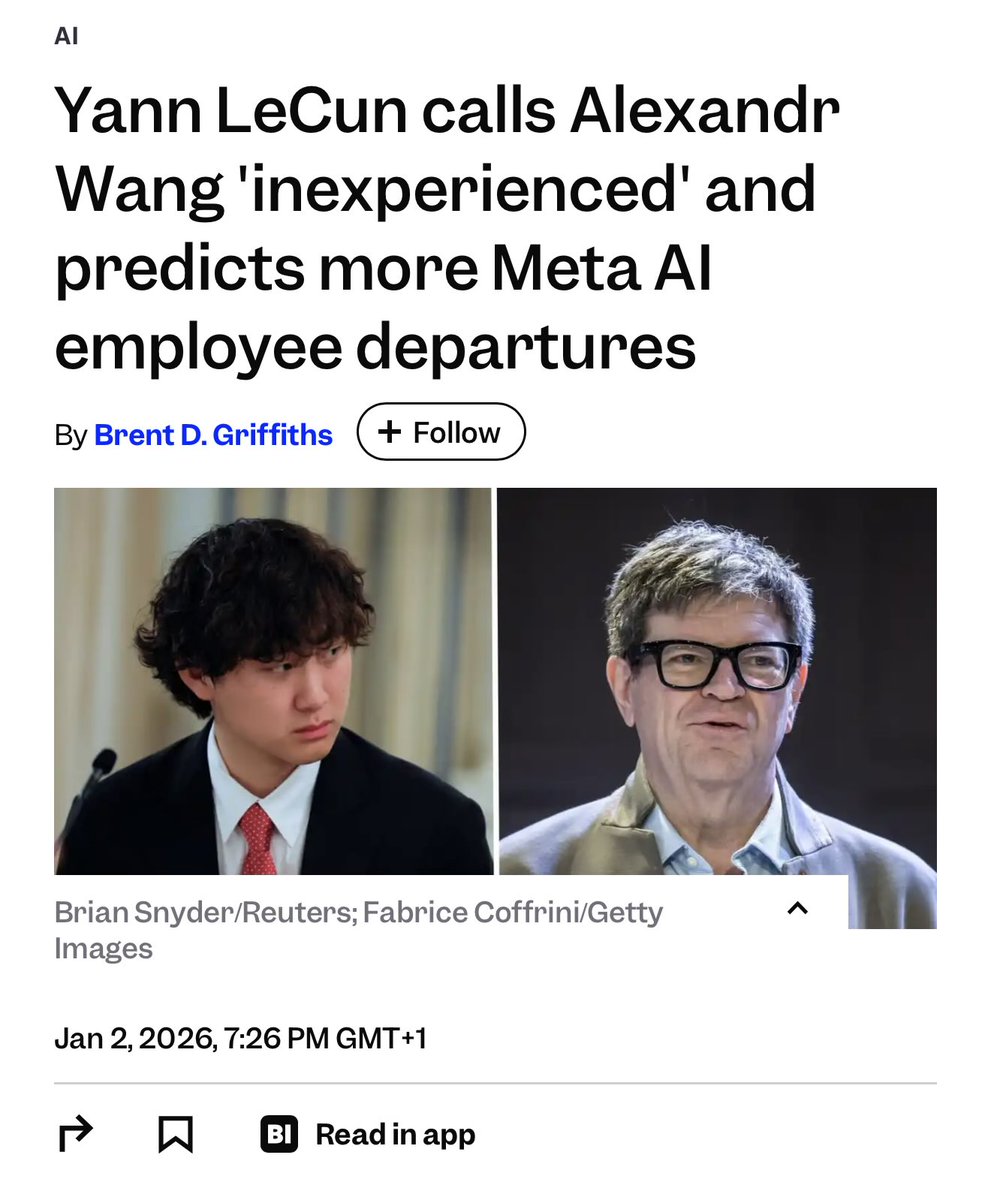
LeCun just did an interview with the Financial Times and honestly? He chose violence.
Called Wang “young” and “inexperienced.” Said he has “no experience with research or how you practice research, how you do it. Or what would be attractive or repulsive to a researcher.”
And then dropped this absolute gem: “You don’t tell a researcher what to do. You certainly don’t tell a researcher like me what to do.”
I mean. The man said what he said.
But wait—it gets better. Or worse, depending on how you look at it.
LeCun straight up confirmed that Meta’s team “fudged” the Llama 4 benchmark results. Like, actually manipulated them. Used different models on different tests to make the numbers look better. Remember when everyone was suspicious about those benchmarks back in April? Yeah. Turns out they were right to be.
Apparently Zuckerberg was furious when this came out internally. LeCun says he “lost confidence in everyone who was involved” and basically sidelined the entire GenAI team.
And here’s the thing that really gets me—LeCun has been saying for YEARS that LLMs are a “dead end.” That you can’t get to real intelligence just by predicting the next word. That we need “world models” that actually understand physical reality, not just language patterns.
Everyone at Meta wanted him to stop saying this publicly. Bad for the narrative, you know? But LeCun refused.
His exact words: “I’m not gonna change my mind because some dude thinks I’m wrong. I’m not wrong.”
That’s not arrogance. That’s a scientist who’s seen enough hype cycles to know when something doesn’t add up.
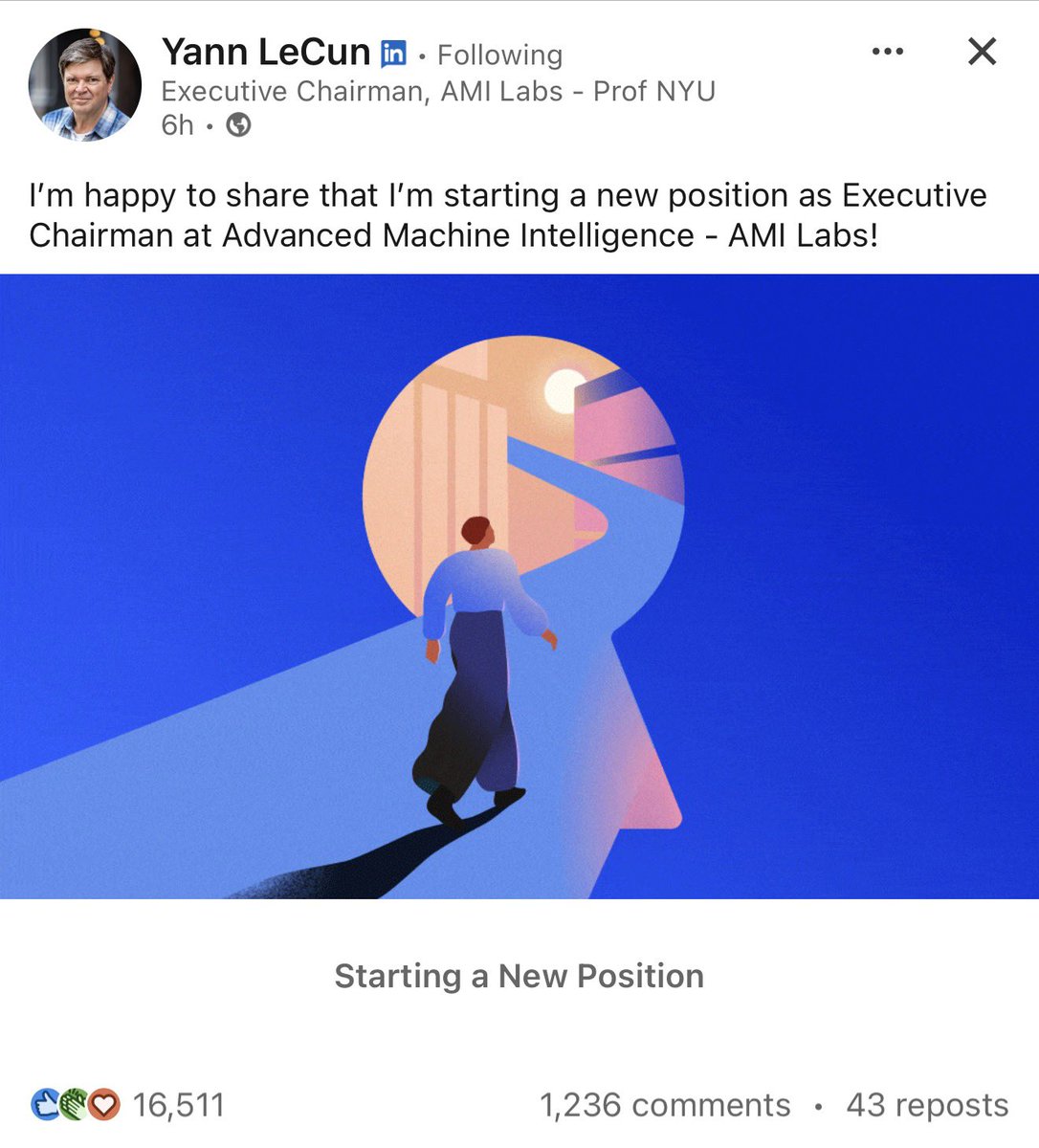
So now he’s out. Launching his own company called AMI Labs—Advanced Machine Intelligence. They’re targeting a $3 billion valuation. Building those world models he’s been talking about. Says he’ll have a “baby version” ready within a year.
Oh, and apparently French President Macron personally texted him after the news dropped. LeCun won’t say what the message said but like… the man is getting DMs from heads of state now.
I don’t know if LeCun is right about everything. Maybe LLMs will surprise us. Maybe Meta will figure it out. But when one of the three people who literally invented modern AI walks out the door saying your entire strategy is fundamentally flawed?
I don’t know man. I’d at least ask some questions.
The AI wars just got very, very interesting
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
Are you running vLLM on Kubernetes and tired of guessing concurrency thresholds? This new Red Hat article walks through how to autoscale vLLM on OpenShift AI using real service metrics instead of generic request counts. KServe and KEDA work together to scale GPU model servers based on token latency and other signals, which delivered better results than Knative concurrency based autoscaling in performance tests.
Worth a read if you are looking to improve efficiency and responsiveness in LLM workloads: https://t.co/ZNCqv0qgTO
@ixJosemi@zeroxjackson obsession! you need to be longing to be fit and healthy so badly that you cannot let another day pass without acting on it - same obsession you bring to your work, it has to be in you, dawg!
we are live.
You can now download AURA, the easiest way to iterate through ideas exactly when inspiration strikes.
Sure, you can do this with ChatGPT.
But I believe the future lies in perfectly sliced use cases, delivered through beautiful, focused software pieces.
For decades, businesses have grown by adding more and more features, creating bloated monsters (even me with @calisteniapp )
I refuse that path. Less is better.
The era of micro–use-case software has begun.
This shift matters. It leads us toward freedom and progress.
Smaller, distributed tools mean more focus, lower entry barriers, and no mega–corporate lock-ins disguised as "the ecosystem"
The ecosystem should be open and distributed, giving everyone the freedom to build, share, and choose what fits their needs best.
We’ve all seen what happens when you put all your eggs in one basket, recent AWS outages, Apple’s control over app distribution and guidelines, and more.
We can fight this in many ways:
- By choosing open tech stacks like Flutter that run on almost any device and OS.
- By refusing to build all-in-one tools that try to do everything and trap you in their ecosystem.
AURA is built with this philosophy in mind:
- It solves one problem: capturing and iterating on ideas.
- It runs on everything: mobile, desktop, and soon the web.
- It uses open, human-readable data stored in simple Markdown files like @obsdmd
- It’s free to use, with your own API key.
How it works:
1. Inspiration strikes, you hit record.
2. The recording is transcribed, named, and sorted automatically.
3. You can add new iterations as your idea evolves.
4. Your idea is ready to continue its natural path, with a text editor, ChatGPT, or any tool you like.
Hope you like it