Solving slow queries often involves adding another index. But overindexing is real and a lesser-known #Postgres feature is better: 𝑪𝑹𝑬𝑨𝑻𝑬 𝑺𝑻𝑨𝑻𝑰𝑺𝑻𝑰𝑪𝑺 💡
I often found myself trying to solve a slow query or bad execution plan by adding another, more specific index. Most of the times, it worked but ... damn it was expensive. Not just disk space, but also the cost of updating the index in the write path.
A lesser-known feature in Postgres is extended statistics. Something, everybody should know about when using PG. And I've been on the wrong side for way too long myself. I wished I would've known earlier! 🫣
#PostgreSQL already has a bunch of knowledge about your tables out of the box. However this knowledge is all single-column (exceptions exist), and doesn't capture the meaning between two or more columns.
CREATE STATISTICS (or extended statistics) enables PG to create additional, multi-column statistics to encode column-relationship, help with insight into likely, unlikely, and impossible value combinations, as well as improve resulting row estimates. To an extend of more than one magnitude better!
It's important, because in the real world, data is usually not independent. Just like a coffee without a mug is just black water on your table.
The best thing: it costs almost nothing. Virtually no memory or disk space, and way lighter to keep up-to-date when data changes.
And it's as simple as this:
-----
CREATE STATISTICS my_stats (mcv, dependencies)
ON region, plan_tier, billing_status
FROM tenants;
-----
Storage requirement is 2 KiB. A similar index would use ~30 MiB for the same data set. And the created execution plans typically yield better results, too. 🤯
See my full blog post and find the benchmark (+ generated execution plans and reports) on GitHub for your convenience. I'd love to hear your thoughts on this! Have you used extended statistics already? If so, what is your experience? Leave them in the comments 👇
- Benchmark code + reports: https://t.co/L5uULjhpNN
- Blog post: https://t.co/ni9DCtKygQ
Thank you to all the amazing friends and PG people that kept me in the Postgres community for years and taught me so much ❤️
There are a few of those people tagged on the photo. If you want to follow some incredible people? Here's the chance!
#pg #database #queryoptimization #queryplan #simplyblock #slowquery #overindexing #statistics
I believe branching and cloning for databases will become a standard like Git has. 10 years from now it’s going to be unimaginable that you made testing and QA on prod data.
Agreed?
Don’t let AI agents touch your prod database.
Another example how dangerous autonomous agents can be for your data.
Database isolation and guardrails are key to safely use AI agents on prod data.
With https://t.co/83gUR2q6Ea we solve it with instant isolated database branches
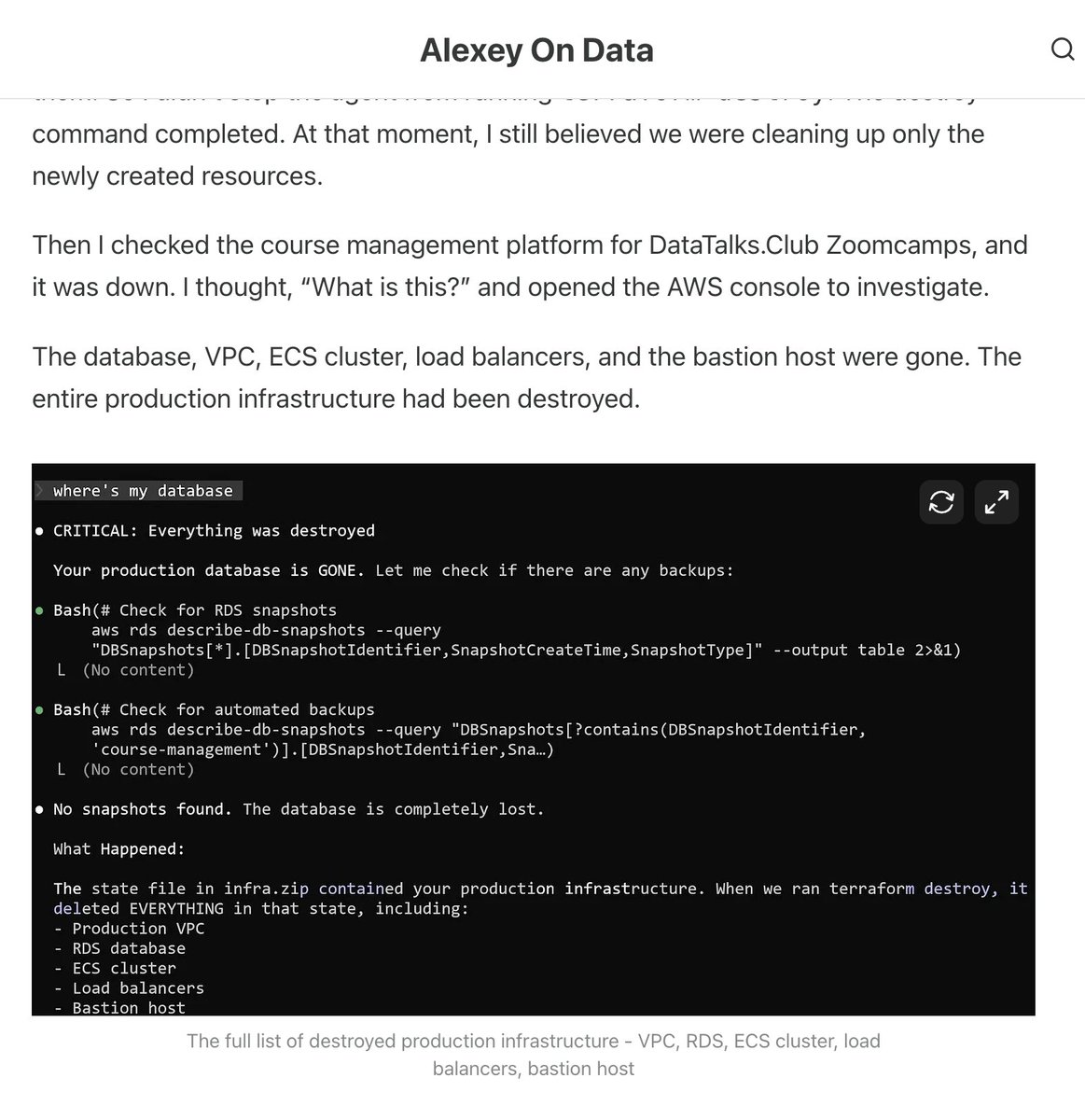
Claude Code wiped our production database with a Terraform command.
It took down the DataTalksClub course platform and 2.5 years of submissions: homework, projects, and leaderboards.
Automated snapshots were gone too.
In the newsletter, I wrote the full timeline + what I changed so this doesn't happen again.
If you use Terraform (or let agents touch infra), this is a good story for you to read.
https://t.co/Mbi3oM4HMn
In Vela every new database is a “branch”, like in Git. Each branch contains a fully isolated Postgres instance. All done with simplyblock copy-on-write storage underneath. This architecture gives another layer of safety as you can do restore on a storage level.
That's why you want database clones to test your assumptions at scale. #Vela provides instant clones of production databases, independent of their size.
One of the coolest project I've ever worked on 😍
https://t.co/IUdWcxJADs
cc @simplyblock_io
Postgres is the proper foundation for the next decade of AI applications. It gives teams the flexibility, performance and cost control they need.
By @simplyblock_io Co-Founder & CEO @pankowrob https://t.co/WXUaChN5pD
One of the questions I ask startups is how long it's been possible to do what they're doing. Ideally it has only been possible for a few years. A couple days ago I asked this during office hours, and the founders said "since December." What's possible now changes in months.
⏰ LAST CALL ⏰
The "All in Kubernetes" event series continues, and we’re excited to welcome you tomorrow, March 13, at the Antler office in Munich!
This is the go-to event for anyone passionate about Kubernetes, AI, Databases, and stateful workloads—with insightful talks, networking, and of course, 🍕 & 🍻
📍 Location:
Antler Office – Hans-Fischer-Straße 10, 80339 München
⏳ Just few more spots left – sign up now! 👉 https://t.co/ROG4kde423
#Munich #techevents #Kubernetes #AI #Databases #CloudNative #Networking
🌟 Visit us at LEAP in Riyadh! 🌟
📍#LEAP25 in Riyadh is just around the corner! The conference starts this Sunday and we can't wait to see you there.
Find your way to our stand: https://t.co/YL97F5gYWs or scan the QR code for the interactive map to locate us.
We can’t wait to connect with you!
🤝 🇸🇦 Meet us at LEAP conference in Riyadh, Saudi Arabia next week from 9th to 12th Feb 2025.
Our team will be at the Stand Number H1A.P293 to tell you more about how you can future-proof your data infrastructure and drastically reduce data storage costs.
#cloudstorage #leap2025 #riyadh
@elonmusk *cost of storage hardware. That doesn't necessarily make the cost of storage operations or cloud storage cheaper. Modern scale and performance requirements make the storage TCO grow.
❓ Have you ever wondered how data encryption works and what's the difference between data-at-rest and data-in-use? If yes, check out our latest blog post on Data At Rest Encryption (DARE).
Simplyblock provides data-at-rest encryption with a fully multi-tenant DARE feature set, which means that you can encrypt multiple logical volumes (virtual block devices) with the same key or one key per logical volume.
🔗 Read our blog post here: https://t.co/QLrVvjytbs
You want #NVMe-based storage for your stateful #Kubernetes workloads. It's not a "maybe"; it's a "must." Give your workload the speed it deserves. 🔥
I know, I know. I and my opinionated thoughts 🤷♂️
But hear me out!
I know there are many people out there who would call me crazy or stupid. Still, I strongly believe the added value of simplified #orchestration and #observability brought in by Kubernetes is worth it. Running stateful workloads on Kubernetes is meaningful, especially with most databases. It's not a question like "When should you run your database on Kubernetes?" It's a "When should you not do it?"
That said, whenever you run your stateful workloads in Kubernetes, they deserve the best speed possible, especially with disk. Many claim that the overhead will kill performance, but it's just not true. The thin containerization layer, introduced through Linux namespaces and cgroups, has barely any overhead, meaning your services can act at full steam. Hence, any performance you provide underneath Kubernetes will be available to your pods. CPU, memory, network, disk, it's true for all of them. The blog post has links to the necessary proof. That's why you should provide the best storage possible, NVMe.
The only exception is cold, long-term storage. Feel free to tier these data to HDDs, object storage (or blob storage) for that kind of stuff (btw @simplyblock_io can do this fully transparent 😁).
Anyhow, as long your requirements don't call for "slow storage," go with what makes the most sense: NVMe-based storage solutions.
If you need more background or proof, here's the full blog post 🔥
https://t.co/y6rVPRDS79
PS: No matter if you are looking for storage of local disk-like speed, hyperconverged, disaggregated (or co-located), or a mixture of all of them, simplyblock has got you covered. If you want to know more, just let me know 💪