🎓Still thinking about applying to the #CVPR2026 Doctoral Consortium?
The submission deadline is April 13, 2026.
If you are a PhD student nearing graduation, this is a great opportunity to network, receive mentorship, and present your work at CVPR.
https://t.co/PBIpnznVt2
🚨New paper on AI & Copyright
👨⚖️Courts have credited LLM companies' claims that safety alignment prevents reproduction of copyrighted expression.
But what if fine-tuning on a simple writing task ruins it all?
Worse : Fine-tuning on a single author's books (e.g., Murakami) unlocks verbatim recall of copyrighted books from 30+ unrelated authors, sometimes as high as 90%.
Joint work with @niloofar_mire (@LTIatCMU), Jane Ginsburg ( @ColumbiaLaw) and my amazing PhD student @irisiris_l (@sbucompsc )
(1/n)🧵
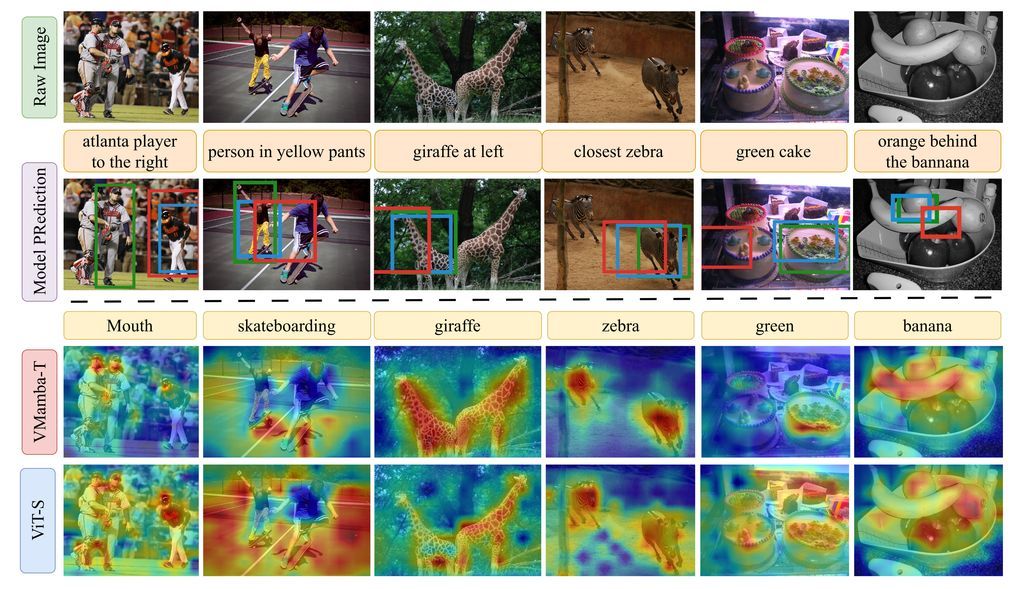
Do VLMs Need Vision Transformers?
A controlled study of Transformer, state space, and hybrid vision backbones for frozen vision-language models.
Finding:
- Under matched settings, VMamba improves localization while staying competitive on open-ended VQA, making SSMs a practical alternative to ViTs.
- Detection or segmentation pretraining generally improves VQA and localization, with the largest gains appearing in backbones that need more spatial inductive bias.
- Better classification scores and naive scaling do not consistently predict stronger downstream VLM behavior, especially for grounding-sensitive tasks.
- Some dense-objective checkpoints fail sharply in localization, but simple interface and connector adjustments recover much more robust behavior.
Paper Title: Do VLMs Need Vision Transformers? Evaluating State Space Models as
Project: https://t.co/v5SFOUpBXP
Link: https://t.co/gBdmP8kF4e
@dhillon_p and my work is in the @NewYorker today. Words can’t describe how I feel. Many thanks to Vauhini Vara for this beautiful and thought provoking essay.
If you care about AI disclosures, Fair Use & the Future of Creative Labor I recommend reading it :)
🚨New paper on AI and copyright
Several authors have sued LLM companies for allegedly using their books without permission for model training.
👩⚖️Courts, however, require empirical evidence of harm (e.g., market dilution). Our new pre-registered study addresses exactly this gap.
Joint work with Profs @dhillon_p (@umsi) & Jane Ginsburg ( @ColumbiaLaw)
(1/n)🧵
Privacy protection is vital — but blanket masking can cripple model performance.
Our COLM 2025 paper introduces FiG-Priv, a fine-grained privacy protection framework that masks only high-risk content, keeping useful details for blind & low-vision users.
📄 https://t.co/V3A41hEi2g
Thanks @arankomatsuzaki, @ManuelFaysse, and @_akhaliq for reposting our work! We extended matryoshka to multi-vector embedding and were glad to see that the popular concept, test-time scaling in LLM, also works in retrieval.
Work done with @AIatMeta & @vislang!
Honored to get the outstanding position paper award at @icmlconf :) Come attend my talk and poster tomorrow on human centered considerations for a safer and better future of work
I will be recruiting PhD students at @stonybrooku@sbucompsc coming fall. Please get in touch.
#ICCV2025 is deeply committed to promoting diversity, equity, and inclusion within our community. As part of this commitment, travel support is available to help broaden participation.
Applications will be reviewed on a rolling basis until August 20, 2025 (anywhere on Earth).
Beyond Blanket Masking: Examining Granularity for Privacy Protection in Images Captured by Blind and Low Vision Users -now accepted to #COLM
Last June, Jeffri Murrugarra presented a short version at LXAI and VizWiz Workshops @ CVPR'25
More info soon; see you all in Montreal!✨
We introduce a multi-agent collaboration system that produces fine-grained information and privacy risk scores to enable usability and utility while preserving privacy.
Kudos to all amazing collaborators: Haoran Niu, Suzanne Barber, @haldaume3, @Triiiiiista!