🙌 Excited to share our new paper and my first project in my PhD journey!
We show finetuning on a writing task unlocks verbatim recall of copyrighted books from authors not in the finetuning data.
It’s been an incredible experience working with such an amazing group of people ✨
🚨New paper on AI & Copyright
👨⚖️Courts have credited LLM companies' claims that safety alignment prevents reproduction of copyrighted expression.
But what if fine-tuning on a simple writing task ruins it all?
Worse : Fine-tuning on a single author's books (e.g., Murakami) unlocks verbatim recall of copyrighted books from 30+ unrelated authors, sometimes as high as 90%.
Joint work with @niloofar_mire (@LTIatCMU), Jane Ginsburg ( @ColumbiaLaw) and my amazing PhD student @irisiris_l (@sbucompsc )
(1/n)🧵
post-trained models are more helpful, but collapse toward a narrow range of possible answers
🍎 with ReDiPO, we show how to recover the lost diversity with a simple DPO data pipeline, while largely preserving instruction-following and safety
great work led by @vsamuel2003 !
Super excited to finally share Dynamic Workflows in Claude Code!!
We built this a couple months ago, and it has slowly become a daily driver for a bunch of people at Anthropic. A few tips for getting the most out of it 🧵
https://t.co/WtwkSd3JPp
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO + SOUL.
Paper: https://t.co/G0cEHr53h0
Code: https://t.co/6osJizwUDi
Model: https://t.co/yIAvpbKPSd
Ran some 🧪 with @irisiris_l to 🔬 why the Granta story was certainly 🤖 slop
A lot of bad writing happens coz AI hasn’t learned aesthetics. It has memorized the whole internet and called it a day.
So sure, maybe you don't trust AI detectors. But you can trust your own 👁️.
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
Do the circuits we extract to explain a model's behavior actually tell us how it solves a specific task? In new work w/ @nsubramani23, we find that circuits fail a basic check: ablating one task's circuit hurts another task about as much as ablating that task's own circuit. 🧵
Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
Copying → morphology/translation → basic arithmetic → complex reasoning & math. Across every model family we tested, LLMs acquire skills in roughly the same order during pretraining.
Can we use this to predict what a model will learn next, just from its internals? 🧵
We are offering grants of $100,000 + Tinker credits to researchers advancing the field of human-AI interactivity. Submit your proposals by June 19th!
https://t.co/907HfBy7g3
Does mechanistic interpretability really find the circuit?
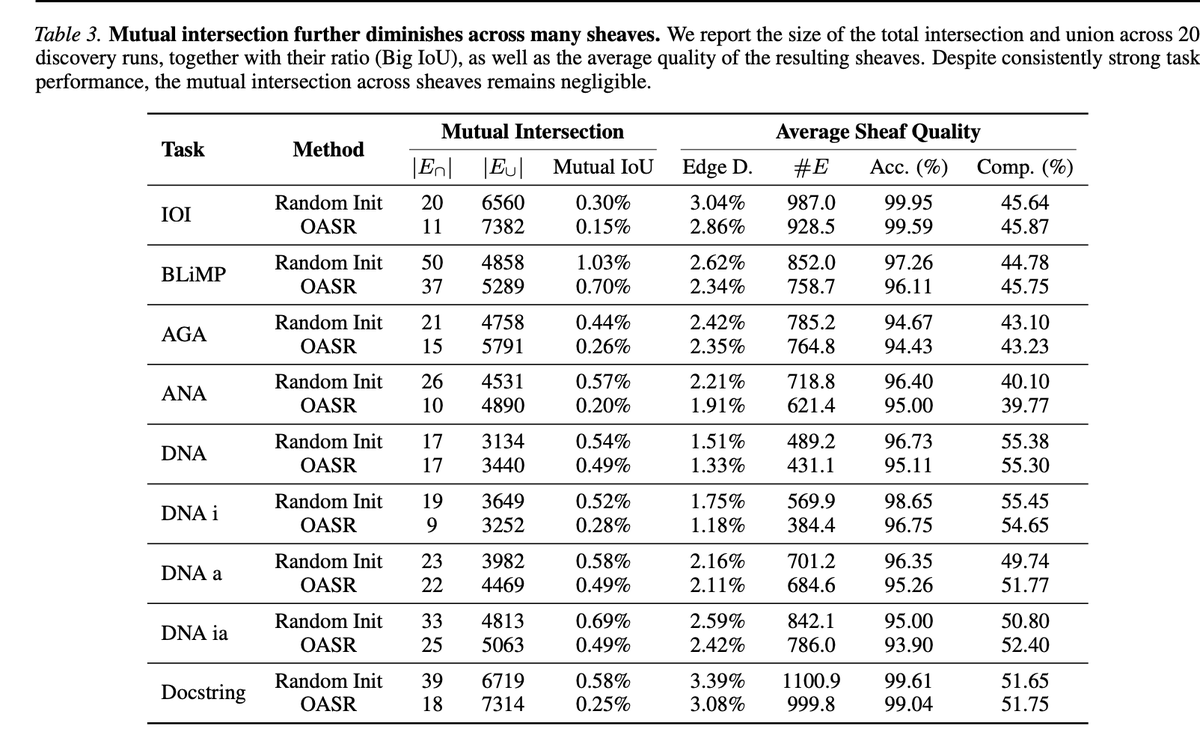
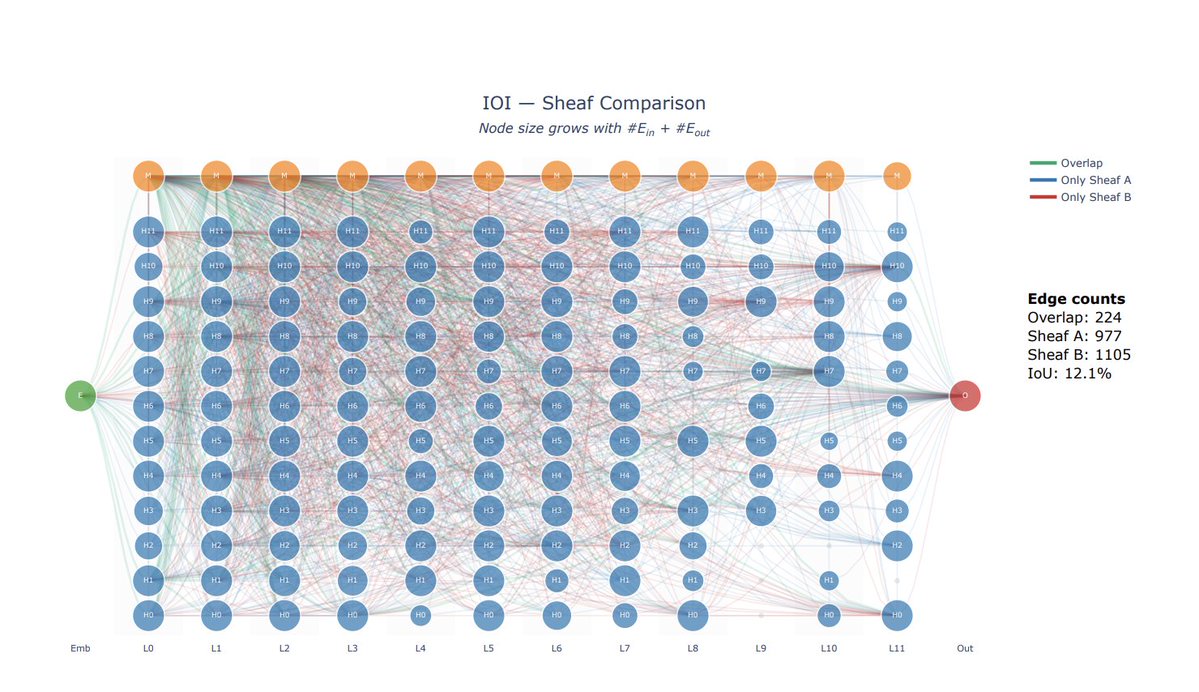
Our new paper, "All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs," (Accepted by ICML 2026) suggests the answer may be: not always.
A common implicit assumption in mechanistic interpretability is that a model's behavior is explained by the circuit — a sparse, canonical, almost-unique mechanism.
Instead, for the same LLM task, we find multiple circuits/sheaves that are:
✅ faithful
✅ sparse
✅ structurally different
✅ low-overlap
This means a discovered circuit may not be the unique mechanism behind a behavior, but one realization among many possible mechanisms. We call for rethinking how circuit/sheaf discovery results should be interpreted and evaluated.
Huge thanks to my amazing collaborators: @frankniujc, @YutongYin774638, and @zhaoran_wang
Paper: https://t.co/J5zO36Mr7m
#MechanisticInterpretability #LLM #AI #MachineLearning
LLMs refuse ambiguous queries that look harmful but aren't. Can they recover once users clarify, while staying safe? Our new interactive multi-turn benchmark measures both.
🚨 Turns out: not both at once.
https://t.co/DtgLpWpmJc
Very happy that Alignment Whack-a-Mole is one of the Top Papers on AI in Law Q1 2026 in @SSRN. Congrats to my student @irisiris_l who is busy preparing for her final exams :)
"Five major publishers — Hachette, Macmillan, McGraw Hill, Elsevier and Cengage — and the best-selling novelist Scott Turow have filed a class-action copyright infringement lawsuit against Meta and its founder and chief executive, Mark Zuckerberg." https://t.co/kzcGcFziKB
New episode of the AM podcast dropping soon!
In EP4, we sat down with @kenziyuliu, CS PhD student at @StanfordAILab and creator of The Open Anonymity Project, to talk about the privacy layer of personal intelligence.
Here's a preview 😃
Big Update🤩: #paperclip now includes full papers from all of arXiv, PubMed Central and 150 million abstracts!🖇️
You can give your LLM all that knowledge in one line—all optimally indexed for AI agents. Much more thorough and ~100x faster than web search, and free.