@karpathy Fourth paradigm to come be the galactic mothership brain all good scifi comes equiped with. My favorite is not Karl, but the one from the anime Ulysse 31 !
@antirez@mervenoyann Fine-tuning and specialization is the path nature went with species and learnable skills, it's by far not stupid, and can't be immediately superseded, especially for real time response and control. The battle on frontier model may well be a rat race, hard to tell.
@kamilkazani Yes , it also makes your own behavior, and that of others, more predictable, which makes the expected value estimate better. Sound and naturally strategy.
@antirez They are going for service, with teams of 'forward deployed engineers'. Sacrificing speed and compute for sovereign contracts and business customers. Cheaper, safer and more adapted to Europe financial landscape.
🚨 La Commission Européenne semble s'être prononcée *contre* le décret français interdisant les appellations type 'steak végétal'.
Après plusieurs semaines d'enquête, j'ai enfin réussi à trouver des informations que la Commission Européenne et le Ministère refusent de donner.⬇️
@lexfridman Hi Lex, one of the most renowned experts here in France and certainly worldwide is Henry Laurens https://t.co/rNj5sUUbZH
He is at College de France since 2003 https://t.co/qilk4YS4lu
His deepness, carefulness and erudition are unmatched.
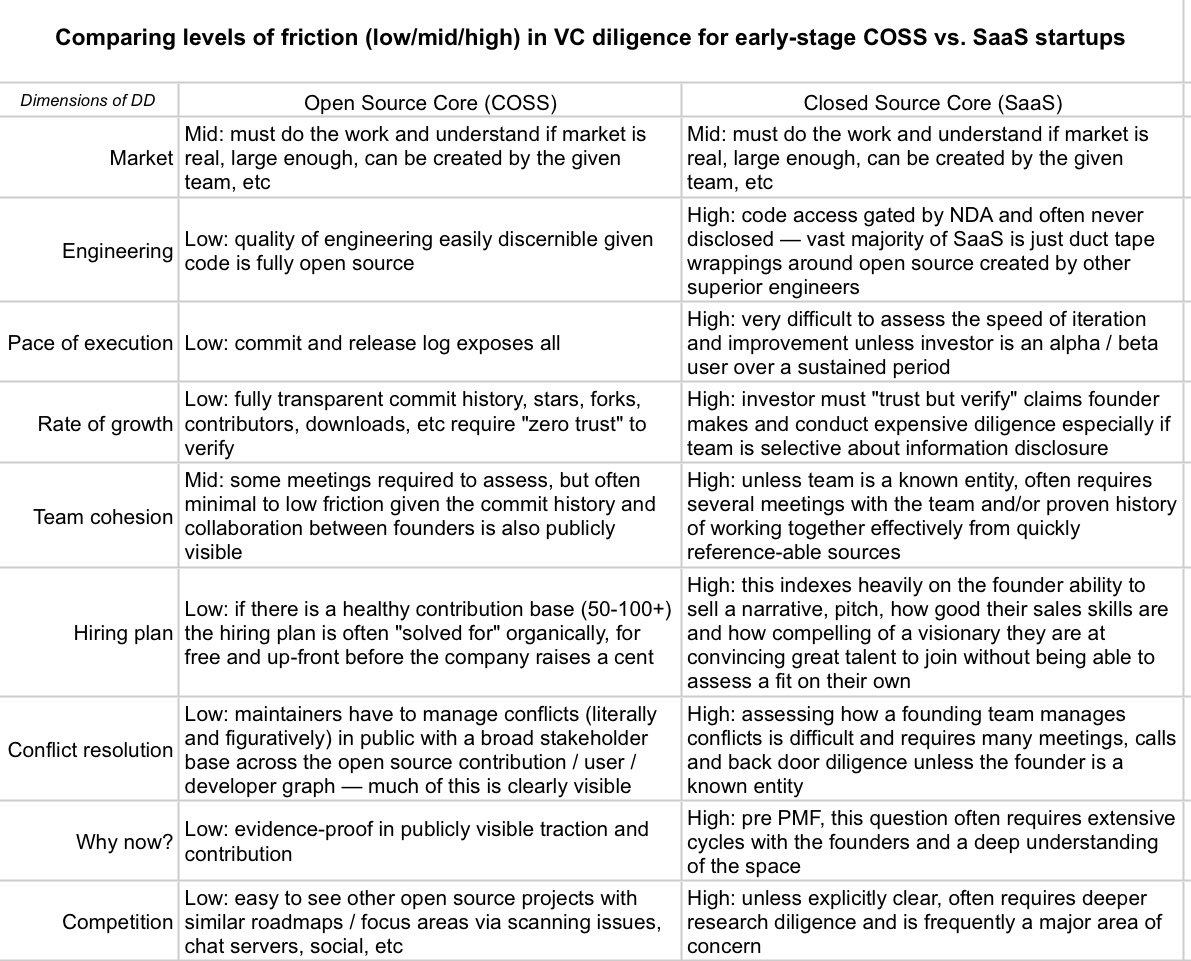
Getting an early-stage VC “to conviction” as a startup founder is all about lowering friction… but there are many fundamental differences on a bunch of dimensions that founders of open source startups (COSS) vs. closed source startups (SaaS) must face. Here’s what I mean:
@ylecun Bonjour Yann, un intérêt d intervenir a la conférence Open Source Expérience a Paris au palais des congres (en décembre, la semaine avant Neurips) ? Je les aide pour organiser le track AI/Data.
Histoire de continuer de ramener les esprits sur terre :)
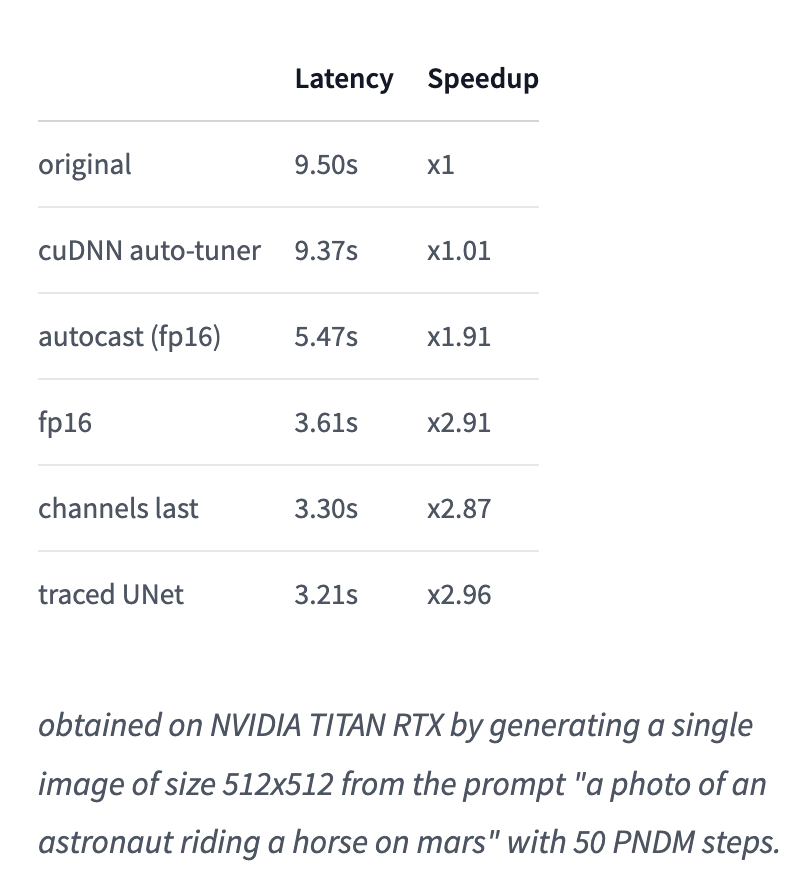
Stable Diffusion in the diffusers library became x3 times faster thanks to a set of optimizations tips, some of which require minimal code changes, making it the fastest implementation of Stable Diffusion (afaik)! What are these optimizations?
A thread 🧵 (1/n)
At #ICML today: why is generalization so hard in value-based RL? We show that the TD targets used in value-based RL evolve in a structured way, and that this encourages neural networks to ‘memorize’ the value function.
📺 https://t.co/fvvYvFZ7P5
📜 https://t.co/Y7ZurcuI2O
The Theseus library for PyTorch allows one to insert modules that perform an optimization to compute their output, and to back-propagate gradients through it.
From @MetaAI
1/Is scale all you need for AGI?(unlikely).But our new paper "Beyond neural scaling laws:beating power law scaling via data pruning" shows how to achieve much superior exponential decay of error with dataset size rather than slow power law neural scaling https://t.co/Vn62UJXGTd
@ylecun Hilarante et très juste courte BD de SF avec robots et deep learning qui font ce qu'ils peuvent pour ne pas décevoir les humains, dans le @_MetalHurlant de cet été :) par @aimeedejongh
For 2022, I'm doing Space Helmet Reflection Saturday! Every Saturday, I'll post a retro sci-fi illustration featuring a scene reflected through the visor of a spacesuit.
First up is one of the most beautiful examples, this NASA space settlement concept art by Rick Guidice.