Tokens != intelligence
The perceived cost of intelligence can be misleading.
A model might require longer or more complex prompts, or more loops, to produce the same-quality output as another model. Intelligence is the quality of the response, not just raw token cost.
Tokenizer efficiency also matters.
Claude's tokenizer produces approximately 16% more tokens than GPT-4o for the same input. That varies by domain: for mathematical equations the overhead is about 21%, and for Python code Claude generates roughly 30% more tokens.
When comparing models on real tasks :-
While a model like GPT-5 may have a cheaper per-token price than Sonnet-4, an agent using GPT-5 might consume far more tokens and require more turns to get a good result, negating the cost savings.
The ultimate cost combines token price, total tokens used, and the number of turns required to complete a task.
How long can we afford to trust Github as reliable?
Today I was fixing a production issue and when I tried pushing code, it gave me a "Permission denied (publickey)" error. The default assumption is that my public key is not added while I pushed something else successfully this morning.
I ran ssh -T [email protected] and it authenticated successfully. This was super confusing.
Upon verbose logging, I found that the connection was timing out with their ssh server.
This transient failure at Github's ssh endpoint caused me a delay of 15 mins in order to deploy an urgent fix to production. Even the error was very misleading. This is definitely not expected from Github.
Some of these downtimes don't even appear on their status page unless it's a big global outage. This is not a one-off incident, Github is experiencing repeated failures lately. This raises a question - should we even rely on Github anymore while it becomes a single point of failure for the entire CI/CD pipeline?
Testing agents is difficult. An agent is not deterministic with predictable inputs and outputs given an environment. It decide it's actions in loop governed by an LLM and the output it produces is not directly verifiable.
It requires something that is verifiable for an agent in order to be testable.
The framing that helps me most is bounded context pattern, borrowed from DDD(domain driven design). The idea is that a large system is broken into separate pieces with explicit boundaries between them.
We can convert an agentic system into a bounded context. In order to test it, I define four levels of tests for an agent, and each level is an absraction built on confidence of the previous level.
1. Unit test
2. Integration test
3. Spec test
4. Use case test
A unit test checks one piece of logic in smallest isolation. A simple example is to test if API key is empty it returns blank api key error. These tests test most granular components and most business logic. They are fast and cheap, so we can run them after every change.
An integration test checks the integration between two boundaries. A simplest example is a database round trip. I save a reminder to a real postgres database, then read reminders back, and check the one I saved is there. If the code that writes and the code that reads disagree about the schema, a unit test on either side would still pass, but the integration test fails immediately.
I use testcontainers to simulate real postgres with schema migration and seed data to define a state. This integration test tests for the given state how would application logic executes.
A spec test checks a single workflow from the user's point of view. It's the boundary between the user and the whole agentic application. For example this is how I test the email search flow. I seed the email store with one email from Alice. I run the agent with "did I receive any email from alice today". The agent finds the email and writes a summary. The test passes if that summary matches what the email actually said. A unit test can't catch a bug here because the retrieval code works fine. An integration test can't catch it because the email really is in the store. Only a spec test sees whether the agent actually understood the email.
Asserting on spec tests is the hardest part because it touches real LLM calls. The LLMs are non deterministic. I check two things. First, did the right tool get called? I record the tool calls the agent made and compare them to what I expect. Second, does the summary actually match the email? For that I employ an LLM as judge. The judge reads the original email and the agent's summary and returns a pass or fail. This way the whole flow runs end to end with real LLM calls and simulated user actions, and the final answer is validated by a binary classification from the judge.
Finally, A use case test runs one full use case in a given domain end to end. It touches multiple spec workflows. Email use case is one example where agent can read email, prioritize them and reply to an email on user's behalf. A spec test checks that the agent's draft mentions the right person and topic. A use case test runs the full path receiving email from the client, informing user about the email, drafting a reply, asking for user approval, and the sending the email after the approval.
We do this by simulating the entire external tooling that is user specific. Ex. the send email call goes through the email tool layer into a dry-run sink so that nothing actually leaves the machine and no real email is sent. The test then reads the sink and asserts the recipient was [email protected] and the body mentions the budget meeting.
Overall, a unit test catches bugs in the core logic. An integration test catches bugs at the boundary. A spec test catches bugs if our agentic loop breaks. A use case test makes sure that a user will be able to use the agent for intended use case with all the wiring in place.
- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
It’s surprising to me how many people are convinced “outcome-based pricing” is the future for all AI products.
Most AI systems I’ve seen allow a finite action space for their agents, and optimize for predictable behaviour. Not just the system, even the LLMs are RL’ed to produce predictable behavior.
Writing is the best form of thinking.
If I am not writing, I am not thinking, and it becomes very shallow.
A lot of times, I get so much clarity on my ideas just while I am writing them down.
Git was designed for humans collaborating with humans. Deliberate commits, reviewable diffs, async pull requests.
This worked for last 20+ years because the code changes was fundamentally human driven.
Now, coding agents don't work that way. They generate code 10 to 100x faster than a human, create branches constantly, fill merge queues, and most of the actual reasoning that produced the code lives in a prompt somewhere, completely invisible to the repository.
The commit history only tells you what changed. It has no idea why, or what the agent tried before getting there.
The deeper problem is that the collaboration layer built on top of Git was designed around trust and friction as a feature.
A PR was a social contract between people on diffs. Opening one meant you had thought about it. Now that contract is being flooded with noise, and the tooling has no way to distinguish a thoughtful contribution from something an agent spat out in three seconds.
Version control needs to track intent, reasoning, and agent state, not just file diffs.
jj is making good progress in this direction while taking more granular diffs, I hope we have this sooner.
@daniel_mac8 What about software engineering jobs? There is a difference between software engineers and software engineering jobs.
As technology as evolved cooking has become easy and almost everyone cooks but that doesn’t mean we have a lot of jobs for chefs.
For the first time in five generations of Apple Silicon, these chips are not a single piece of silicon. Apple does Fusion now with new chips.
I think Fusion Architecture is the real story. Not because of what M5 Pro and M5 Max can do today. Because of what it opens up.
Once you’ve proven you can split the chip and keep unified memory working across the pieces, the question changes. It is no longer ‘how big can we make this chip?’
It is ‘how many pieces can we connect, and in how many dimensions?’
https://t.co/5QyNSYqtso
@mitsuhiko I advocate the use of any open-source ones(VoiceInk/Handy), but I use WisprFlow for the sole reason that it does very well with my mixed accent.
Letting a provider see all your data is the price of admission for AI. We're changing that.
Introducing Silo, the first private post-training and inference stack for frontier models, with hardware-level guarantees that we can’t see your data.
Privacy without compromises. 🧵
A sufficiently detailed spec is code.
On one hand: yes, this is so true with coding agents, if you want to specify everything a piece of software is supposed to do, you might as well write the code.
On the other: it also feels like you can specify what software is supposed to do without being 100% precise and, as long as the person (thing) implementing it and you have some shared understanding about what’s left out of the spec, things will be fine.
Question is how much shared understanding there is and I think that’s where a lot of people have the wrong estimates.
Git was designed for humans collaborating with humans. Deliberate commits, reviewable diffs, async pull requests.
This worked for last 20+ years because the code changes was fundamentally human driven.
Now, coding agents don't work that way. They generate code 10 to 100x faster than a human, create branches constantly, fill merge queues, and most of the actual reasoning that produced the code lives in a prompt somewhere, completely invisible to the repository.
The commit history only tells you what changed. It has no idea why, or what the agent tried before getting there.
The deeper problem is that the collaboration layer built on top of Git was designed around trust and friction as a feature.
A PR was a social contract between people on diffs. Opening one meant you had thought about it. Now that contract is being flooded with noise, and the tooling has no way to distinguish a thoughtful contribution from something an agent spat out in three seconds.
Version control needs to track intent, reasoning, and agent state, not just file diffs.
jj is making good progress in this direction while taking more granular diffs, I hope we have this sooner.
My painful learning from building a presentation using Claude Code.
Yesterday, I was preparing the presentation for my talk at the AI meetup in Da Nang.
I used Claude Code to create a presentation, and initially, it was a disaster. Every iteration, it was creating something that I didn’t want, but slowly, I started understanding a pattern, and I built it like a flow.
This experience of building a presentation made me think if I can build a small agent skill for this, it will be so much easier to create beautiful presentations with coding agents.
So I built it, now I installed it as a skill, and next time I ask Claude Code to create a presentation, it can just load this skill, and we get to create a cool presentation.
https://t.co/FGGnkIDfg8
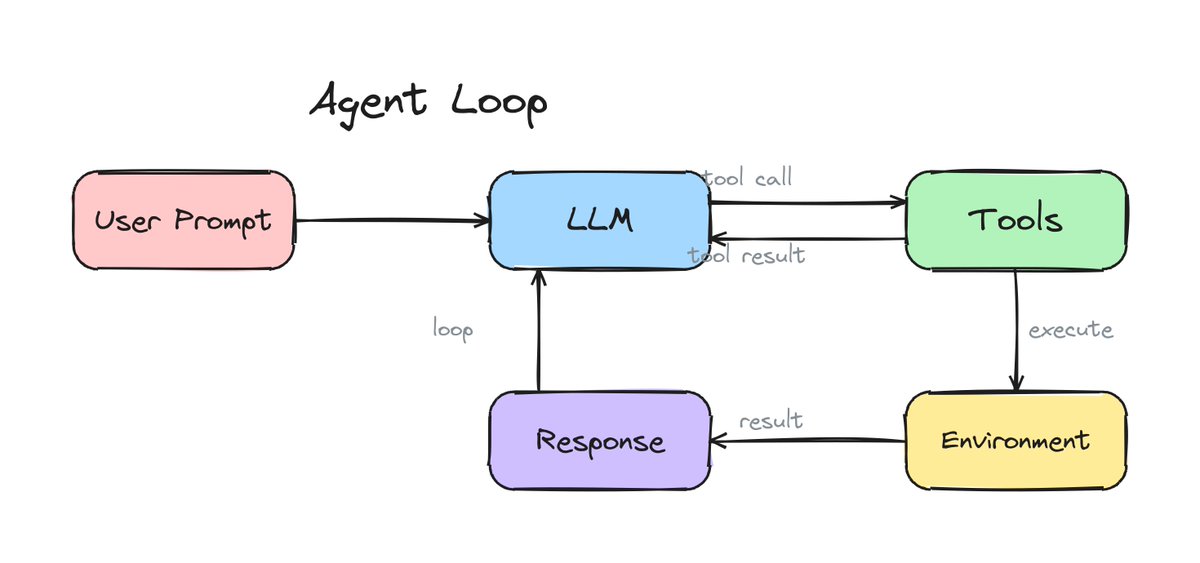
built skrawl, a cli tool that lets your coding agent generate hand-drawn excalidraw diagrams without a browser.
Just give claude code the skill and just ask things like "draw a simple agent loop diagram" and it spits out a real png or svg using excalidraw's aesthetic and font.
code at https://t.co/bue33969gr
This is how 81,000 people are using AI, real stories!!
Anthropic put out a really cool report yesterday. They talked to 81k Claude users across many countries and just asked them straight up, what's AI actually doing in your life.
This honestly some of these stories are really good.
A mute person in Ukraine built a text-to-speech bot with Claude and can now talk to friends in near real time.
A healthcare worker in the US says she finally has patience for her nurses because AI handles all the documentation.
This data is gold and can help others figure out better use cases.
I went ahead and extracted quotes and put together into a dataset if anyone wants to play with it.
https://t.co/OIW4Z568mG
This is how 81,000 people are using AI, real stories!!
Anthropic put out a really cool report yesterday. They talked to 81k Claude users across many countries and just asked them straight up, what's AI actually doing in your life.
This honestly some of these stories are really good.
A mute person in Ukraine built a text-to-speech bot with Claude and can now talk to friends in near real time.
A healthcare worker in the US says she finally has patience for her nurses because AI handles all the documentation.
This data is gold and can help others figure out better use cases.
I went ahead and extracted quotes and put together into a dataset if anyone wants to play with it.
https://t.co/OIW4Z568mG
One thing that works for me the best right now in terms of code retrieval is:
1. Let the agent explore and find relevant files in a single context
2. compact the context with what you need(write to a file)
3. go back to an earlier point in the conversation, feeding only that summary back in with the file.
This way, we can save context and have quality retrieval in the context. Subagents don't work for me because they know what to look for, and it requires steering.