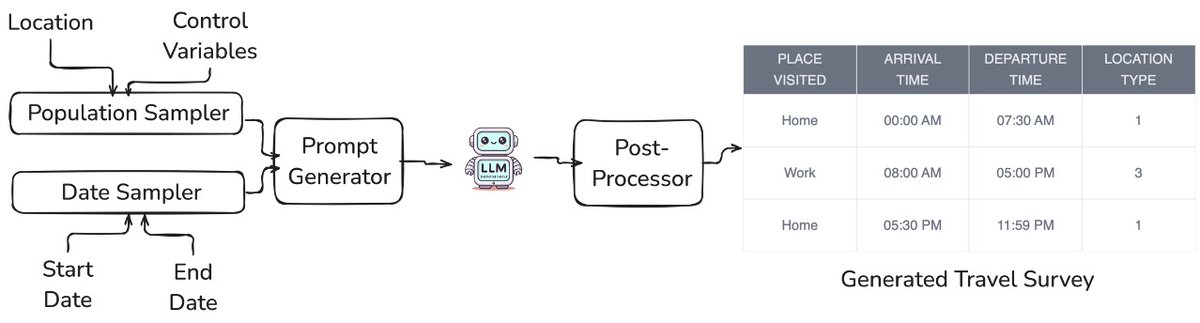
Travel survey data are vital for urban mobility assessments—but they’re often costly and difficult to collect.
Could LLMs help us synthesize such data?
Our latest work, in collaboration with @anas_ant and @dpfoser, and the Best Paper Winner🥇at #SIGSPATIAL24, shows they can! 🧵👇
Epidemiological data is crucial for public health, but extracting and geotagging it from documents is challenging. Our work to be presented at #EMNLP2024’s 3rd NLP4PI Workshop, “From Text to Maps: LLM-Driven Extraction and Geotagging of Epidemiological Data”, tackles this. 🧵
Travel survey data are vital for urban mobility assessments—but they’re often costly and difficult to collect.
Could LLMs help us synthesize such data?
Our latest work, in collaboration with @anas_ant and @dpfoser, and the Best Paper Winner🥇at #SIGSPATIAL24, shows they can! 🧵👇
One key insight?
Open source LLMs such as Llama-2, when trained even with a limited amount of actual travel data
(Llama-2-trained in the plot), can generate quality synthetic travel surveys to facilitate urban mobility assessment.
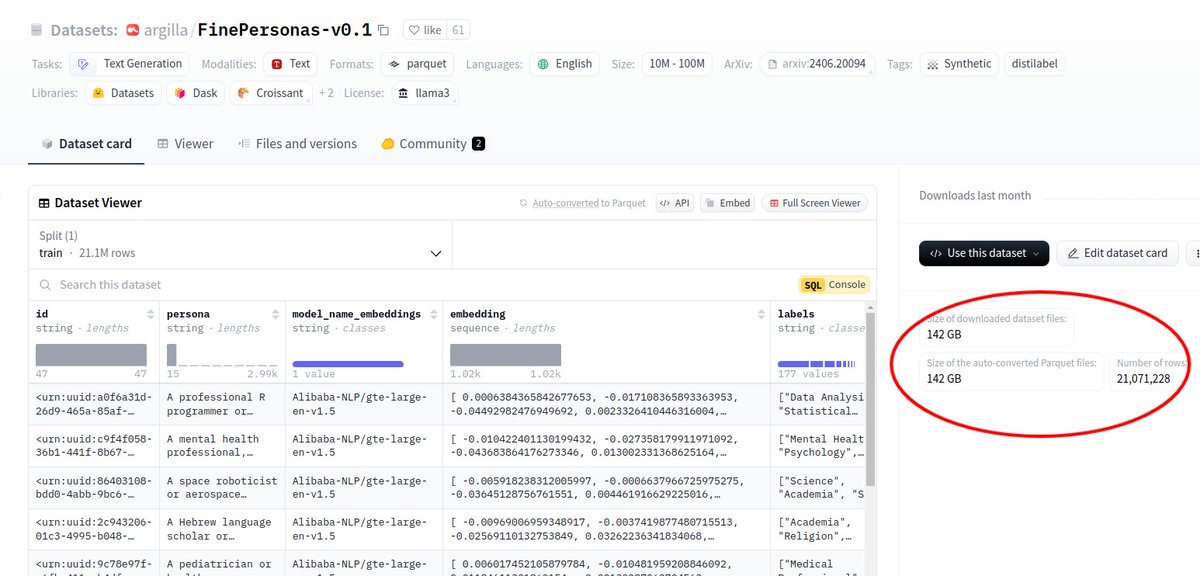
One of THE largest personas datasets dropped in @huggingface 🤯
21 Million rows and 142GB 🤯
FinePersonas contains detailed personas for creating customized, realistic synthetic data.
So now you can integrate unique persona traits into text generation apps.
-------
What's a Persona?
A persona is a detailed description of an individual’s characteristics, background, and goals, designed to reflect diverse identities and experiences. In the context of FinePersonas, each persona represents a unique set of attributes that can enrich synthetic data.
For example, a persona might describe:
A network engineer with a focus on routing protocols and preparing for Cisco certification exams, particularly CCNA.
@CBSSports please have unbiased commentators on your show. One of the commentators on Real Madrid VS Man city was completely biased and I know everyone watching it would know.
Today, with @Tim_Dettmers, @huggingface, & @mobius_labs, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming GPUs. 1/🧵
https://t.co/UAsWOLtn7a
The racism behind chatGPT that we aren't talking about...
This year, I learned that students use chatGPT because they believe it helps them sound more respectable. And I learned that it absolutely does not work. A thread. 🧵
To assess LLMs for geospatial reasoning, we devise an MDS-based experiment to predict a city’s location relative to other cities. Our findings indicate that the model’s performance is within an order of magnitude of what MDS could predict if we had access to actual distance.
Are large language models geospatially knowledgeable?
Our SIGSPATIAL paper examines the extent of geospatial knowledge encoded in LLMs, as well as their geospatial awareness and application in reasoning tasks related to geospatial data.
Paper: https://t.co/PEtqIRPmsy
We also prompt for geospatial “awareness”, the perception of space, using geospatial prepositions 'near,' 'close to,' and 'far from,' along with the control word 'and'.
LLMs demonstrate an understanding of what “near” or “far” means.
See maps visualizing the responses.