I valued SpaceX for its IPO a few weeks ago, with minimal information and a promise to revisit the valuation, when the prospectus was made public. The prospectus is public, the offering price has been set and my update is up and running. https://t.co/zRjpD1C0wv
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
The Next Two Years of Software Engineering https://t.co/uIJSBJdzVa < these are five crazy-relevant questions to ask of yourself and your team. @addyosmani then offers strong recommendations to consider.
.@satyanadella gave me and @dylan522p an exclusive tour of Fairwater 2, the most powerful AI datacenter in the world.
We then chatted through Satya's vision for Microsoft in a world with AGI.
0:00:00 - Fairwater 2
0:04:15 - Business models for AGI
0:13:42 - Copilot
0:20:56 - Whose margins will expand most?
0:37:12 - MAI
0:48:42 - The hyperscale business
1:03:39 - In-house chip & OpenAI partnership
1:10:30 - The CAPEX explosion
1:16:01 - Will the world trust US companies to lead AI?
Look up Dwarkesh Podcast on Youtube, Apple Podcasts or Spotify to tune in.
A Survey of Context Engineering
160+ pages covering the most important research around context engineering for LLMs.
This is a must-read!
Here are my notes:
Announcing NVIDIA Project DIGITS, a personal AI supercomputer that’s powered by the NVIDIA GB10 Superchip and based on #NVIDIAGraceBlackwell architecture. https://t.co/zY09rRrY0X
Preconfigured with the NVIDIA AI software stack, developers, researchers, data scientists and students can prototype, fine-tune and inference large AI models on their desktop and deploy them to the data center or cloud. #CES2025
🙏✨ A Year-Long Journey—Now Complete ✨🙏
After 1 year of devotion, I’m humbled to share 5 hours and 44 minutes of Sivavakkiyar’s divine verses. Hearing “ஓடி ஓடி / ஓம் நமசிவாய” in temples feels truly blessed. 🌸
This is more than music—it’s a prayer, a tribute to Lord Shiva. I hope it brings you peace and divine energy. 🔱✨
“நமசிவாய அஞ்செழுத்தும் நிற்குமே நிலைகளே”
🎧 Listen & feel the divine:
👉 https://t.co/2pEDhOgAcx
@GhibranVaibodha@GoldDevaraj@ThinkDivineOff #OdiOdi #OmNamahShivayaOm
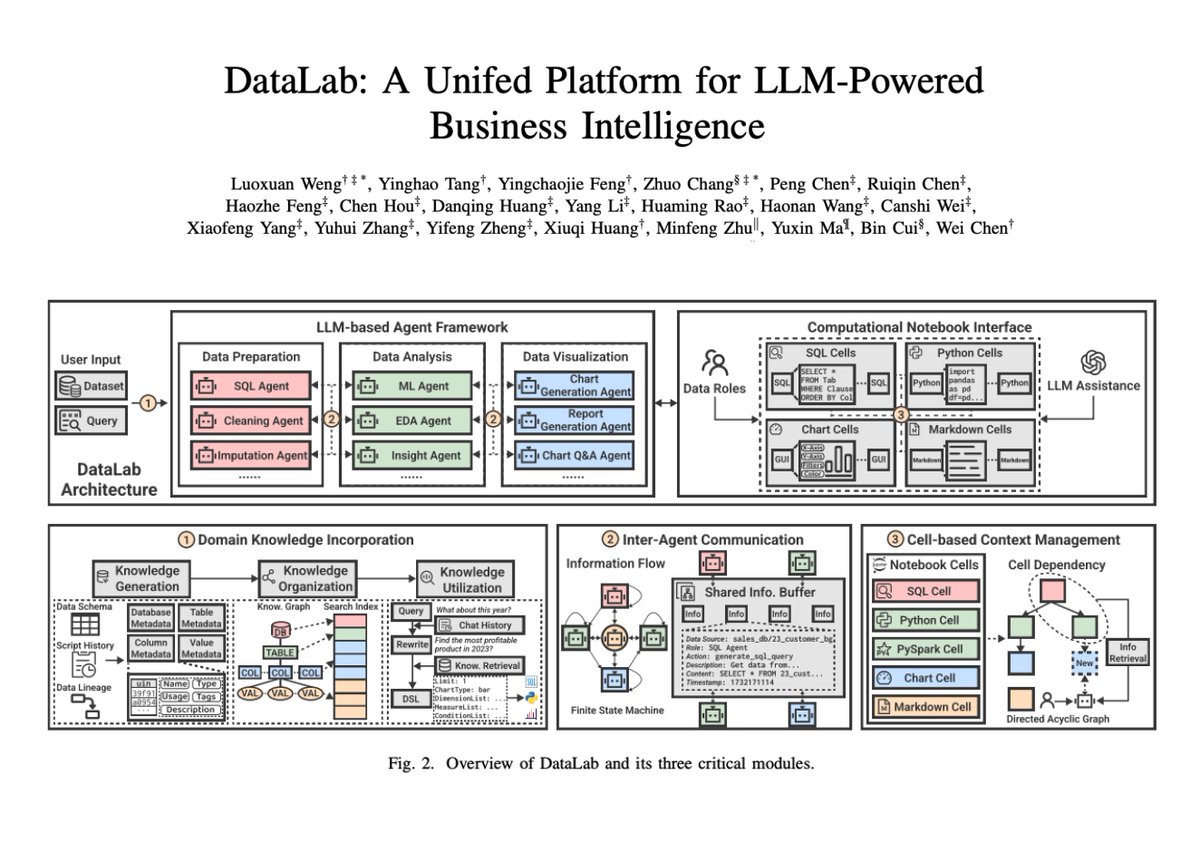
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Introduces DataLab, a unified BI platform that integrates an LLM-based agent framework with an augmented computational notebook interface.
DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks.
It also achieves up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
Reverse Thinking Makes LLMs Stronger Reasoners
Shows that training LLMs to learn "reverse thinking" helps to improve performance in commonsense, math, and logical reasoning tasks.
It claims to outperform a standard fine-tuning method trained on 10x more forward reasoning.
Introducing the Model Context Protocol (MCP)
An open standard we've been working on at Anthropic that solves a core challenge with LLM apps - connecting them to your data.
No more building custom integrations for every data source. MCP provides one protocol to connect them all:
SQL injection-like attack on LLMs with special tokens
The decision by LLM tokenizers to parse special tokens in the input string (<s>, <|endoftext|>, etc.), while convenient looking, leads to footguns at best and LLM security vulnerabilities at worst, equivalent to SQL injection attacks.
!!! User input strings are untrusted data !!!
In SQL injection you can pwn bad code with e.g. the DROP TABLE attack. In LLMs we'll get the same issue, where bad code (very easy to mess up with current Tokenizer APIs and their defaults) will parse input string's special token descriptors as actual special tokens, mess up the input representations and drive the LLM out of distribution of chat templates.
Example with the current huggingface Llama 3 tokenizer defaults:
Two unintuitive things are happening at the same time:
1. The <|begin_of_text|> token (128000) was added to the front of the sequence.
2. The <|end_of_text|> token (128001) was parsed out of our string and the special token was inserted. Our text (which could have come from a user) is now possibly messing with the token protocol and taking the LLM out of distribution with undefined outcomes.
I recommend always tokenizing with two additional flags, disabling (1) with add_special_tokens=False and (2) with split_special_tokens=True, and adding the special tokens yourself in code. Both of these options are I think a bit confusingly named. For the chat model, I think you can also use the Chat Templates apply_chat_template.
With this we get something that looks more correct, and we see that <|end_of_text|> is now treated as any other string sequence, and is broken up by the underlying BPE tokenizer as any other string would be:
TLDR imo calls to encode/decode should never handle special tokens by parsing strings, I would deprecate this functionality entirely and forever. These should only be added explicitly and programmatically by separate code paths. In tiktoken, e.g. always use encode_ordinary. In huggingface, be safer with the flags above. At the very least, be aware of the issue and always visualize your tokens and test your code. I feel like this stuff is so subtle and poorly documented that I'd expect somewhere around 50% of the code out there to have bugs related to this issue right now.
Even ChatGPT does something weird here. At best it just deletes the tokens, at worst this is confusing the LLM in an undefined way, I don't really know happens under the hood, but ChatGPT can't repeat the string "<|endoftext|>" back to me:
Be careful out there.
SUPPORT OF #Astikas SOLICITED! Kindly share this post(er) with your friends & relatives! #Astikas in the US of A, GC Vedic (Priya & Narayanan) is presenting my tour in 2024. I will be delivering 31 discourses (30 in English, 1 in தமிழ்) in 30 days spread across #NewJersey, #Delaware, #Boston, #Pittsburgh, #Maryland and #Indianapolis. All are free discourses (open to ALL)!
Day 24 of llm.c: we now do multi-GPU training, in bfloat16, with flash attention, directly in ~3000 lines of C/CUDA, and it is FAST! 🚀
We're running ~7% faster than PyTorch nightly, with no asterisks, i.e. this baseline includes all modern & standard bells-and-whistles: mixed precision training, torch compile and flash attention, and manually padding vocab. (Previous comparisons included asterisks like *only inference, or *only fp32 etc.) Compared to the current PyTorch stable release 2.3.0, llm.c is actually ~46% faster. My point in these comparisons is just to say "llm.c is fast", not to cast any shade on PyTorch. It's really amazing that PyTorch trains this fast in a fully generic way, with ability to cook up and run ~arbitrary neural networks and run them on a ton of platforms. I see the goals and pros and cons of these two projects as different, even complementary. Actually I started llm.c with my upcoming education videos in mind, to explain what PyTorch does for you under the hood.
How we got here over the last ~1.5 weeks - added:
✅ mixed precision training (bfloat16)
✅ many kernel optimizations, including e.g. a FusedClassifier that (unlike current torch.compile) does not materialize the normalized logits.
✅ flash attention (right now from cudnn)
✅ Packed128 data structure that forces the A100 to utilize 128-bit load (LDG.128) and store (STS.128) instructions.
It's now also possible to train multi-GPU - added:
✅ First version of multi-gpu training with MPI+NCCL
✅ Profiling the full training run for NVIDIA Nsight Compute
✅ PR for stage 1 of ZeRO (optimizer state sharding) merging imminently
We're still at "only" 3,000 lines of code of C/CUDA. It's getting a bit less simple, but still bit better than ~3 million. We also split off the fp32 code base into its own file, which will be pure CUDA kernels only (no cublas or cudnn or etc), and which I think would make a really nice endpoint of a CUDA course. You start with the gpt2.c pure CPU implementation, and see how fast you can make it by the end of the course on GPU, with kernels only and no dependencies.
Our goal now is to create a reliable, clean, tested, minimal, hardened and sufficiently optimized LLM stack that reproduces the GPT-2 miniseries of all model sizes, from 124M to 1.6B, directly in C/CUDA.
A lot more detail on: "State of the Union [May 3, 2024]"
https://t.co/eDgbngHrZ9






































![karpathy's tweet photo. Day 24 of llm.c: we now do multi-GPU training, in bfloat16, with flash attention, directly in ~3000 lines of C/CUDA, and it is FAST! 🚀
We're running ~7% faster than PyTorch nightly, with no asterisks, i.e. this baseline includes all modern & standard bells-and-whistles: mixed precision training, torch compile and flash attention, and manually padding vocab. (Previous comparisons included asterisks like *only inference, or *only fp32 etc.) Compared to the current PyTorch stable release 2.3.0, llm.c is actually ~46% faster. My point in these comparisons is just to say "llm.c is fast", not to cast any shade on PyTorch. It's really amazing that PyTorch trains this fast in a fully generic way, with ability to cook up and run ~arbitrary neural networks and run them on a ton of platforms. I see the goals and pros and cons of these two projects as different, even complementary. Actually I started llm.c with my upcoming education videos in mind, to explain what PyTorch does for you under the hood.
How we got here over the last ~1.5 weeks - added:
✅ mixed precision training (bfloat16)
✅ many kernel optimizations, including e.g. a FusedClassifier that (unlike current torch.compile) does not materialize the normalized logits.
✅ flash attention (right now from cudnn)
✅ Packed128 data structure that forces the A100 to utilize 128-bit load (LDG.128) and store (STS.128) instructions.
It's now also possible to train multi-GPU - added:
✅ First version of multi-gpu training with MPI+NCCL
✅ Profiling the full training run for NVIDIA Nsight Compute
✅ PR for stage 1 of ZeRO (optimizer state sharding) merging imminently
We're still at "only" 3,000 lines of code of C/CUDA. It's getting a bit less simple, but still bit better than ~3 million. We also split off the fp32 code base into its own file, which will be pure CUDA kernels only (no cublas or cudnn or etc), and which I think would make a really nice endpoint of a CUDA course. You start with the gpt2.c pure CPU implementation, and see how fast you can make it by the end of the course on GPU, with kernels only and no dependencies.
Our goal now is to create a reliable, clean, tested, minimal, hardened and sufficiently optimized LLM stack that reproduces the GPT-2 miniseries of all model sizes, from 124M to 1.6B, directly in C/CUDA.
A lot more detail on: "State of the Union [May 3, 2024]"
https://t.co/eDgbngHrZ9](https://pbs.twimg.com/media/GMrANymbIAAktYm.png)




















