Introducing Chroma Context-1, a 20B parameter search agent.
> pushes the pareto frontier of agentic search
> order of magnitude faster
> order of magnitude cheaper
> Apache 2.0, open-source
Parallel agents are emerging as an important new direction for scaling up AI. AI capabilities have scaled with more training data, training-time compute, and test-time compute. Having multiple agents run in parallel is growing as a technique to further scale and improve performance.
We know from work at Baidu by my former team, and later OpenAI, that AI models’ performance scales predictably with the amount of data and training computation. Performance rises further with test-time compute such as in agentic workflows and in reasoning models that think, reflect, and iterate on an answer. But these methods take longer to produce output. Agents working in parallel offer another path to improve results, without making users wait.
Reasoning models generate tokens sequentially and can take a long time to run. Similarly, most agentic workflows are initially implemented in a sequential way. But as LLM prices per token continue to fall — thus making these techniques practical — and product teams want to deliver results to users faster, more and more agentic workflows are being parallelized.
Some examples:
- Many research agents now fetch multiple web pages and examine their texts in parallel to try to synthesize deeply thoughtful research reports more quickly.
- Some agentic coding frameworks allow users to orchestrate many agents working simultaneously on different parts of a code base. Our short course on Claude Code shows how to do this using git worktrees.
- A rapidly growing design pattern for agentic workflows is to have a compute-heavy agent work for minutes or longer to accomplish a task, while another agent monitors the first and gives brief updates to the user to keep them informed. From here, it’s a short hop to parallel agents that work in the background while the UI agent keeps users informed and perhaps also routes asynchronous user feedback to the other agents.
It is difficult for a human manager to take a complex task (like building a complex software application) and break it down into smaller tasks for human engineers to work on in parallel; scaling to huge numbers of engineers is especially challenging. Similarly, it is also challenging to decompose tasks for parallel agents to carry out. But the falling cost of LLM inference makes it worthwhile to use a lot more tokens, and using them in parallel allows this to be done without significantly increasing the user’s waiting time.
I am also encouraged by the growing body of research on parallel agents. For example, I enjoyed reading “CodeMonkeys: Scaling Test-Time Compute for Software Engineering” by Ryan Ehrlich and others, which shows how parallel code generation helps you to explore the solution space. The mixture-of-agents architecture by Junlin Wang is a surprisingly simple way to organize parallel agents: Have multiple LLMs come up with different answers, then have an aggregator LLM combine them into the final output.
There remains a lot of research as well as engineering to explore how best to leverage parallel agents, and I believe the number of agents that can work productively in parallel — like the humans who can work productively in parallel — will be very high.
[Original text, with links: https://t.co/ElcJZyzcfw ]
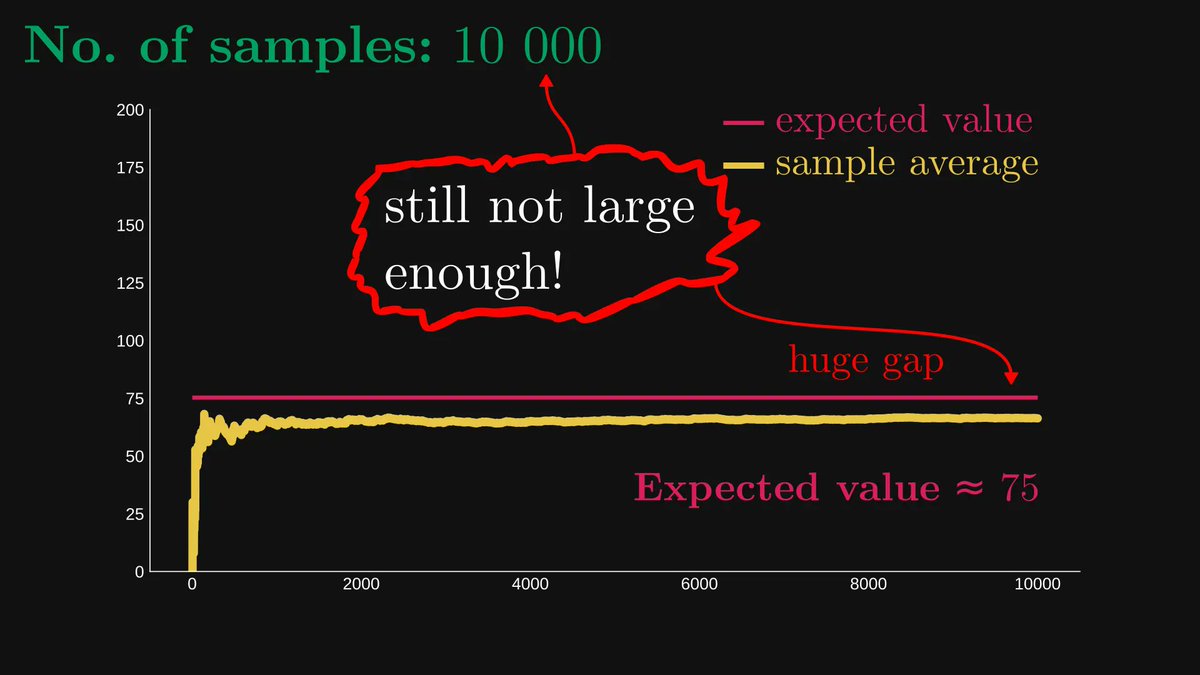
A question we never ask:
"How large is that number in the Law of Large Numbers?"
Sometimes, a thousand samples are large enough. Sometimes, even ten million samples fall short.
How do we know? I'll explain.
Je ne ne sais pas si nous avons été écoutés. On verra. Mais nous avons exprimé publiquement nos désaccords, et strictement personne ne nous l’a fait payer, même dans une toute petite mesure.
[5/x]
Lecture d'utilité publique.
Voilà pourquoi des étrangers en situation régulière (qui travaillent & vivent sereinement dans notre pays) finissent souvent dans l'irrégularité.
Au mépris de leurs droits & au détriment de l'intérêt de tous (sauf des responsables de ce chaos...)
This repository is absolute gold for all Data Science and Machine Learning practitioners!
Best ideas and solutions shared by top performers in the Kaggle competitions:
https://t.co/YXEVDNnmJ3
Another step closer to having AI write code better than humans!
The new release of AlphaCodium, an open-source state-of-the-art code generation tool, outperforms directly prompting OpenAI when generating code.
This is a huge deal. The research team @QodoAI tested this on the Codeforces Code Contest benchmark, and the leap is huge:
Using o1-preview
• Direct prompting: 55%
• AlphaCodium: 78%
Using o1-mini
• Direct prompting: 53%
• AlphaCodium: 74%
These results make AlphaCodium the best approach to generate code we've seen so far.
I'm linking to a blog post with more information, the paper, and the GitHub repository below, but here is a 30-second summary of how AlphaCodium works:
AlphaCodium relies on an iterative process that repeatedly runs and fixes the generated code using the testing data.
1. The first step is to have the model reason about the problem. They describe it using bullet points and focus on the goal, inputs, outputs, rules, constraints, and any other relevant details.
2. Then, they make the model reason about the public tests and come up with an explanation of why the input leads to that particular output.
3. The model generates two to three potential solutions in text and ranks them in terms of correctness, simplicity, and robustness.
4. Then, it generates more diverse tests for the problem, covering cases not part of the original public tests.
5. Iteratively, pick a solution, generate the code, and run it on a few test cases. If the tests fail, improve the code and repeat the process until the code passes every test.
There's a lot more information in the paper and the blog post. Here are the links:
• Blog: https://t.co/6VZYWMiBAj
• Paper: https://t.co/OFzeRGJwl7
• Code: https://t.co/rcGwx22ybk
I attached an image comparing AlphaCodium with direct prompting using different models.
Ma voisine a travaillé pendant 20 ans en tant que secrétaire dans un garage automobile.
En juin, elle est allé au rectorat et après 10 mn d'entretien elle est devenu professeure des écoles.
Dans une semaine, elle aura une classe dans une ecole avec un poste réservé aux contractuels (c'est à dire des écoles pas trop difficiles, qui sont du coup retirées et bloquées pour les profs titulaires).
Elle aura 4 jours de formation cette semaine.
Le rectorat leur demande de ne pas spécifier aux parents qu'ils ne sont pas titulaires.
1 prof sur 10 est un prof contractuel.
Y'en a sûrement de très bon.
Ma voisine est sympa.
Mais qui peut croire qu'un recrutement massif de la sorte, et une formation inexistante ne puisse pas avoir un effet délétère sur la scolarité de vos enfants ?
⚡️ CARTE: toward table foundation models⚡️
https://t.co/8bfcc5cNOc
Why foundation models for tables are hard, and why we have made significant headway with “CARTE”
Published at #ICML2024
🧵 1/7
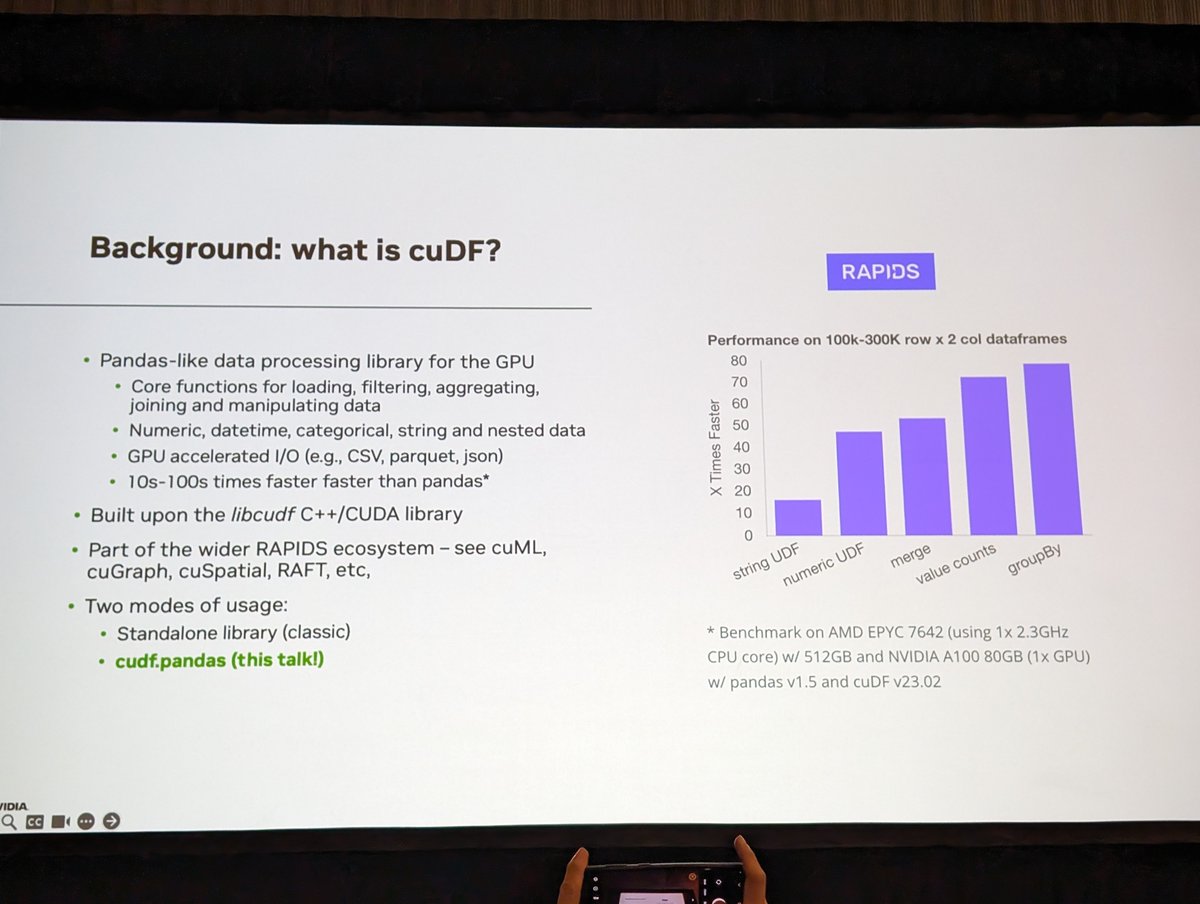
I enjoyed the talk "Accelerating Pandas with Zero Code Change using RAPIDS cuDF" at #GTC2024.
One of Pandas' major drawbacks is its lack of a "query engine," which leads to eager execution of all operations. More modern tools like Polars and DuckDB are designed around a query engine, resulting in significantly faster performance for tasks such as grouping.
By simply using cuDF, you can transform slow Pandas code into fast code, often achieving a 2-10x improvement over Polars and DuckDB.
People often ask me which tool they should use, and the answer is usually more complex than a single sentence.
If you're looking to boost the speed of your Pandas code today, cuDF is the simplest way to achieve significant performance gains without having to rewrite ANY of your code.