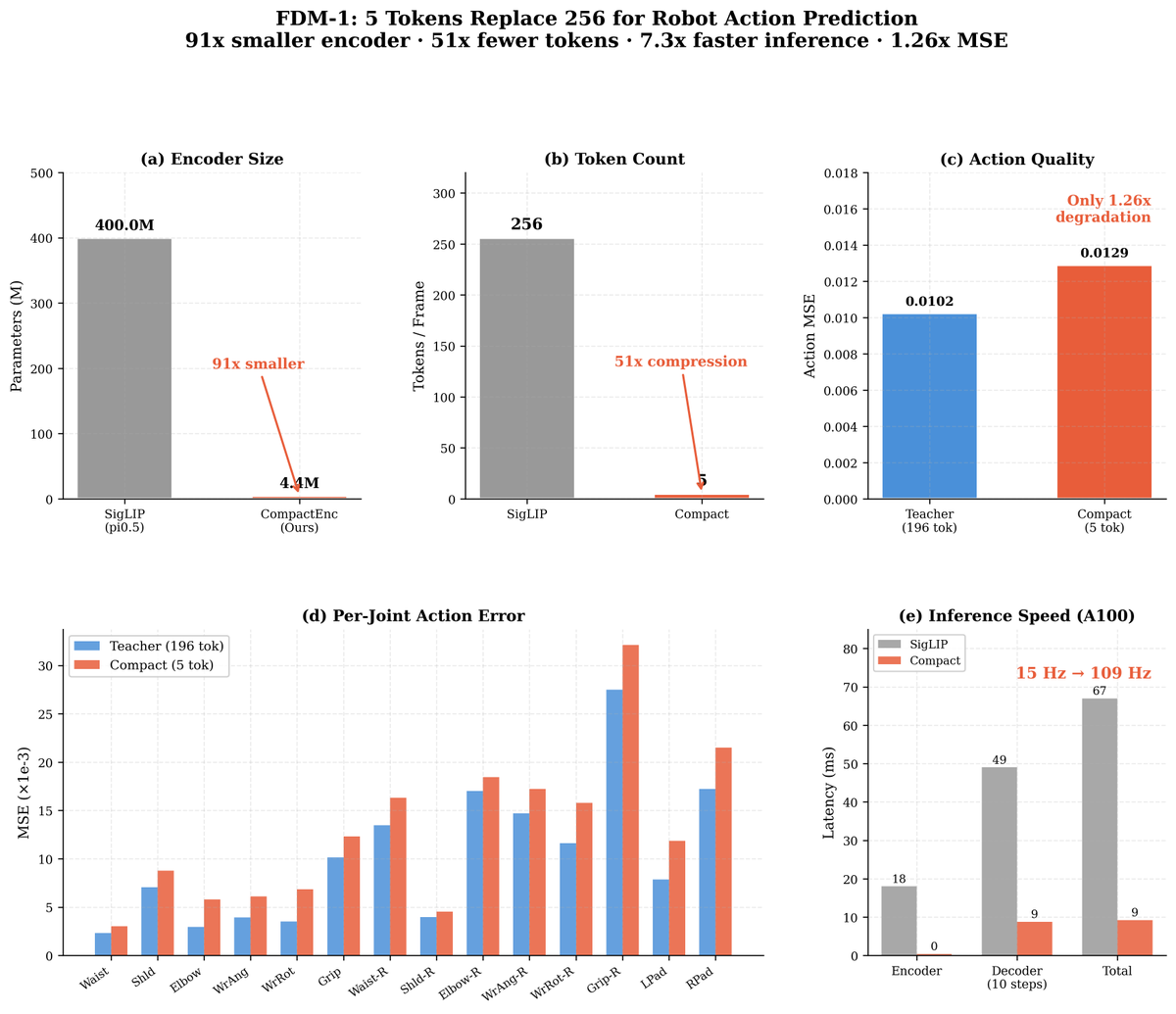
Robot action models shouldn't need 256 vision tokens per frame.
Pi0.5 spends 400M parameters on SigLIP just to see. We replaced it with a 4.4M encoder that
outputs 5 tokens — and action quality barely changes.
91x smaller. 51x fewer tokens. 7.3x faster inference.
@sean_pixel@interlatent@allen_ai We got the same model fully optimized on our inference engine. Running at less than 95ms full e2e with MolmoAct2-Think. Running anywhere in the US.
We just labelled 1 million hours of visual data with a VLM at 40% the cost of other open source. If any data factory shops are interested we can get started fast
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
Wealthsimple just launched a USD chequing account that works on both sides of the border. One account, two currencies, no conversion racket. Canadian banks had years to build this. They built fees instead. Now Wealthsimple has it. Good luck.
Meet @quantbagel.
We technologically altered his perception and recall of dreams.
He was a participant in our placebo/sham controlled study.
User interview #3
becoming a scholar was undoubtedly the best thing that happened to me in college
if you've ever had the desire to venture into startups, you'd be doing yourself a disservice by not applying :)
LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).
turbopuffer crossed $100M run-rate in March. 19mo after $1M. Profitable & <$1M raised.
Cursor・Anthropic・Notion・Cognition・Harvey・Bridgewater・Ramp・Linear・Legora・Superhuman・Atlassian・Granola
We’d be nowhere without them. We work like hell to exceed their expectations.
these types of properties are gonna look insanely underpriced in a few years when everything is all about drone delivery, EVTOLs, autonomous airport pickup and dropoff, starlink, robotic/AI farm equipment and civil unrest keeps rising in cities
Reflex is actively hiring world-class engineers/kernelDevs for robot inference, even if you have zero prior experience in physical AI. Smart humans figure it out fast.
Please send ~3 bullet points demonstrating evidence of exceptional ability
Reflex is actively hiring world-class engineers/kernelDevs for robot inference, even if you have zero prior experience in physical AI. Smart humans figure it out fast.
Please send ~3 bullet points demonstrating evidence of exceptional ability