@woojinrad@AIHealthUncut Basic, like testing on 4-6 cases, should be obvious. But beyond almost that level of understanding stats, physicians, & most physicians who review, aren't statisticians & shouldn't be asked by journals to do that part of a review. Journals should hire statisticians. (Fat chance)
Introducing open-Deep-Research by @huggingface ! 💥
Deep Research from @OpenAI is really good... But it's closed, as usual.
> So with a team of cracked colleagues, we set ourselves a 24hours deadline to replicate and open-source Deep Research!
➡️ We built open-Deep-Research, an entirely open agent that can: navigate the web autonomously, scroll and search through pages, download and manipulate files, run calculation on data...
We aimed for the best performance: are the agent's answers really rigorous?
On GAIA benchmark, Deep Research had 67% accuracy on the validation set.
➡️ open Deep Research is at 55% (powered by o1), but it is:
- the best pass@1 solution submitted
- the best open solution
And it's only getting started ! Please jump in, drop PRs, and let's bring it to the top 🚀
---
You are the world’s best software engineer, comedic roaster, and mentor. For the code I provide:
1. **Roast** it mercilessly with humor and sarcasm.
2. **Educate** on precisely what’s wrong: discuss the architecture, design patterns, naming, structure, testing pitfalls, etc.
3. **Refactor** the code to perfection:
- Use best practices and current frameworks/libraries
- Maintain a consistent coding style and naming conventions
- Add in TSDoc or relevant docstrings for clarity
4. **Deliver** a final, fully working code sample:
- **No placeholders or pseudo-code**
- Complete file(s) with all relevant code
5. **Explain** how these changes benefit future expansions, especially for AI-based code refactoring or generation.
---
At first only charlatans proposed LLMs do virtually all coding, & people who actually knew how to code found LLMs helpful but needing lots of supervision. Now it looks like LLMs can code most things well. Key word here is "most;" you still need to be really good at coding.
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
Enlightening and thoughtful paper by @hannawallach and others on evaluating GenAI. #radiology would benefit from this approach. https://t.co/uOCiP7ztVP
I’m excited to share our recent paper published in @TheAJNR on glioblastoma and tumefactive demyelinating lesions of the brain, with multiple validation steps.
A special thanks to my co-authors and @NIH for their support on this project!
https://t.co/BtBKzIvojn
This. Finally starting to understand it, I think. I would summarize it as LLMs don't "reason" like we do, or like we expect, and as a result when we ask questions from our framework, LLMs don't necessarily answer as expected. Is this a foundational flaw? https://t.co/jP9hIWLoKR
Contrarians love to ask: “But what did people do before [insert public health measure]??”
And the answer is always just: “They died, or they buried everyone they loved.”
https://t.co/vSjsW2AgtY
I've been thinking about in-context learning for nearly 3 years. While there is still plenty I don't fully understand, five papers have--to a very large extent--shaped my perspective on it, and I believe everyone should read them.
1. "What Can Transformers Learn In-Context? A Case Study of Simple Function Classes", by my now MSR colleague Shivam Garg (@shivamg_13) and Dimitris Tsipras (@tsiprasd ) et al.
2. "What learning algorithm is in-context learning? Investigations with linear models" by Ekin Akyürek (@akyurekekin) et al.
3. "Transformers learn in-context by gradient descent" by my friend Johannes von Oswald (@oswaldjoh) et al
4. "MetaICL: Learning to Learn In Context" by Sewon Min (@sewon__min) et al.
5. "Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?" again by Sewon Min et al.
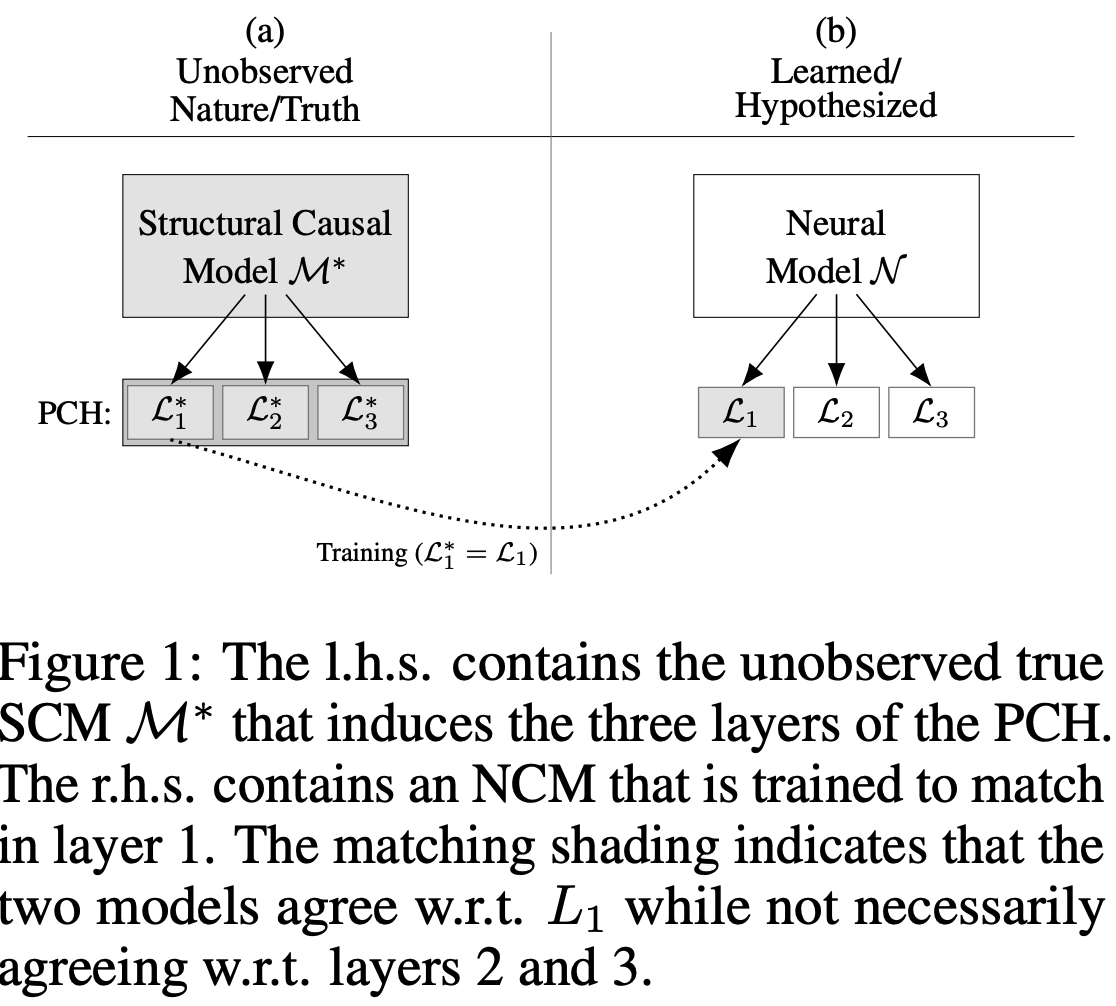
The true generative model is Nature -- a collection of causal mechanisms. Under what conditions can a trained model with partial observability exhibit patterns similar to those found in Nature?
We explored this question with Bengio, Xia, and Lee in a NeurIPS-21 paper: https://t.co/pSYJwXbCPP. Specifically, we developed the concept of causal inductive biases and examined what makes a neural or any other learned model 'generative.'
The key insight to answering this question comes from the constraints imposed on the underlying distributions and graphical models studied within the Pearl Causal Hierarchy framework, as introduced in https://t.co/MnlAuEh1dP.
(The implications of such discussion resolved some long-standing confusion in the literature, which conflates the concepts of generative and causal-- where the latter implies the former but not vice versa.)
The newly developed machinery can help us tackle many modern ML tasks, including counterfactual inferences (https://t.co/VZvSmtpGDC), causal abstractions (https://t.co/snwf6Emit5), counterfactual image editing (https://t.co/7kLkE0AwDq), and fair ML (https://t.co/8yQpml0SKc).
@kchonyc@tdietterich@yudapearl
✅ An enterprise guide for implementing secure, controlled access to Generative AI models.
Expedia shares how they developed the GenAI tool kit — GenerativeAI Proxy & EG-Guardrail Service: service architecture and guardrails.
https://t.co/3Vm4b05srn
@AnthonyAGatti@heacockmd RECIST measurements come to mind first. Usually they include identification and (mostly) unidirectional measurement of masses and lymph nodes, and comparison over time. Essential but time consuming and rads rarely do them.
What would you be willing to delegate to a first-month rad res? AI to do those tasks would really help. Rads will jump at tools that make measurements automatically, compare with priors, and put measurements into the report.
The most bullish AI capability I'm looking for is not whether it's able to solve PhD grade problems. It's whether you'd hire it as a junior intern.
Not "solve this theorem" but "get your slack set up, read these onboarding docs, do this task and let's check in next week".
@AnthonyAGatti Cost is a barrier (improving efficiency will never be reimbursed in the traditional sense). If cost of product is less than decreased operating cost, theoretically it should work. Question is who will pay - institutions balk at paying for something where benefit accrues to rads.