We have many questions about in-context learning for low-resource languages, but we don’t have (well) resources to study them.
What if we used truly low-resource languages that had tons of resources under the hood?
Let’s cipher high-resource languages!
https://t.co/NcEU6GuGBu
Imagine this: It's Friday. You've been deep in a debugging session with your agent for hours. Suddenly it says: "Need to compact context" because it's about to exceed the context window. And with that, it forgets various details about your session.
𝐓𝐡𝐞 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞
As they work, agents' context fills with both useful things and junk (dead-end searches, stale results, superseded plans). That junk impacts everything that follows. Compaction (summarizing the context and resuming from the summary) is the standard fix.
Two questions matter: (1) 𝑤ℎ𝑒𝑛 to compact, and (2) ℎ𝑜𝑤 to compact.
Both matter: a poorly-timed call discards the partial result you still needed.
𝐖𝐡𝐚𝐭 𝐝𝐨 𝐩𝐞𝐨𝐩𝐥𝐞 𝐝𝐨 𝐭𝐨𝐝𝐚𝐲?
Within academia there are a few camps:
1️⃣ Deployed agents compact at a certain token threshold. This is an intuitive starting point: compact if you're about to exceed. But it starts to make less sense once one realizes that this compaction point may appear in the middle of an important task. And there is no agreement on the threshold — triggers range from 30% to 95% of the context window.
2️⃣ Another camp compacts on a fixed interval — every k tokens regardless of trajectory state. This increases the frequency of the compactions, which allows one to use shorter active context (and hence less memory). But again there is no informed logic to when compaction is applied.
3️⃣ Training-based approaches bake the when-to-compact decision into weights via SFT/RL. But with the increasing capabilities of the models, especially with their tool-use capabilities, is training really a necessity?
In industry, various agents have compaction strategies that more or less work. We don't always know how they work. Even in cases that we do, it's unclear how well they do and why.
𝐎𝐮𝐫 𝐩𝐫𝐨𝐩𝐨𝐬𝐚𝐥: 𝐒ᴇʟꜰ𝐂ᴏᴍᴘᴀᴄᴛ
A training-free scaffold pairing two inference-time elements:
(i) 𝐀 𝐜𝐨𝐦𝐩𝐚𝐜𝐭𝐢𝐨𝐧 𝐭𝐨𝐨𝐥. The model emits a summarize signal, the scaffold runs the summarization, and generation resumes from the summarized prefix. This is the ℎ𝑜𝑤.
(ii) 𝐀 𝐫𝐮𝐛𝐫𝐢𝐜 𝐠𝐚𝐭𝐞. At periodic probes, the model returns COMPRESS or CONTINUE. Fire when a sub-task has resolved or the trajectory is converging. Suppress mid-derivation or when stuck. This is the 𝑤ℎ𝑒𝑛.
The same model is generator, judge, and summarizer.
𝐎𝐮𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧𝐬
We evaluate on two task families and 6 datasets: (1) Competition math (IMO-Answerbench, HMMT Nov 25, HMMT Feb 26) and (2) Agentic search (BrowseComp, BrowseComp-Plus, DeepSearchQA).
We also evaluated 7 models: GLM-4.7-Flash, MiniMax-M2.5, MiMo-V2-Flash, Qwen3-4B-Instruct, Qwen3-30B-A3B-Instruct, Qwen3.5-4B, Qwen3.5-9B.
𝐅𝐢𝐧𝐝𝐢𝐧𝐠𝐬
🔹 The pattern of gains is consistent across various evaluations: baseline < fixed-interval ≤ 𝐒ᴇʟꜰ𝐂ᴏᴍᴘᴀᴄᴛ.
🔹 In scenarios where window size is limited, +𝟏𝟖.𝟏 𝐩𝐨𝐢𝐧𝐭𝐬 over no-compaction.
🔹 Even if there is no limit on context window, 𝐒ᴇʟꜰ𝐂ᴏᴍᴘᴀᴄᴛ is still helpful. It is the strongest method on all three models: +𝟓–𝟗 𝐩𝐨𝐢𝐧𝐭𝐬 over no-compaction, at 𝟑𝟎–𝟕𝟎% 𝐥𝐨𝐰𝐞𝐫 𝐩𝐞𝐫-𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧 𝐜𝐨𝐬𝐭.
🔹 In our analysis, we find that 𝐒ᴇʟꜰ𝐂ᴏᴍᴘᴀᴄᴛ fires earlier than the fixed-threshold baseline.
🔹 We also observed that 𝐒ᴇʟꜰ𝐂ᴏᴍᴘᴀᴄᴛ helps most on the hardest questions, where deep search accumulates the largest contexts. On easy questions, all three policies are within noise.
——
💡 𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲:
💡 "When to compact" is a meta-cognitive capability a lightweight rubric can supply at inference time .
💡 Across 6 benchmarks and 7 models: 𝐒ᴇʟꜰ𝐂ᴏᴍᴘᴀᴄᴛ matches or exceeds fixed-interval summarization at 30–70% lower cost.
💡 To our knowledge, this is the first work to introduce and evaluate rubric-based adaptive compaction timing in a training-free setting.
🚨 New paper: "Self-Compacting Language Model Agents"
LM agents build up long traces of reasoning and tool calls. As the trace grows, old mistakes and stale info stick around and anchor everything that follows. We ask: can the model itself decide when to clean up?
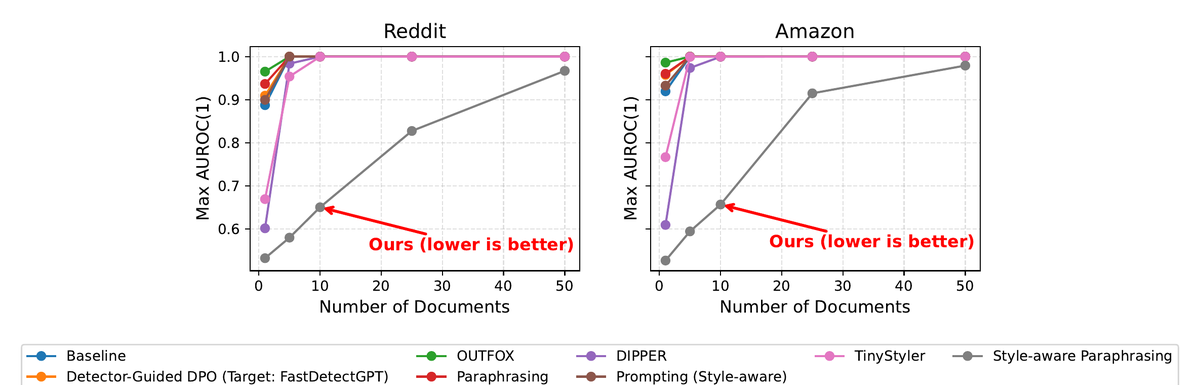
@max_spero_ Thanks for the suggestion! Turns out we have a Pangram API key available. Our attack takes AUROC from 0.903 to 0.504. Pushed up the code and results here: https://t.co/2qVcPDFCnQ
New #ICML2026 paper!
A popular claim says machine-text detection is hopeless since detectors get defeated by cheap attacks (paraphrasing, prompting, DPO). We show the picture is more subtle. 👇
📄 https://t.co/yLCOaMwxNr
💻 https://t.co/F33JaFQVFK
Can coding agents actually reproduce scientific findings — not just write code, but rerun the science?
We built AutoMat to find out. 🧪🤖
AutoMat is a benchmark of 85 expert-curated reproduction tasks from computational materials science.
Work w/ Barry Chen from LLNL & Nicholas Andrews from Johns Hopkins!
📄 Paper: https://t.co/yLCOaMwxNr
💻 Code + data + checkpoints: https://t.co/F33JaFQVFK
Catch us at #ICML2026! 🇰🇷
But evasion isn't absolute. 🪤
On a single document, our attack evades detectors. But as you aggregate multiple documents, the human and machine distributions pull apart again.
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
Fast Byte Latent Transformer is accepted to ICML 2026! ⚡🥪
Byte-level LMs promise to free us from subword tokenizers, but decoding one byte at a time is super slow.
We make BLT generation more efficient with BLT-D: text diffusion for parallel byte decoding. 1/
Huge congrats to David Mueller @dam_nlp (Nick Andrews co-advised) on successfully defending his thesis "Towards Understanding Conflict & Transfer in Multi-Task Deep Learning"! 🎓🥳
David is now an applied scientist at @amazon. 🚀💻
Thanks committee member Kevin Duh! 🙏✨
Flow Matching (FM) is one of the hottest ideas in generative AI - and it’s everywhere at #ICML2025.
But what is it? And why is it so elegant? 🤔
This thread is an animated, intuitive intro into (Variational) Flow Matching - no dense math required.
Let's dive in! 🧵👇
The (true) story of development and inspiration behind the "attention" operator, the one in "Attention is All you Need" that introduced the Transformer. From personal email correspondence with the author @DBahdanau ~2 years ago, published here and now (with permission) following some fake news about how it was developed that circulated here over the last few days.
Attention is a brilliant (data-dependent) weighted average operation. It is a form of global pooling, a reduction, communication. It is a way to aggregate relevant information from multiple nodes (tokens, image patches, or etc.). It is expressive, powerful, has plenty of parallelism, and is efficiently optimizable. Even the Multilayer Perceptron (MLP) can actually be almost re-written as Attention over data-indepedent weights (1st layer weights are the queries, 2nd layer weights are the values, the keys are just input, and softmax becomes elementwise, deleting the normalization). TLDR Attention is awesome and a *major* unlock in neural network architecture design.
It's always been a little surprising to me that the paper "Attention is All You Need" gets ~100X more err ... attention... than the paper that actually introduced Attention ~3 years earlier, by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio: "Neural Machine Translation by Jointly Learning to Align and Translate". As the name suggests, the core contribution of the Attention is All You Need paper that introduced the Transformer neural net is deleting everything *except* Attention, and basically just stacking it in a ResNet with MLPs (which can also be seen as ~attention per the above). But I do think the Transformer paper stands on its own because it adds many additional amazing ideas bundled up all together at once - positional encodings, scaled attention, multi-headed attention, the isotropic simple design, etc. And the Transformer has imo stuck around basically in its 2017 form to this day ~7 years later, with relatively few and minor modifications, maybe with the exception better positional encoding schemes (RoPE and friends).
Anyway, pasting the full email below, which also hints at why this operation is called "attention" in the first place - it comes from attending to words of a source sentence while emitting the words of the translation in a sequential manner, and was introduced as a term late in the process by Yoshua Bengio in place of RNNSearch (thank god? :D). It's also interesting that the design was inspired by a human cognitive process/strategy, of attending back and forth over some data sequentially. Lastly the story is quite interesting from the perspective of nature of progress, with similar ideas and formulations "in the air", with a particular mentions to the work of Alex Graves (NMT) and Jason Weston (Memory Networks) around that time.
Thank you for the story @DBahdanau !
The original RL algorithms, inspired by natural learning, were online and incremental—they were streaming in the sense that they learned from each increment of experience as it happened, then discarded it, never to be processed again. The streaming algorithms were simple and elegant, but the first big successes of RL in deep learning were not with streaming algorithms. Instead, methods such as DQN chopped the stream of experience into individual transitions, then stored and sampled them in arbitrary batches. Subsequent work followed, extended, and refined the batch approach into asynchronous and offline RL, while the streaming approach languished, unable to produce good results in popular deep learning domains.
Until now. Now researchers at the University of Alberta have shown that streaming RL algorithms can work just as well as DQN on Atari and Mujoco tasks (https://t.co/S4D6lSvdxz). How did they do it? Mostly just by getting signal normalization and step-size bounding right for the streaming case—otherwise they use standard streaming algorithms like TD(lambda) and Q(lambda). To me it looks like they were simply the first researchers knowledgeable of streaming RL algorithms to seriously address deep RL without being over-influenced by batch-oriented software and batch-oriented supervised-learning ways of thinking.
On the fallacy of "If it ain't strictly retrieval, it must be reasoning" argument.. #SundayHarangue (on Wednesday)
There is a tendency among some LLM researchers to claim that LLMs must be somehow capable of doing some sort of reasoning since they are after all not doing the vanilla retrieval.
This harks back to Sam Altman's famous "For some definition of reasoning, LLMs do some kind of reasoning" dictum (c.f. https://t.co/3lEi1N5tXP).
There are obvious problems with this stance.
To begin with, no one ever said that LLMs just do retrieval (in fact, having been trained to be a type of n-gram models, they can't actually do exact retrieval by default!).
Anyone who ever played with LLMs from GPT3 on know that their appeal is that they don't do exact retrieval.
They do some generative version of retrieval that I have called "approximate retrieval" (and tried to pin it down a bit more firmly here: https://t.co/qMJxiOCeRa).
If you visualize retrieval and reasoning as two points on a linear spectrum, approximate retrieval is different both from retrieval and reasoning.
It is crucial to note that it differs from both retrieval and reasoning. The fact that it is different from retrieval can't thus be used as some kind of proof that it must be doing reasoning! . The fortuitous intersection between approximate retrieval and reasoning is so uneven as to lead to popularization of phrases like jagged intelligence (https://t.co/yu92679hXA)
Indeed the implicit hypothesis that mere scale-up of autoregressive LLMs will magically convert their approximate retrieval to (sound) reasoning has been tested with considerable expense from GPT3 on--and has so far not yielded any fruit. If anything, more studies have established the limitations of autoregressive LLMs in reasoning tasks (I guess we were just doing it way before it was cool https://t.co/ftKyGsAFl4 😄)
This is becoming common-enough knowledge now that major vendors are slowly shifting to adding actual reasoning components on top of autoregressive LLMs--despite the stone soup ironies some of those approaches (see https://t.co/tKWJEWmoSt).
tldr; you can't claim that LLMs must be doing reasoning just because they are not doing retrieval--the law of excluded middle doesn't quite apply!
If you want to do a better/more formal characterization of their approximate retrieval--that would be a great research direction.